Implementing fault-tolerance mechanisms is complex.
Transactions have been the mechanism of choice for simplifying these issues by grouping reads and writes into a logical unit. If all reads and writes succeed, the corresponding operation is committed. If any one fails, the operation is aborted.
Transactions are created to simplify the programming model for applications accessing a database and helps the application to ignore potential error scenarios and concurrency issues (safety guarantees). But not every use case requires transactions and some safety properties can be achieved without transactions.
The Slippery Concept of a Transaction
Transactions has it’s own advantages and disadvantages. It’s not as simple as transactions prevent good performance or high availability, or transaction guarantees are required for serious applications.
The Meaning of ACID
The safety guarantees provided by transactions are often described by the well known acronym ACID, which stands for Atomicity, Consistency, Isolation, and Durability.
Systems that do not meet ACID criteria are sometimes called BASE, Basically Available, Soft state, and Eventual consistency
ACID:
- Atomicity - If any of the operations grouped together in a transaction fails, the whole transaction is aborted.
- Consistency - in ACID, consistency means that certain statements about the data (invariants) must always be true.
- In a bank account, no additional credits or debits are added outside of the users. System can’t magically accidentally add money.
- Consistency is a property of the application to hold the invariants, so it doesn’t really belong in ACID
- Isolation - concurrently executing transactions are isolated from each other.
- Textbook idea is have a serialized order to transactions, but not really possible in practice
- In practice, snapshot isolation is typically implemented which is a weaker guarantee than serializability.
- Durability - provide a safe place where data can be stored without fear of losing it. Promise that once a transaction has committed successfully, any data it has written will not be forgotten.
Single-Object and Multi-Object Operations
Database systems aim to provide atomicity and isolation on the level of a single object for simplicity.
Multi-object transactions are often needed if several pieces of data need to be kept in sync.
- E.g. Maintaining an unread counter with every new message in an email system.
Multi-object transactions can surface in scenario where very high availability or performance is required
- E.g.
- one write would write to many replicas.
- Relational data model - maintaining foreign key references
- Document data model - updating denormalized data
- Secondary indexes
Handling Errors and Aborts
A key feature of transactions is that it can be aborted and safely retired if an error occurs.
Retrying an aborted transaction:
- Failed ACK, potential dedup
- Overload and dropping, need exp. backoff
- Transient errors, worth retrying; permanent error, stop trying.
Weak Isolation Levels
If two transactions don’t touch the same data, they can safely be run in parallel, because neither depends on the other.
Concurrency bugs are hard to find by testing and difficult to reason about. Thus, databases attempt to hid concurrency from application developers by providing transaction isolation.
In practice, isolation is complex. Serializable isolation has a performance cost and not worth it for many databases. It’s much more common for databases to use weaker levels of isolation that protect against some concurrency issues. Below are the several weaker isolation levels used in practice.
Read Committed
The most basic level of transaction is read committed. It makes two guarantees:
- When reading from the database, you will only see data that has been committed (no dirty reads)
- When writing to the database, you will only overwrite data that has been committed (no dirty writes)
No dirty reads Dirty read - reading written data from a transaction that has not been fully committed or aborted.
- Databases prevent dirty reads by simply giving the old value prior to commit. Related context on why reads and locks don’t mix: RCU Usage In the Linux Kernel - Eighteen Years Later
No dirty writes Dirty write - overwriting an uncommitted write in an ongoing transaction.
- Databases prevents dirty writes using row-level locks
Read committed is popular and the default setting in PostgreSQL, Oracle 11g, and many others.
What it does:
- Allows aborts
- Prevents reading the incomplete results
- Prevents concurrent writes from getting intermingled
Snapshot Isolation and Repeatable Read
Stronger guarantee than read committed and tackles the issue of nonrepeatable reads or read skew.
Nonrepeatable reads or read skew is when updates between objects left in an inconsistent state and the user reads the inconsistent state.
- This is due to read committed allowing the user to be able to read stale data to avoid dirty reads and lock usage on reads.
