Context of where AI is currently
Big issue is scale
- Consuming a nontrivial portion of the world’s electricity
- Running out of data to train them
Models as a service
- Due to the demands of training LLMs, models are developed by a few organizations with the resources for others to use.
Applications
- Product recommendations
- Fraud detection
- Churn predictions
The Rise of AI Engineering
Language Models
Language model - encodes statistical information about one or more languages.
- Intuitively, this information tells us how likely a word is to appear in a given context.
- Today, language models can involve multiple language
The basic until of a language mode is a token. A token can be a character, word, or part of a word, depending on the model.
- Why tokens?
- Tokens allow the model to break words into meaningful components like “cook” + “ing” = “cooking”
- Fewer unique tokens than unique words can reduce model’s vocabulary size and making the model more efficient
- Tokens also help the model process unknown words. E.g. “googling” → “googl” + “ing”
There are two types of language models:
- Masked language models - trained to predict missing tokens anywhere in the sequence, using context from both before and after the missing tokens.
- BERT
- Autoregressive language models - trained to predict the next token in a sequence, using only the preceding tokens
- For text generation, which is why it’s more popular
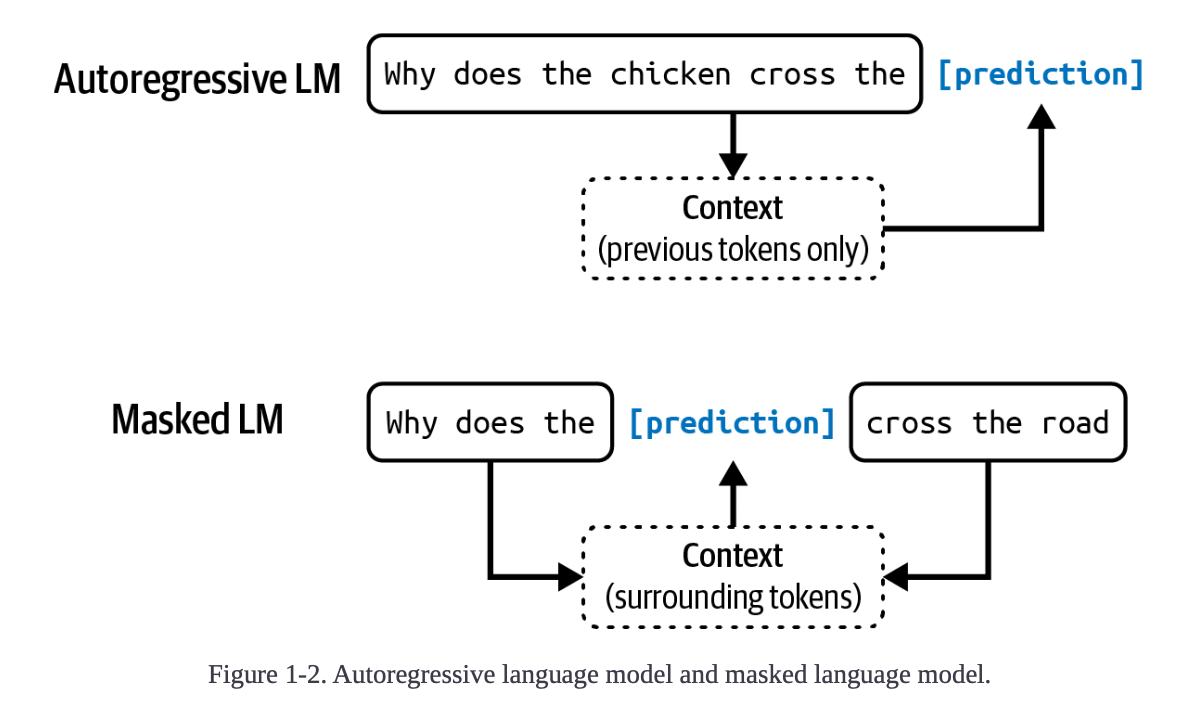
- For text generation, which is why it’s more popular
What is “generative”?
- A language model can use its fixed, finite vocabulary to construct infinite possible outputs.
- A model that can generate open-ended outputs is called generative
A language model (autoregressive) can be thought of as a completion machine. The completions from a generative model are based on predictions, thus not guaranteed to be correct. Models have a probabilistic nature.
Self-supervision
What caused language models to be the center of the scaling approach? Self-supervision!
Language models can be trained using self-supervision while many other models require supervision.
Supervision refers to the process of training ML algorithms using labeled data. Costly and slow to obtain.
Self-supervision overcomes the supervision bottleneck by having the model infer labels from input data.
- Language modeling is self-supervised because each input sequence provides both the labels (tokens to be predicted) and the contexts the model can use to predict these labels.
- The input data is inherently “labeled” by splicing the input. E.g. For “I, love” the expected next token is “food” given a input of “I love street food.”

How large does a language model have to be to be considered large? Model’s size is typically measured by its number of parameters.
- A parameter is a variable within an ML model that is updated through
- Typically, the more parameters a model has, the greater its capacity to learn desired behaviors.
Why do larger models need more data?
- Larger models have more capacity to learn, and therefore, would need more training data to maximize their performance. Smaller datasets would be a waste of compute because similar performance can be achieved with smaller models.
LLMs to Foundation Models
Foundation models is a term defined by the importance of these models to AI applications and that they can be engineered for different needs.
