Replication - copying the same data on multiple machines that are connected via a network.
- Keep data geographically close to your users (reduce latency)
- Allow the system to continue working even if some of its parts have failed (increase availability)
- Scale out the number of machines that can serve read queries (increase read throughput)
Leaders and Followers
Replica - a node in distributed storage that stores a copy of the database
To maintain consistency, every write to the database needs to be processed by every replica. The most common solution is leader-based replication
Framework:
- One of the replicas is designated as the leader. Leader intercepts requests and writes new data to local storage
- Other replicas are known as followers. When the leader writes new data to its local storage, it broadcasts its change to its followers as part of a replication log or change stream. Each follower takes the log from the leader and updates its local copy of the database accordingly, by applying all writes in the same order as they were processed on the leader.
- Client reads can query either the leader or the followers. Writes are only accepted on the leaders. Followers are read-only
Synchronous Versus Asynchronous Replication
Replication can happen synchronously or asynchronously.
Synchronous replication causes blocking issues on faults or slowdown but provides a guarantee that the data is up-to-date. Asynchronous replication has the reverse effect and doesn’t block the system. To have the best of both worlds, some systems are setup as semi-synchronous where one of the followers is synchronous and the rest are asynchronous. If the synchronous follower is down or slow, another asynchronous follower is chosen to be the new synchronous follower.
Often though, leader-based replication is completely asynchronous. This means that writes are not guaranteed to be durable (when leader fails). But this means the leader can continuing processing writes even if the followers are behind (throughput increase).
Setting Up New Followers
Data is in flux, so direct copy into new follower is impossible. Need to copy from a snapshot in time. Process:
- Take snapshot of leader’s database, if possible without locking (backups)
- Copy the snapshot to new follower node
- Follower connects to leader and requests changes up to snapshot.
- Postgres position name in leader’s replication log is called log sequence number
- When follower has processed the backlog of data changes since the snapshot, it has caught up
Handling Node Outages
How do you achieve high availability with leader-based replication?
Follower Failure: Catch-up Recovery
Follower can compare it’s own log against the leader and run writes that were missed.
Leader Failure: Failover
Need to switch to new leader within system and followers need to start consuming data changes from new leader, called failover.
Steps:
- Determine that the leader has failed
- Choosing a new leader
- Reconfiguring the system to use the new leader
Failover Issues:
- If asynchronous replication, new leader may not have all writes from old leader. Those writes are lost which may violate clients’ durability expectations
- Discarding writes is dangerous if other storage systems outside of database need to be coordinated with database contents.
- Github had a system with autoincrementing counter where the counter lagged behind the old leader’s which caused primary keys to be inconsistent.
- Split brain - when two leaders believe that they are the leader. Raft tackles this with election and majority vote.
- Timeout? Long enough to prevent unnecessary failovers and short enough to not cause performance issues.
Implementation of Replication Logs
Several different replication methods are used in practice.
Statement-based Replication
Leader logs every write request (statement) that it executes and sends that statement log to its followers. For a relational database, this means that every INSERT, UPDATE, or DELETE statement is forwarded to followers and each follower parses and executes that SQL statement.
Issues
- Statements that calls a nondeterministic function (
NOW()orRAND())- Workaround: leader replace with a fixed return value, but with too many edge cases, other replication methods are now preferred
- Statements that use an autoincrementing column must be executed in exactly the same order on each replica. Limited when there are multiple concurrently executing transactions. Note: In this case, it’s just a stream of requests, not write-ahead logs
- Statements that have side effects may result in different side effects occurring on each replica, unless the side effects are absolutely deterministic.
Write-ahead Log (WAL) Shipping
A WAL is an append-only sequence of bytes containing all the writes to a log. Since the log contains details of which bytes were changed in which disk blocks. Replication is closely coupled to the storage engine.
Issues
- If the database changes its storage format from one version to another, the WAL is now not portable. Typically it’s not possible to run different versions of DB software on the leaders and followers.
Logical (row-based) Log Replication
To decouple storage engine internals from replication log, use different log formats. The replication log would use a logical log to distinguish itself from the storage’s (physical) data representation.
