Partitioning - for very large datasets, or very high query throughput, we need to break the data up into partitions, also known as sharding.
- The core reason for partitioning data is scalability. Different partitions can be placed on different nodes in a shared-nothing cluster
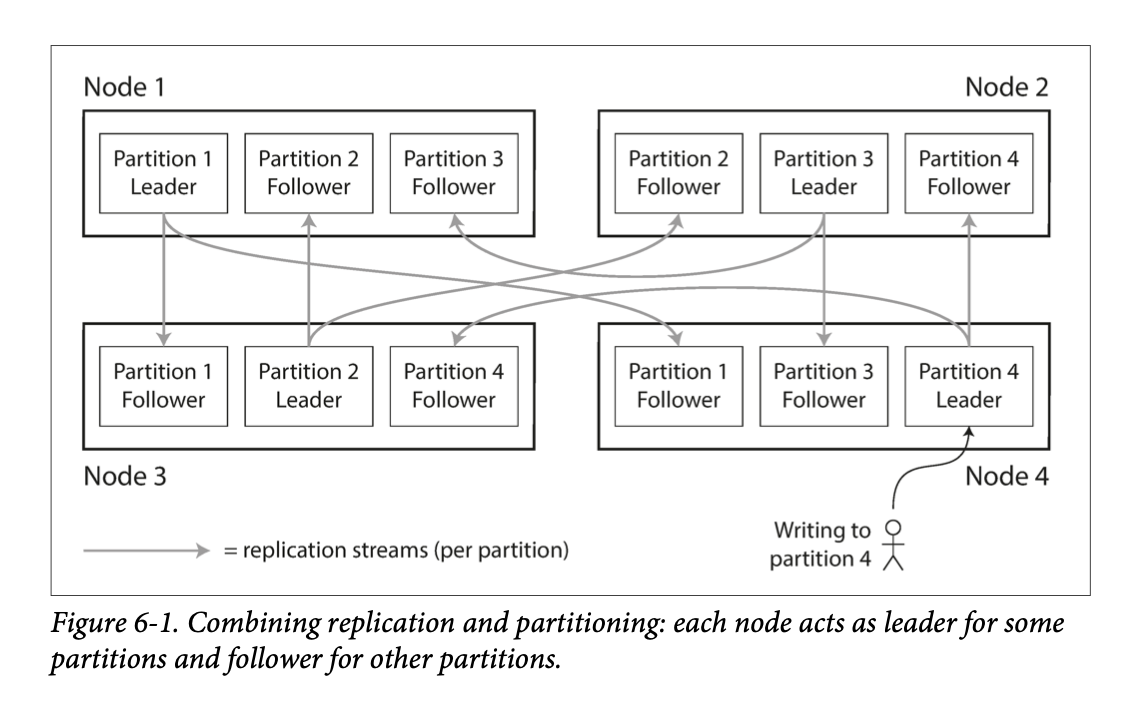
Partitioning and Replication
Partitioning is usually combined with replication so that copies of each partition are stored on multiple nodes.
- Even though each record belongs to exactly one partition, it may still be stored on several different nodes for fault tolerance.
Partitioning of Key-Value Data
Fairness - the goal with partitioning is to spread the data and query load evenly across nodes.
Skewed - a skewed partitioning is unfair. The presence of skew leads to disproportionately high load on a subset of nodes which is called a hot spot.
The simplest approach for avoiding hot spots would be to assign records to nodes randomly.
That would distribute the data quite evenly across the nodes, but reading becomes difficult since the data is scattered around. Below is different techniques that considers lookup performance and fairness.
Partitioning by Key Range
Assign a continuous range of keys to each partition.
- Ranges of keys are not necessarily evenly space, because the data may not be evenly distributed
- Partition boundaries might be chosen manually by an administrator.
- Within each partition, we can keep keys in sorted order.
Issues:
- Certain access patterns can lead to hot spots.
- Eg. Timestamps. For analytics, typically updates are made in realtime, causing the current day to be a hot spot.
- To avoid this, you need to use something other than the timestamp as the first element of the key.
- Rebalancing partitions. Access patterns may change causing key ranges to change with them to maintain performance.
Partitioning by Hash of Key
Also known as Consistent hashing. “Consistent” describes here the approach to rebalancing between partitions. Also known as hash partitioning for less confusion.
For partitioning purposes, the hash function does not need to be cryptographically strong (unpredictable). A good hash function takes skewed data and makes it uniformly distributed.
Each partition is assigned a range of hashes and every key whose hash falls within a partition’s range will be stored in that partition.

Issues:
- Bad for range queries. Adjacent keys are now scattered across all the partitions.