- May not be a problem if eventual consistency is the level of consistency required.
- TBH repeatable reads definition is a mixed bag, check context (i.e. which database) to decide on definition
This is an issue for:
- Backups - snapshot need to be in a consistent state
- Analytic queries and integrity checks - can’t have returns of nonsensical results
Snapshot Isolation solves this by guaranteeing that every transaction reads from a consistent snapshot of the database. The transaction sees all the data that was committed in the database at the start of the transaction. Even if the data is subsequently changed by another transaction, each transaction sees only the old data from that particular point in time.
- Useful for long-running, read-only queries such as backups and analytics
- When a transaction can see a consistent snapshot of the database, frozen at a particular point in time, it is much easier to understand.
Implementation
- Write locks to prevent dirty write
- Readers never block writers, and writes never block readers so reads don’t require any locks which allow for long-running read queries on a consistent snapshot at the same time as processing writes. (similar to read committed)
- To maintain consistency, the database must keep several different committed versions of an object, because various in-progress transactions may need to see the state of the database at different points in time. This is known as multi-version concurrency control (MVCC).
- For read committed, only two versions of the object needs to be kept (old-committed, new-uncommitted)
The differences between snapshot isolation and read committed.
- For snapshot isolation, each query uses the same snapshot for an entire transaction.
- For read committed, separate snapshots per query are okay.
Visibility Rules for Consistency
- Start of each transaction, database makes a list of all in-progress transactions. Any writes from that list are ignored, even if they commit.
- Any writes made by aborted transactions are ignored.
- Any writes made by transactions with later transaction ID are ignored even if committed
- All other writes are visible to the application’s queries.
Indexes and Snapshot Isolation
Multiple implementations of indexes in multi-version database:
- Have index point to all versions of an object and add an index query to filter out any object versions that are not visible to current transaction.
- Append-only/copy-on-write variant that does not overwrite pages of the tree when they are updated, but instead creates a new copy of each modified page.
- Requires a background process for compaction and garbage collection of old copies
Repeatable Read and Naming Confusion
Many databases that implement snapshot isolation call it with different names. In Oracle it’s called serializable and in PostgreSQL and MySQL it is called repeatable read.
Preventing Lost Updates
The two isolation levels, read committed and snapshot isolation target guarantees of read-only transactions. What about multiple transactions writing concurrently?
There are multiple write-write conflicts that can occur:
- Dirty writes - overwriting another transactions non-committed change.
- Lost updates - not all updates to a database are committed.
- Consider an application that reads some value from the database, modifies it, and writes back modified value (read-modify-write cycle).
- If two transactions do this concurrently, one of the modifications can be lost, because the second write does not include the first modification
Solutions:
- Atomic write operations - acquire exclusive lock on the object and hold until update has been applied
- Explicit locking - application explicitly lock objects that are going to be updated.
- Automatically detecting lost updates - allow read-modify-write cycles to happen in parallel. Include a layer that detects a lost update and aborts the transaction.
- Compare-and-set - avoid lost updates by allowing an update to happen only if the value has not changed since you last read it. If value has changed (parallel read-modify-write cycles), then retry
- Conflict resolution and replication - allow concurrent writes to create several conflicting versions of a value (also known as siblings) and use the application code or special data structures to resolve and merge these versions after the fact
- Locks and compare-and-set assumes a single up-to-date copy of the data. In multi-leader or leaderless replication, there may be multiple up-to-date copies.
- Check out handling write conflicts for conflict resolution methods
Write Skew and Phantoms
Write Skew
Write skew - when two concurrent writes to two different object breaks invariants expected to be held.
- Neither dirty write or a lost update because two transactions are updating two different objects.
- Say two concurrent writes and only one is supposed to go through. Each checks if a write has gone through and both sees that none has gone through. Thus, both writes occur.
- Basically when a write is determined by an external shared state with some constraint (invariant). Every Annota problem lol.