- Foundation models incorporates additional modalities besides text into LLMs
Multimodal model is a model that can work with more than one data modality.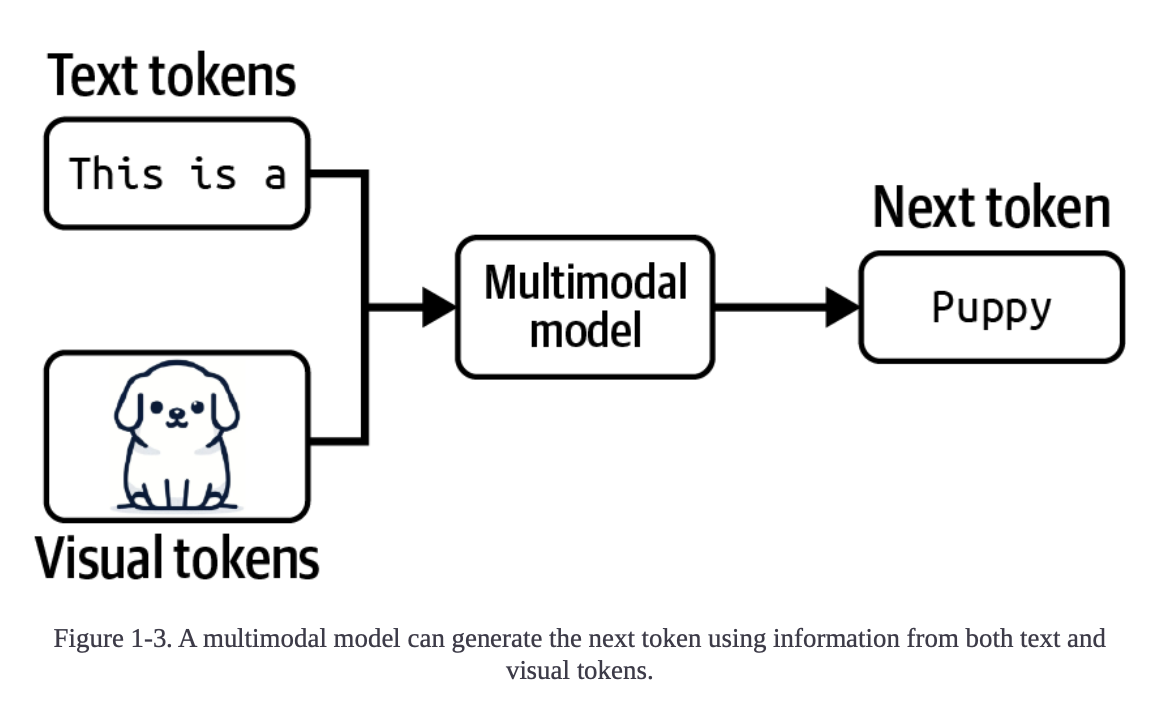
- Multimodal models can be also trained with self-supervision! OpenAI used a variant of self-supervision called natural language supervision that used image and text pairs on the internet. This was on their CLIP model.
- Note: CLIP isn’t generative, it’s an embedding model trained to produce joint embeddings of both text and images.
- High level: Embeddings are vectors that aim to capture the meanings of the original data.
Foundation models are also the turning point of models becoming general-purpose. Due to the scale and training of foundation models, they are capable of a wide arrange of tasks out of the box.
- E.g. LLM can do both sentiment analysis and translation.
Techniques to Make the Model Generate what you want
- Prompt Engineering - add instructions with examples of desired results.
- Retrieval-augmented generation - connect the model to a databases of customer reviews that the model can leverage.
- Finetuning - further train the model on a dataset of labeled data.
Adapting existing powerful model to your task is generally a lot easier than building a model for your task from scratch
From Foundation Models to AI Engineering
Availability and accessibility of powerful foundation models lead to three factors that attribute to the rapid growth of AI engineering:
- General-purpose AI capabilities - ability to do more tasks, especially ones that were thought to be impossible
- Increased AI investments - as AI applications become cheaper to build and faster to go to market, returns become more attractive
- Low entrance barrier to building AI applications - model as a service approach makes it easier to leverage AI to build applications. Models are exposed by APIs that receive user queries.
Foundation Model Use Cases
- Coding
- Image and Video Production
- Writing
- Education
- Conversational bots
- Information aggregation
- Data organization
- Workflow automation
AI Use Case Evaluation
How to decide whether or not to build an AI application?
Risks from high to low
- If you don’t do this, competitors with AI can make you obsolete
- If you don’t do this, you’ll miss opportunities to boost profits and productivity
- You’re unsure where AI will fit into your business yet, but you don’t want to be left behind
Role of AI and humans
- Critical vs Complementary - if the app can work without AI, AI is complementary. Otherwise, it’s critical.
- Reactive or Proactive - reactive feature shows its responses in reaction to users’ requests or specific actions. Proactive feature shows its responses when there’s an opportunity for it.
- Dynamic or Static - dynamic features are updated continually with user feedback. Static features are updated periodically.
Crawl-Walk-Run Microsoft’s framework for gradually increasing AI automation in products.
- Crawl - human involvement is mandatory.
- Walk - AI can directly interact with internal employees.
- Run - increased automations, potentially including direct AI interactions with external users.