- Cassandra achieves a compromise between the two partitioning strategies by using a compound primary key. An example primary key is
(user_id, update_ts).- Partitions based on
user_id, then within partitions are sorted byupdate_ts
- Partitions based on
- Cassandra achieves a compromise between the two partitioning strategies by using a compound primary key. An example primary key is
Skewed Workloads and Relieving Hot Spots
Skewed workloads are workloads where a large majority of reads and writes are for the same key. This can be due to say a celebrity posting to a huge following.
Most data systems are not able to automatically compensate for highly skewed workload. It’s up to the application to reduce the skew.
- One solution is to append a random number in front of hot keys to reduce load. This requires a way of keeping track of where the resulting key hash is for retrieval.
Partitioning and Secondary Indexes
A secondary index doesn’t identify a record uniquely but is created as a way of improving search for a particular value. For example: Solr and Elasticsearch.
The core issue with secondary indexes is that they don’t map neatly to partitions. Thus, there are two main approaches to partitioning a database with secondary indexes:
- Document-based partitioning
- Term-based partitioning
Partitioning Secondary Indexes by Document
Each partition maintains it’s own secondary indexes or each partition’s secondary indexes is a subset of a whole.
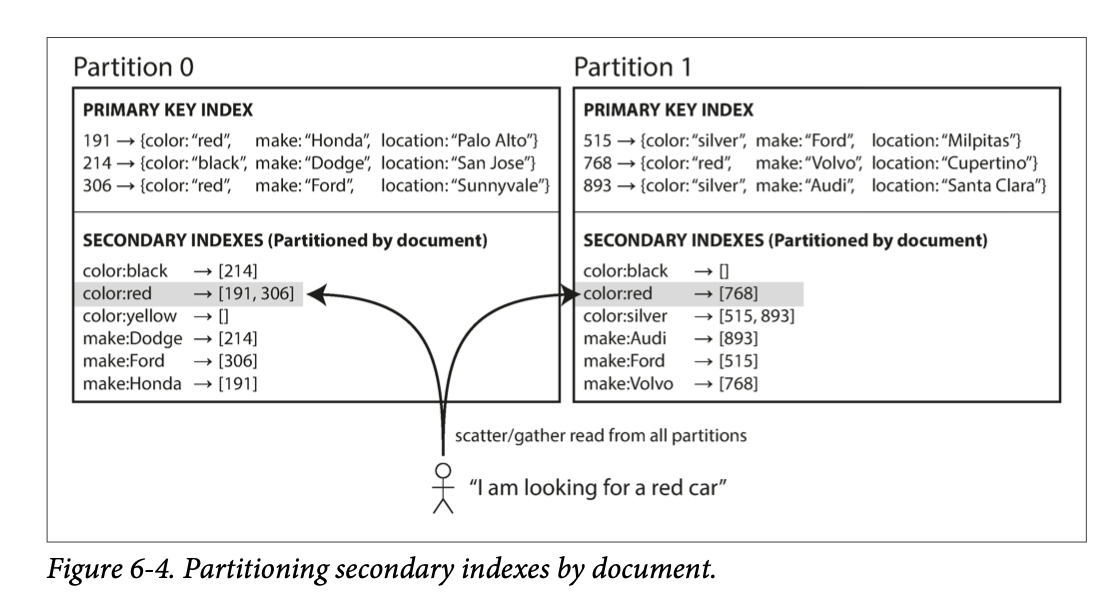
- Operations of document X only requires to access one partition.
- Reading secondary indexes becomes an issue here since a property like “red cars”, spans across partitions.
- To query partitioned databases, need to scatter/gather which makes read queries expensive.
- Most db vendors recommend structure your partitioning scheme so that secondary index queries can be served from a single partition if possible.
Partitioning Secondary Indexes by Term
Rather than each partition having its own secondary index (a local index), we can construct a global index that covers data in all partitions. The global index is also partitioned but its partitioned differently from primary index.