Consider:
- Atomic single-object operations don’t help, multiple objects
- Snapshot isolation? Write skew is not automatically detected, requires true serializable isolation.
- Two different objects change through two different writes, hard to say if they should be within the same state or not.
Solutions:
- Serializable isolation level.
- Lock all the rows that the transaction depends on, increase granularity of lock.
Phantom
Phantom - when a write in one transaction changes the result of a search query in another transaction.
- Snapshot isolation avoids phantoms in read-only queries
- In read-write transactions, phantoms can lead to write skew.
Materializing conflicts
Consider that the issues of phantoms is that the shared state isn’t an object that we can attach a lock to. What if we created a lock object in the database for that?
- For the two writes problem in the write skew, we can create a counter that tracks writes and is held during a write transaction. If the lock is not held, a write cannot start. (Rather than checking every writable object if a write has occurred)
- Another example is their meeting rooms example of creating time slots to lock, rather than a custom time.
Materializing conflicts - take a phantom and turns it into a lock conflict on a concrete set of rows that exist in the database. Pretty error prone and hard to identify so it should be a last resort.
- A serializable isolation level is much preferable in most cases
Serializability
Serializable isolation is usually regarded as the strongest isolation level. It guarantees that even through transactions may execute in parallel, the end result is the same as if they had executed one at a time, serially. Here are different ways on how serializable isolation is implemented.
Actual Serial Execution
Remove concurrency and execute one transaction at a time, in serial order, and on a single thread. It’s limited by the compute power of the single thread.
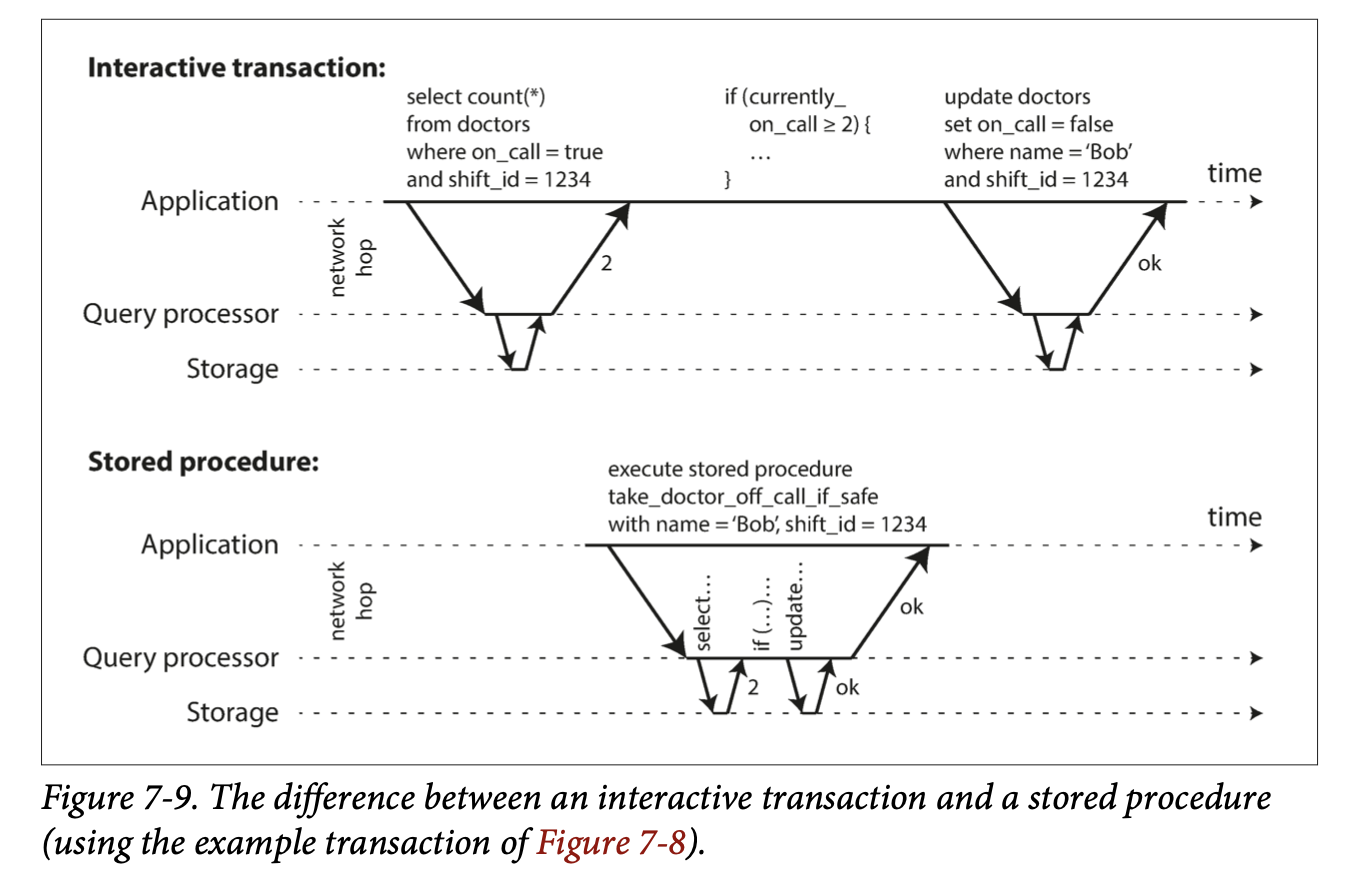
Encapsulating transactions in stored procedures
Stored procedure - an application submits entire transaction code to the database ahead of time. Database runs code to check if transaction should run.
| Pros | Cons |
|---|---|
| Modern stored procedures use existing general-purpose programming languages | Each DB vendor has its won language for stored procedures, not portable |
| With stored procedures and in-memory data, executing all transactions on a single thread is feasible, no I/O wait (on DB) | Code running in a database is difficult to manage (version control, testing, deployment) |