A logical log is a sequence of records describing the writes to database tables at the granularity of a row.
- Inserted row, log contains the new values of all columns.
- Deleted row, the log contains enough information to uniquely identify the deleted row (primary key).
- Updated row, the log contains enough information to identify the updated row and all the new values of the columns.
Benefits
- Easier for external applications to parse. Useful if sending the contents of a database to an external system (data warehouse) is needed. Technique is called change data capture.
- Easier to keep backward compatible
Trigger-based Replication
For situations where more flexibility is needed, like replicating a subset of the data. This means moving the replication up to the application layer.
Some tools like Oracle GoldenGate can make data changes available to an application by reading the database log.
Relational databases typically provide triggers and stored procedures that lets you register custom application code to execute on a data change within the database.
Issues
- Greater overhead (crossing layers)
- More prone to bugs and limitations
Problems with Replication Lag
Leader-based replication requires all writes to go through a single node, but read-only queries can go to any replica. Good for workloads that consist of mostly reads and only a small percentage of writes. Read-scaling architecture - can increase the capacity for serving read-only requests easily.
Synchronous configurations are very unreliable at scale. A single node failure makes entire system unavailable for writing.
Asynchronous followers have inconsistent data that may not be up-to-date. Eventual consistency
Reading Your Own Writes
Read-after-write consistency or read-your-writes consistency - This guarantees that if the user reloads the page, they will always see any updates they submitted themselves.
- No promises about other users and their updates.
- Reassures the user that their own input has been saved correctly.
Different implementations of read-after-write consistency
- When reading something the user has modified, read from leader, else read from follower
- Good for low traffic in user updates
- Debounce from last update to read from leader
- Client remembers the timestamp of its most recent writes. Then the system can ensure that the replica serving any reads for that user reflects updates at least until that timestamp. Need a form of logical timestamps due to clock skew.
Cross-device read-after-write consistency - when you want to have read-after-write consistency across the user’s devices.
- Metadata between devices are inconsistent, eg. logical timestamps
- Devices may be on different datacenters, connections will need to be centralized.
Monotonic Reads
Asynchronous followers can update at different paces. If the user read from the one follower and then another, it’s possible for the user to see things moving backward in time if the second follower contains older data.
Monotonic reads is a guarantee that when the user makes several reads in sequence, they will not read older data after reading newer data.
- Implementation: user always makes their reads from the same replica (consistent hashing)
Consistent Prefix Reads
Consistent prefix reads guarantees that if a sequence of writes happens in a certain order, then anyone reading those writes will see them appear in the same order. Causal consistency
Solutions for Replication Lag
Important to think about how replication lag affects your system and whether or not the lag fits into your business requirements.
It’s easier for application developers to not worry about subtle replication issues and could just trust their databases to “do the right thing”. This is why transactions exist, they are a way for database to provide stronger guarantees so that the application can be simpler.
Multi-Leader Replication
Multi-Leader Replication is an extension of the leader-based replication model which allows for more than one node to accept writes.
Use Cases for Multi-Leader Replication
Rarely makes sense to use multi-leader setup within a single datacenter. The benefits rarely outweigh the added complexity.
Multi-Datacenter operation
A leader is in each datacenter. Within each datacenter, regular leader-follower replication is used. Between datacenters, each datacenter’s leaders replicates its changes to leaders in other datacenters.
Comparison of single-leader vs multi-leader within a multi-datacenter deployment
| Single-Leader | Multi-Leader | |
|---|---|---|
| Performance | Every write must go over the internet to the datacenter with leader; adds latency | Every write can be processed in the local datacenter and is replicated asynchronously |
| Tolerance of datacenter outages | If the datacenter with the leader fails, failover can promote a follower in another datacenter to be leader | Each datacenter can continue operating independently of the others and replication catches up when the failed datacenter comes back online |
| Tolerance of network problems | Goes over public internet, less reliable than the local network within datacenter (writes are made synchronously over this link) | Asynchronous replication can usually tolerate network problems better |
Clients with Offline Operation
An application that needs to continue to work while offline will need to sync up with its online replica when online again.