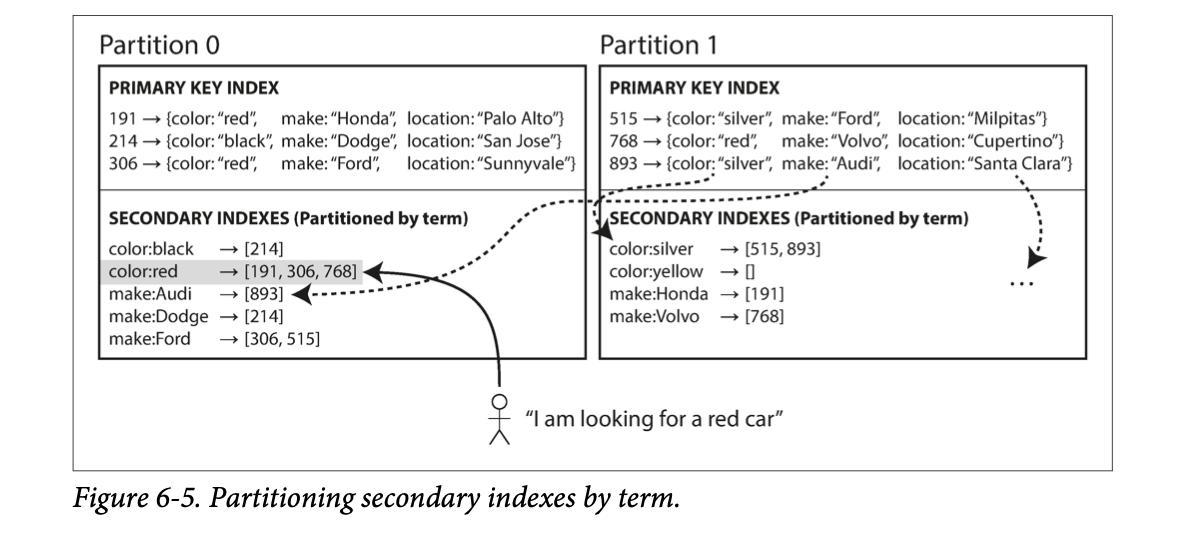 Term-partition - when the partitions are decided by properties of the index like
Term-partition - when the partitions are decided by properties of the index like color: red.
- The advantage of a global (term-partitioned) index over a document-partitioned index is the increase in efficiency from reads. A client would only need to request one partition.
- The disadvantage is writes are slower and more complicated, because a single write to a single document may now affect multiple partitions of the index.
Rebalancing Partitions
Changes can occur over time within a database:
- Query throughput increases → more CPUs
- Dataset size increases → more disks and RAM
- Machines failing → failover to another machine
All these changes require data to move from one node to another. The process of moving load from one node in a cluster to another is called rebalancing.
Rebalancing minimum requirements:
- After rebalancing, the load should be shared fairly between the nodes in the cluster.
- While rebalancing is happening, the database should continue accepting reads and writes.
- No more data than necessary should be moved between nodes, to make rebalancing fast and to minimize the network and disk I/O load.
Strategies for Rebalancing
- hash % n - Not a good strategy because on every change of N, key will need to shift to next node.
- Fixed number of partitions - create more partitions than there are nodes. With each new node, the new node can steal a few partitions from every existing node until partitions are fairly distributed.
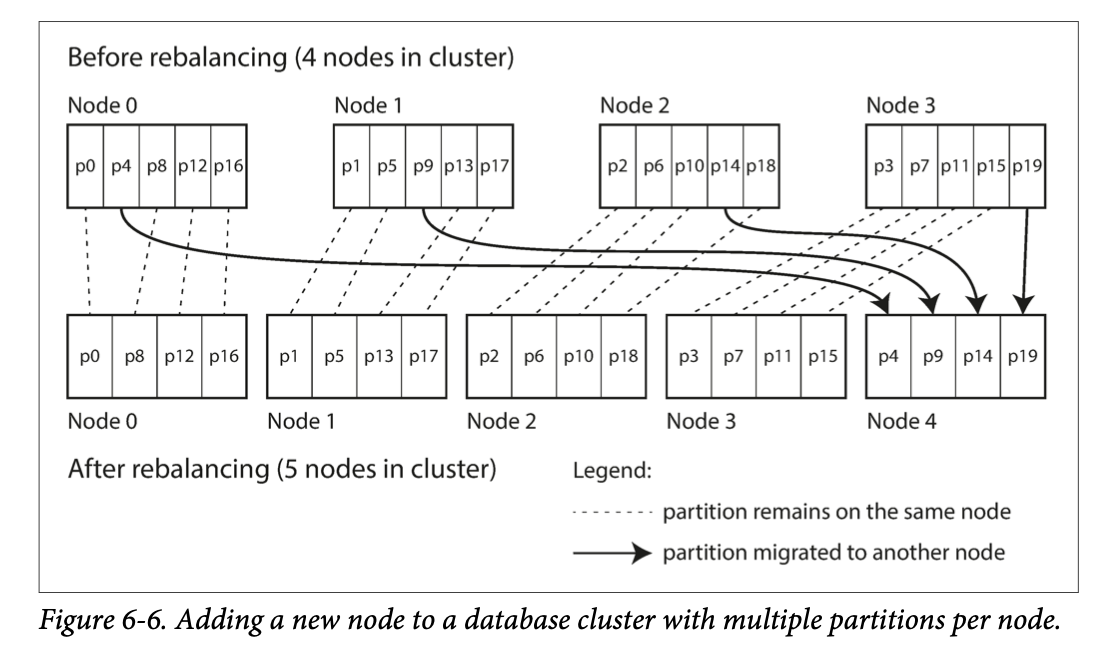
- Dynamic partitioning - dynamically adjust number of partitions to data volume.