| A database is often much more performance-sensitive than application server |
Partitioning
We can partition our data so that each transaction only need to R/W data within a single partition, thus acting like a single thread. If transactions don’t cross partitions, there isn’t any conflicts.
If cross-partition transactions are required, an additional coordination overhead is required.
Summary of serial execution
Serial execution constraints:
- Every transaction must be small and fast, one slow transaction can cause head of line blocking
- Limited to use cases where the active dataset can fit in memory. Disk slows down speed and leads to above point.
- Write throughput must be low enough to be handled on a single CPU core, no coordination
- Cross-partition transaction are possible, limited by speed.
Two-Phase Locking (2PL)
Not to be confused with Two Phase Commit.
Two-phase locking (2PL) is an algorithm used for serializability in databases.
Locks are often used to prevent dirty writes or to prevent two transactions from concurrently writing to the same object.
Two-phase locking is similar, but with stronger lock requirements.
- Several transactions are allowed to concurrently read the same object as long as nobody is writing to it
- As soon as anyone wants to write (modify or delete) an object, exclusive access is required.
This leads to new outcomes under 2PL:
- Reading an old version of an object is not acceptable (every read is latest)
- Writes only happens if there are no readers on the object (readers block writers and vice versa) Ultimately, this protects against all race conditions and provides serializability.
Implementation of two-phase locking
The blocking of readers and writers is implemented by having a lock on each object in the database. Each lock has two states: shared mode or exclusive mode (similar to MOESI for cache snooping to increase performance).
Lock usage:
- Transaction read → acquire lock in shared mode. If lock in exclusive mode, read is blocked (multiple readers)
- Transaction write → acquire lock in exclusive mode
- Transaction read then write → lock moves from shared to exclusive
- Transaction must hold lock until end of transaction.
- “Two-phase” - first phase is while transaction is executing or lock acquire. Second phase is at the end of transaction or lock release
Deadlocks may happen in which case the database aborts one transaction to stop the deadlock.