The application’s local database acts as a leader, by accepting write requests, and an asynchronous multi-leader replication process between the replicas of the databases on all devices. Each database is like a “datacenter ” in the multi-datacenter example.
Example databases: CouchDB
Collaborative Editing
Real-time collaborative editing applications allow several people to edit a document simultaneously.
To guarantee that there will be no editing conflicts, the application must obtain a lock on the document before a user can edit it. This collaboration model is equivalent to single-leader replication with transactions on the leader.
For faster collaboration, make the unit of change very small (e.g. a single keystroke) and avoid locking. Allows multiple users to edit simultaneously, but introduces challenges of multi-leader replications like conflict resolution.
Handling Write Conflicts
Synchronous Versus Asynchronous Conflict Detection
In a single-leader database, the second writer will either block or wait for the first write to complete, or abort the second write transaction, forcing the user to retry the write.
In a multi-leader setup, both writes are successful, and the conflict is only detected asynchronously at some later point in time (when leaders sync up).
Conflict Avoidance
Simplest strategy: avoid conflicts. Frequently the recommended approach, since many implementation of multi-leader replication handle conflicts poorly.
An example is, if the application can ensure that all writes for a particular record go through the same leader, then conflicts cannot occur.
Sometimes you might want to change the designated leader for a record, like a datacenter failing. This is where conflict avoidance breaks down and need to design for the possibility of concurrent writes on different leaders.
Converging Toward a Consistent State
A single-leader database applies writes in a sequential order: if there are several updates to the same field, the last write determines the final value of the field.
In multi-leader, there is no defined ordering of writes. Thus, the database must resolve the conflict in a convergent way, which means that all replicas must arrive at the same final value when all changes have been replicated.
Different ways of achieving convergent conflict resolution:
- Give each write a unique ID, choose highest ID as the winner. Technique is called last write wins. Popular but dangerously prone to data loss!
- Give each replica a unique ID, higher-number replica always take precedence over writes from lower-numbered replicas. This approach also implies data loss!
- Somehow merge values together. (e.g. order alphabetically, then concatenate them)
- Record the conflict in an explicit data structure that preserves all information, and write application code that revolves the conflict at some later time.
Custom Conflict Resolution Logic
Code may be executed on write or on read: On write
- Database system detects a conflict in the log of replicated changes and calls conflict handler. On read
- When a conflict is detected, all the conflicting writes are stored. The next time the data is read, multiple versions of the data are returned to the application. The user or the application will handle resolving the conflict and write the result back to the database. (CouchDB way)
Automatic Conflict Resolution
Custom code for conflict resolution can be error-prone and complicated.
Here’s some research on atomically resolving conflicts caused by concurrent data modification:
- Conflict-free replicated datatypes - data structures that can be concurrently edited by multiple users and automatically resolve conflicts in sensible ways
- Mergeable persistent data structures - track history explicitly (like git) and use a three-way merge function (TODO)
- Operational transformation - conflict resolution algorithm behind collaborative editing applications like Google Docs and Etherpad. It was designed particularly for concurrent editing of an ordered list of items, such as the list of characters that constitute a text document.
Multi-Leader Replication Topologies
A replication topology describes the communication paths along which writes are propagated from one node to another.