- for databases that use key range partitioning, a fixed number of partitions with fixed boundaries will be very constrained and reconfiguring the partition boundaries manually is very tedious.
- Big idea:
- If a partition grows to exceed a configured size, it is split into two partitions where approximately half of the data ends up on each side of split.
- If a partition shrinks below some threshold, it can be merged with an adjacent partition.
- Chord is one example.
- Partitioning proportionally to nodes - number of partitions is proportional to number of nodes or a fixed number of partitions per node.
- When new node joins cluster, it randomly chooses a fixed number of existing partitions to split, and then takes ownership of one half of each of those split partitions while leaving the other half of each partition in place.
- Can be unfair, but if averaged over a large enough # of partitions, it should be pretty even
Operations: Automatic of Manual Rebalancing
Does rebalancing happen automatically or manually. There’s a gradient between fully automatic rebalancing and manual rebalancing.
Fully automated rebalancing is convenient but unpredictable. For example, with node failure we need to migrate over data. But in a distributed system how do we know if that node is truly down or temporarily slow? This gray area can cause automated rebalancing to trigger or not causing inconsistencies. Hence, it can be good to have a human in the loop for rebalancing to prevent operational surprises.
Request Routing
When a client makes a request, how does it know which node to connect to?
This is an instance of a more general problem called service discovery.
- Many companies have their own in-house service discovery tools.
Different approaches to the problem:
- Allow client to contact any node (e.g. via a round-robin load balancer)
- If that node owns the partition that can handle the request, it responds. Otherwise, the request is forwarded.
- Send all requests from clients to a routing tier first
- Routing tier determines the node that should handle each request
- Require that clients be aware of the partitioning and the assignment of partitions to nodes
- Clients simply connect directly to appropriate node
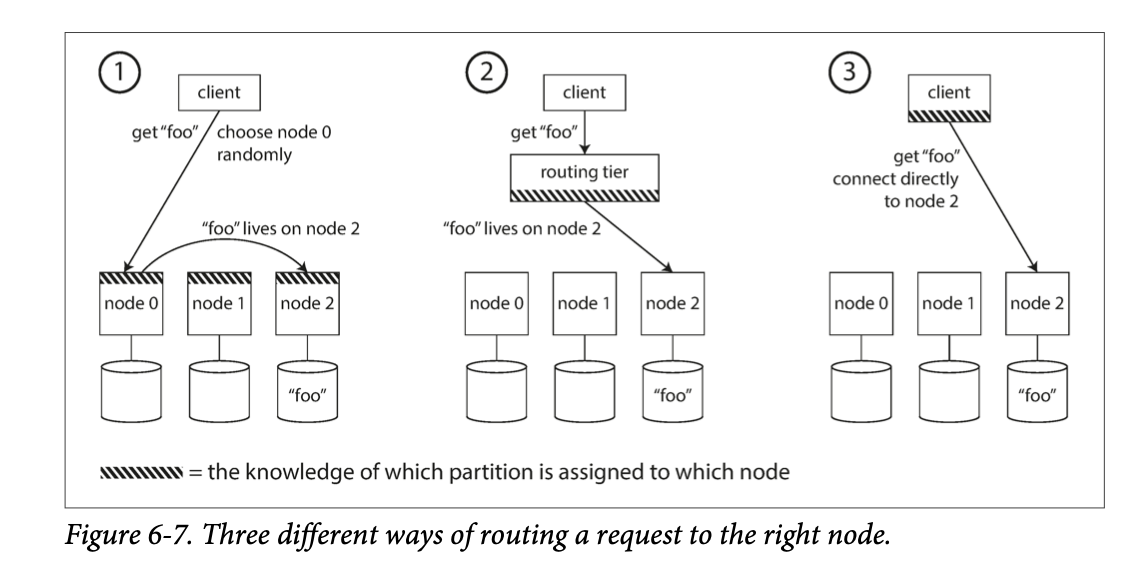
- Clients simply connect directly to appropriate node
The big challenge here is that all participants have to agree, otherwise requests would be sent to the wrong nodes and not handled correctly. In other words, it’s a consensus problem.