Performance of two-phase locking
Reduced concurrency due to locks. If there is contention in the workload, it can result in a queue of transactions and lead to head of line blocking.
Aborted deadlock transaction need to be retried, resulting in extra work.
Thus, 2PL is not typically used in practice.
Predicate locks
What about phantoms, how does 2PL solve them? One way is predicate locks.
Predicate locks belong to all objects that match a search condition rather than one particular object. In a sense it locks the phantom.
Index-range locks
Predicate locks do not perform well because searching for the correct predicate lock is time-consuming. Most databases with 2PL actually implement index-range locking or next-key locking.
Index-range locks is pretty much it’s name where to simplify a predicate, we match it to a greater set of objects that’s under an index/range.
- The approximation is the simplification, but does creates a bigger area of contention.
- Another benefit is lowered overhead to search for a lock compared to predicate locks.
Serializable Snapshot Isolation (SSI)
Current tradeoffs:
- Serial implementations
- Serial execution - serial, but can’t scale (single thread)
- Two-phase locking - serial, but bad performance due to locks
- Weaker isolation levels
- Better performance, but issues with:
Is there a way for serializable isolation and good performance to co-exist? Maybe serializable snapshot isolation
- Provides full serializability with small performance penalty compared to snapshot isolation
Pessimistic vs Optimistic Concurrency Control
One of the big ideas that serializable snapshot isolation leans on is pessimistic vs optimistic concurrency control.
Two-phase locking = pessimistic currency control
- If anything might possibly go wrong (e.g. acquiring a held lock), it’s better to wait until it’s safe before doing anything. Serializable snapshot isolation = optimistic concurrency control
- Instead of blocking/waiting, transactions continue anyway, in hopes that everything will work out. When a transaction wants to commit, a check runs to see if there’s any violations and if so aborts.
Detecting Stale MVCC Reads
A core issue of concurrent transactions is write skew and phantoms. Write skews are cause by reading stale data and taking action based off of stale data. The stale data is called a premise or a fact that was true in the beginning of a transaction.
We need to be able to detect when a premise is outdated and abort the transaction in that case.