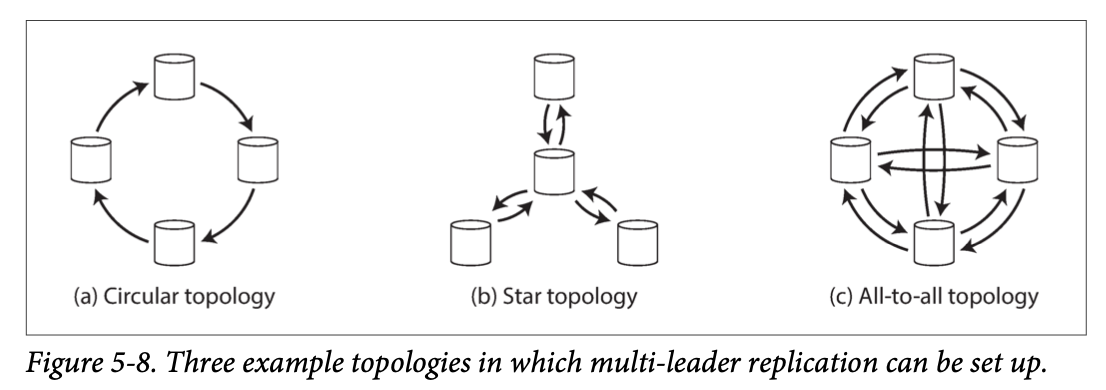
- Most general topology is all-to-all
- In circular and star topologies, a write may need to pass through several nodes and to prevent infinite replication loops, each write is tagged with ID of nodes.
- In circular and star topologies, the failure of a node can interrupt the flow of replication messages between other nodes.
Issue of causality To order events, use version vectors.
- Timestamps are not enough due to skew
Leaderless Replication
Every replica can accept writes from clients. An example would be Amazon Dynamo.
Some leaderless implementations, the client sends writes directly to replicas. Other leaderless implementations might have a coordinator node that does this on behalf of the client. Despite a coordinator, the coordinator doesn’t enforce a particular ordering of writes which affects how the database is used.
Writing to the Database When a Node Is Down
In a leaderless configuration, a failover does not exist (assuming that all operations are broadcasted and with a quorum).
Read Repair and Anti-entropy
After an unavailable node comes back online how does it catch up?
Two mechanisms in Dynamo-style datastores:
- Read repair
- When a client makes a read from several nodes in parallel, it can detect any stale responses. Write back newer value to stale values on replicas.
- Anti-entropy process
- Some datastores have a background process that constantly looks for differences in the data between replicas and copies any missing data from one replica to another.
- Not consistent, may be significant delays
Quorums for Reading and Writing
Basic idea is we can have w writers and r readers. As long as , so that there is at least one node that both reads and writes which means that one node will have most consistent information.
Writes and readers counts can shift as long as the above condition holds. This means that we can shift writes and readers for different use cases like read heavy systems has more writers and less readers, and write heavy systems have more readers and less writers.
Limitations of Quorum Consistency
With w and r set to smaller numbers, , increases the likelihood of reading stale values. But this lowers latency and increases availability.
Even with , there are still edge cases where stale values are returned.
- The case of when a sloppy quorum is used.
- If two writes occur concurrently, it is not clear which one happened first. The safe solution is to merge concurrent writes. If winner is picked based on timestamp (last write wins), writes can be lost due to clock skew.
- If a write happens concurrently with a read, the write may be reflected on only some of the replicas. Undetermined whether the read is a stale or new value.
- If a write succeeded on some replicas but failed on others and success count < w, the write is reported as failure. Assuming that the replicas that succeeded the write are not rolled back, subsequent reads may or may not return the value from that write.
- If a node carrying a new value fails, and its data is restored from replica carrying an old value, the number of replicas storing the new value may fall below w, breaking the quorum condition.
- More edge cases with unlucky timing…
Dynamo-style databases are generally optimized for use cases that can tolerate eventual consistency.
Monitoring Staleness
It’s important to monitor whether your databases are returning up-to-date results. If it falls behind significantly, it should alert you to investigate the cause (e.g. prob in network or an overloaded node).
For leader-based replication, the database typically exposes metrics for replication lag. Since followers contain a replication log, by subtracting the difference of the follower’s current position in the log from the leader’s current position, a metric for replication lag can be derived.
For leaderless replication, there is no fixed order of writes which makes monitoring more difficult. If the database only uses read repair (no anti-entropy), infrequently read values or the value returned by a state replica may be ancient. There’s no limit to how old a value might be.
Sloppy Quorums and Hinted Handoff
Databases with appropriately configured quorums can tolerate the failure of individual nodes without the need for failover.
But quorums are not as fault-tolerant as they could be. A network interruption can easily cut off a client. There’s a strict requirement that there is at least w or r reachable nodes to reach a quorum.