Many distributed data systems rely on a separate coordinator services such as ZooKeeper to keep track of this cluster metadata.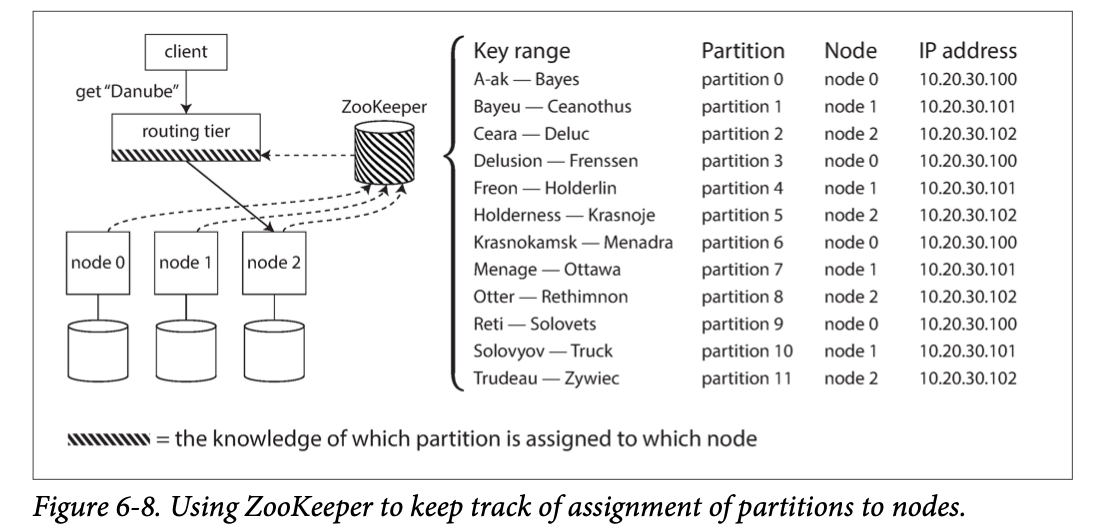 Each node registers itself in ZooKeeper, and ZooKeeper maintains the authoritative mapping of partitions to nodes. Other actors, such as the routing tier or the partitioning-aware client, can subscribe to this information in ZooKeeper.
Each node registers itself in ZooKeeper, and ZooKeeper maintains the authoritative mapping of partitions to nodes. Other actors, such as the routing tier or the partitioning-aware client, can subscribe to this information in ZooKeeper.
Examples:
- LinkedIn’s Espresso uses Helix for cluster management which in turn relies on ZooKeeper
- HBase, SolrCloud, and Kafka also use ZooKeeper to track partition management
For Cassandra and Riak, they take a different approach. They use a gossip protocol among the nodes to disseminate any changes in the cluster state. Requests can be sent to any node and that node forwards them to the appropriate node.
- Additional complexity per node, but avoids extra dependency of an external coordination service
Parallel Query Execution
Massively parallel processing (MPP) relational database products are typically used for analytics and require more sophisticated types of queries. A typical data warehouse query contains several join, filtering, grouping, and aggregation operations. The MPP query optimizer breaks this complex query into execution stages and partitions. Many of these stages are run in parallel for performance.
Summary
Partitioning is necessary when there’s too much data to store and process on a singular machine.
- Key range partitioning - keys are sorted and a partition owns all keys from some min to some max value of the key
- Hash partitioning - keys a ran through a hash and a partition owns a range of hashes. This randomizes the distribution of keys to partition increasing fairness.
- Compound key - One part of the key is used to identify the partition, the other is used for sort order.
Secondary index also needs to be partitioned and there are two methods:
- Document-partitioned indexes (local indexes) - secondary indexes are stored in the same partition as primary index.
- Only a single partition needs to be updated on write, but reads are scatter/gather.
- Term-partition indexes (global indexes) - secondary indexes are partitioned separately using indexed values. An entry in the secondary index may include records from all partitions of the primary key.
- Multiple partitions may need to be updated on write, but reads only require one partition.
Over time data changes and thus rebalancing may be needed. Noteworthy strategies:
- Large fixed number of partitions, and distribute evenly from existing partitions with growth and deletions
- Dynamic partitions - adjust size of partition based on min max limits (decide when to split)
- Partitioning proportionally to nodes - each node gets a fixed number of partitions.
Routing queries to partitions can be challenging with rebalancing. Thus, a consistent system to manage routing to partition is necessary called the coordination service. Zookeeper and etcd are examples of coordination services.