Snapshot isolation is typically implemented with MVCC. Thus, the database needs to track when a transaction ignores another transaction’s writes due to MVCC visibility rules. Before committing, if any of the ignored writes have been committed during that time, the transaction must be aborted because it may have utilized an incorrect write value.
Detecting Writes That Affect Prior Reads
The second case to consider is when another transaction modifies data after it has been read. Rather than having a lock on write which blocks. We can introduce a tag that marks the data as dirty and any other transactions whose reads depends on dirty data should be aborted.
Example below shows how transaction 43 removing a doctor off on call should be aborted because transaction 42 has modified the value. This renders the read in transaction 43 as invalid and whole transaction should be aborted. 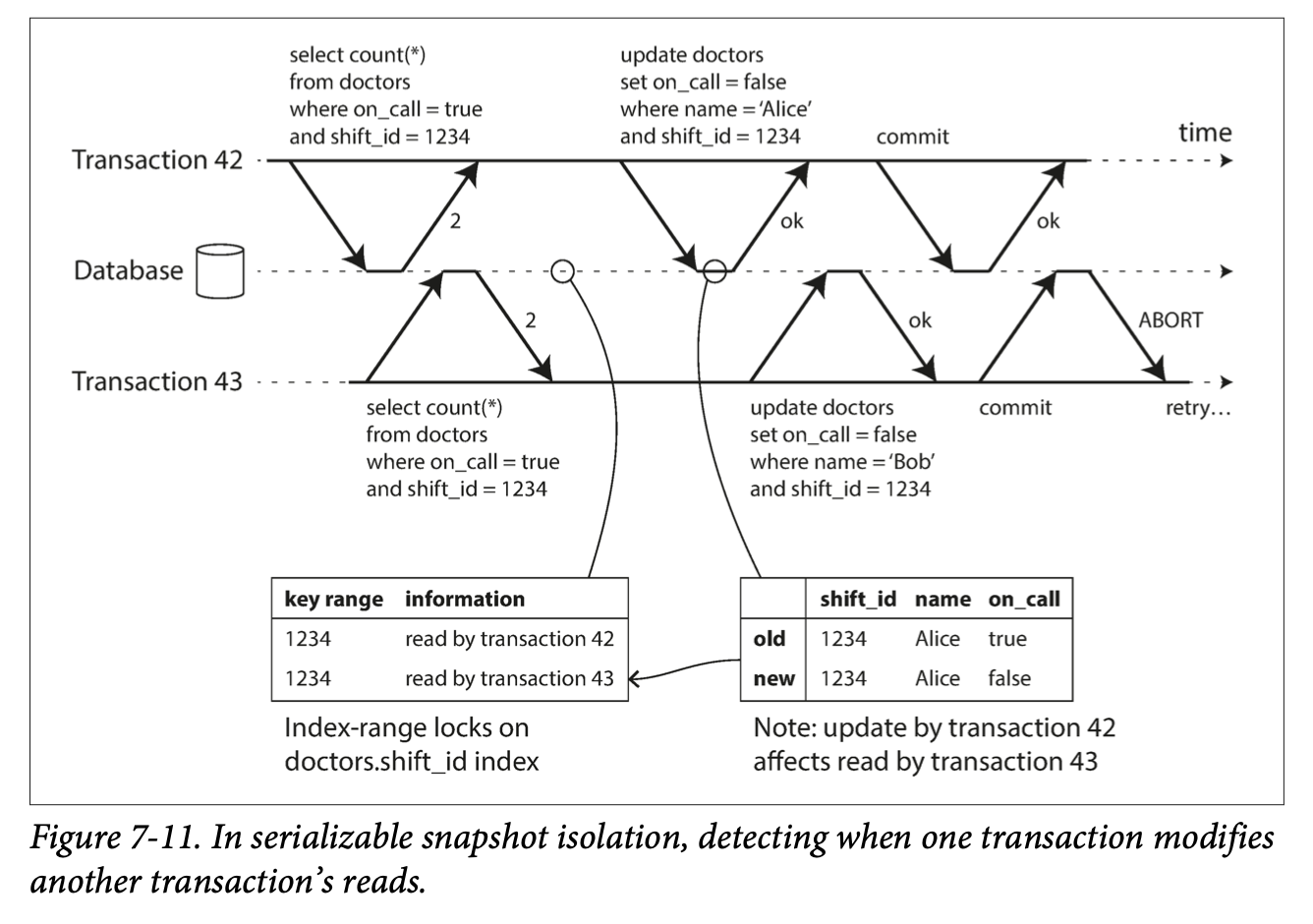
Performance of Serializable Snapshot Isolation
- Requires writes and reads to be tracked
- More detail = less aborts but higher space cost
- Non-blocking, writers don’t block readers and vice versa
- Snapshot isolation is not limited to throughput of a single CPU core
- New issue is now rate of aborts
Summary
Transactions - abstraction layer that allows an application to pretend that certain concurrency, hardware, and software problems do not exist. A large class of errors is reduced to a transaction abort where the application needs to retry the transaction.
Isolation levels from weakest to strongest guarantees:
- Read committed
- Snapshot isolation (repeatable read)
- Serializable
Data race conditions:
- Dirty reads - One client reads another client’s writes before they have been committed.
- Dirty writes - One client overwrites data another client has written but not yet committed.
- Read skew (nonrepeatable reads) - client reads sees different database states at different time, due to latency or consistency.
- Lost updates - Two or more transactions writing to the same object concurrently, resulting in only latest object committing causing lost data.
- Write skew - Transaction consisting of read/write where write depends on read.
- Phantom reads - reads that match some search condition
Weak isolation levels protects against some of those data race conditions. Relies on the application to handle the outcomes. There are three different approaches to implement serializable transactions:
- Literally executing transactions in serial order
- Two-phase locking
- Serializable snapshot isolation (SSI)