In a large cluster, it’s likely that the client can connect to some database nodes. In this case…
- Is it better to return errors to all requests when a quorum is not reached at w or r nodes.
- Or should we accept writes anyways and write them to some nodes that are reachable but aren’t among the n nodes on which the values usually lives?
The latter is known as sloppy quorum: writes and reads still require w or r successful responses, but those may include nodes that are not among the designated n “home” nodes for a value.
Once the network interruption is fixed, any writes that one node temporarily accepted on behalf of another node are sent to the appropriate “home” nodes. This is called hinted handoff. However, this means that even when , you cannot be sure to read the latest value for a key. The latest value may have been temporarily written to some nodes outside of n. The non “home” node is not originally part of the n set.
Pros: increased write availability, as long as any w nodes are available, the databases can accept writes.
Sloppy quorum isn’t considered a quorum at all in the traditional sense. It’s only an assurance of durability where the data is stored on w nodes somewhere. There’s no guarantee that a read of r nodes will see it until the hinted handoff has completed.
Detecting Concurrent Writes
Dynamo-style databases allow several clients to concurrently write to the same key, which means that conflicts will occur even if strict quorums are used. Below are techniques for conflict resolution.
Last Write Wins (discarding concurrent writes)
In last write wins (LWW), for two concurrent writes, the replica will only choose the one with the most “recent” timestamp. LWW achieves the goal of eventual convergence, but at the cost of durability. If there are several concurrent writes to the same key, even if they were all reported as successful to the client, only one of the writes will survive and the others will be silently discarded. Additionally, LWW may even drop writes that are not concurrent `<TODO: linked to Timestamps for ordering to events
- Note: durability here is once the system tells a client “your write succeeded,” that write should remain part of the database’s state in a way that can still be observed or recovered later.
The only safe way of using a database with LWW is to ensure that a key is only written once and thereafter treated as immutable, thus avoiding any concurrent updates to the same key. E.g. a recommended way of using Cassandra is to use a UUID as the key, thus giving each write operation a unique key.
The “happens-before” relationship and concurrency
How do we decide whether two operations are concurrent or not?
- Happens before - OP A happens before OP B if B knows about A, depends on A, or builds upon A in some way.
- Concurrent - two operations are concurrent if neither happens before the other.
Merging concurrently written values
For concurrent writes, how can we decide the final value?
- For adding, take the union.
- For removing, mark for deletion. Merging may not yield the right result. Instead use a tombstone or a deletion marker.
- Eg. a union of two sibling datasets with one item deleted from one of them yields the deleted item still appearing
Version vectors
Vector containing version number at each replica per operation. Not to be confused with vector clocks. Note: Vector clock and version vectors share an identical state representation but their updates are different.
- Vector clocks:
- On local event, it increments its own counter
- On send, increments its own counter and pairs message with vector
- On recv, increments its own counter and updates other vector counters to be max of recv message and its own.
- Used to determine causality for an event
- Version Vector:
- On local event, it increments its own counter
- On replica synchronization of A and B, sets their copy of version vector to
- Used to track updates for an item and can also track causality for that item
- Key idea, each item has it’s own version vector
Summary
Replication is used for:
- High availability - keep system running, even under partial failure
- Disconnected operation - allowing an application to continue working when there is a network interruption
- Latency - placing data geographically close to users, so that users can interact with it faster
- Scalability - being able to handle a higher volume of reads than a single machine could handle, by performing reads on replicas
Approaches to replication:
- Single-leader replication
- Multi-leader replication
- Leaderless replication
Replication can be synchronous or asynchronous.
- Synchronous → consistency, slow, doesn’t handle faults well
- Asynchronous → fast, but inconsistent, handle faults better, replication lag
Replication lag
Few consistency models that can handle replication lag and keep data consistent.
- Read-after-write consistency - Users should always see data they submitted themselves
- Monotonic reads - After users have seen the data at one point in time, they shouldn’t later see the data from some earlier point in time
- Consistent prefix reads - Users should see the data in a state that makes causal sense