Source: https://dl.acm.org/doi/pdf/10.1145/945445.945450
Abstract
Google FIle System, a scalable distributed file system for large distributed data-intensive applications.
- Provides fault tolerance while running on inexpensive commodity hardware
- Delivers high aggregate performance to a large number of clients
Introduction
Design driven by workload and environment:
- Component failures are the norm rather than the exceptions (at scale)
- Files are huge by traditional standards (Multi-GB files are common)
- Most files are mutated by appending new data rather than overwriting existing data
- Random writes within a file are practically non-existent
- Once written, the files are only read, and often only sequentially.
- Appends become the focus of performance optimization and atomicity guarantees, while caching blocks in the client loses its appeal
- Co-designing the applications and the file system API benefits the overall system by increasing our flexibility.
- Relaxed GFS’s consistency model to vastly simplify the file system without imposing an onerous burden on the applications
Design Overview
Assumptions
- System is built from many inexpensive commodity components that often fail
- Need a monitoring system to detect, tolerate, and recover promptly from component failures on a routine basis
- System stores a modest number of large files, few million files and each typically 100 MB or larger in size
- Multi-GB files are the common case. Small files must be supported, but no need for prioritizing optimization
- Workloads primarily consist of two kinds or reads: large streaming reads and small random reads
- In large streaming reads, individual operations typically read hundreds of KBs, more commonly 1 MB or more
- Successive operations from the same client often read through a contiguous region of a file.
- A small random read typically reads a few KBs at some arbitrary offset
- Performance applications often batch and sort their small reads to advance steadily through the file rather than go back and forth
- In large streaming reads, individual operations typically read hundreds of KBs, more commonly 1 MB or more
- Workloads also have many large, sequential writes that append data to files. Typical operation sizes are similar to those for reads and files that are written to are rarely written to again.
- Small writes at arbitrary positions in a file are supported but do not have to be efficient
- System must efficiently implement well-defined semantics for multiple clients that concurrently append to the same file.
- In their workload, files are often used as producer-consumer queues or for many-way merging. Hundreds of producers, running one per machine, will concurrently append to file.
Interface
- Create, delete, open, close, read, write
- Additional:
- snapshot - copies a file or directory tree at low cost
- record append -allows multiple clients to append data to the same file concurrently while guaranteeing the atomicity of each individual client’s append.
Architecture
- GFS cluster consists of:
- single master
- multiple chunkservers
- accessed by multiple clients
- Files are divided into fixed-size chunks.
- Each chunk is identified by an immutable and globally unique 64 bit chunk handle assigned by the master at chunk creation
- Chunkservers store chunks on local disks as Linux files and read or write chunk data specified by a chunk handle and byte range.
- chunks are replicated on multiple chunkservers for reliability, by default 3 replicas
- Master maintains all file system metadata
- namespace
- access control information
- mapping from files to chunks
- current locations of chunks
- System wide activities:
- chunk lease management
- garbage collection of orphaned chunks
- chunk migration between chunkservers
- Communicates with each chunk server in HeartBeat messages to give it instructions and collect its state
GFS client code linked into each application implements the file system API and communicates with the master and chunkservers to read or write data on behalf of the application
Clients interact with the master for metadata operations, but all data-bearing communication goes directly to the chunkservers
Neither the client nor the chunkserver caches file data.
- Client caches offer little benefit because most applications stream through huge files or have working sets too large to be cached.
- However, Clients do cache metadata
Single master
- simplifies their design
- Enables the master to make sophisticated chunk placement and replication decisions using global knowledge
- Client asks the master which chunkservers it should contact and caches this information for a limited time and interacts with the chunkservers directly for many subsequent operations
Chunk Size
- 64 MB chunks - huge
- Each chunk replica is stored as a plain Linux file on a chunkserver and is extended only as needed
- Lazy space allocation avoids wasting space due to internal fragmentation
- Large chunk size offers several important advantages.
- Reduces clients’ need ot interact with master b/c reads and writes on the same chunk require only one inital request to the master for chunk loation information
Metadata
- Three types
- File and chunk namespace
- mapping from files to chunks
- locations of each chunk’s replicas
- Kept persistent by logging mutations to an operation log stored on the master’s local disk and replicated on remote machines
- Master doesn’t store chunk location persistently
In-Memory Data Structures
- Since metadata is stored in memory, master operations are fast
- Easy and efficient for the master to periodically scan through its entire state in background
- Used for chunk garbage collection, re-replication for failures, and chunk migration to balance load and disk space usage across chunk servers
- Bottlenecks:
- Limited by master’s memory capacity
- Not an issue in practice, master maintains less than 64 bytes of metadata for each 64MB chunk
- File namespace data typically requires less than 64 bytes per file using prefix compression
- Limited by master’s memory capacity
Chunk locations
- Master polls which chunkserver have a replica of a given chunk. Done at startup and updates itself over time with HeartBeat messages
Operation Log
- Contains a historical record of critical metadata changes. It’s central to GFS.
- Persistent record of metadata + logical time line that defines the order of concurrent operations
Consistency Model
- Relaxed consistency model, supports highly distributed applications well but remains relatively simple and efficient to implement
Guarantees by GFS
- File namespace mutations (e.g. file creation) are atomic
- Handled exclusively by the master:
- namespace locking guarantees atomicity and correctness
- master’s operation log defines a global total order of these operations
- Handled exclusively by the master:
- State of file region after a data mutation depends on the type of mutation whether it succeeds or fails, and whether there are concurrent mutations
- A file region is consistent if all clients will always see the same data
- A region is defined after a file data mutation if it is consistent and clients will see what the mutation writes in its entirety
- Data mutations may be writes or record appends
- A write causes data to be written at an application-specified file offset
- A record append causes data (the “record”) to be appended atomically at least once even in the presence of concurrent mutations, but at an offset of GFS’s choosing
Component failures:
- check with checksums or record data ID
GFS applications can accommodate the relaxed consistency model with a few techniques:
- replying on appends rather than overwrites
- checkpointing
- writing self-validating, self-indentifying records Most applications mutate files by appending rather than overwriting
Leases and Mutation Order
- Mutation operation that changes the contents or metadata of a chunk such as write or an append operation
- Each mutation is performed at all the chunk’s replicas
- Leases to maintain a consistent mutation across replicas
- Master grants a chunk lease to one of the replicas which we call the primary
- Primary picks a serial order for all mutations to the chunk. All replicas follow this order when applying mutations
- Global mutation order is defined first by lease grant order chosen by the master, and within a lease by serial numbers assign by primary
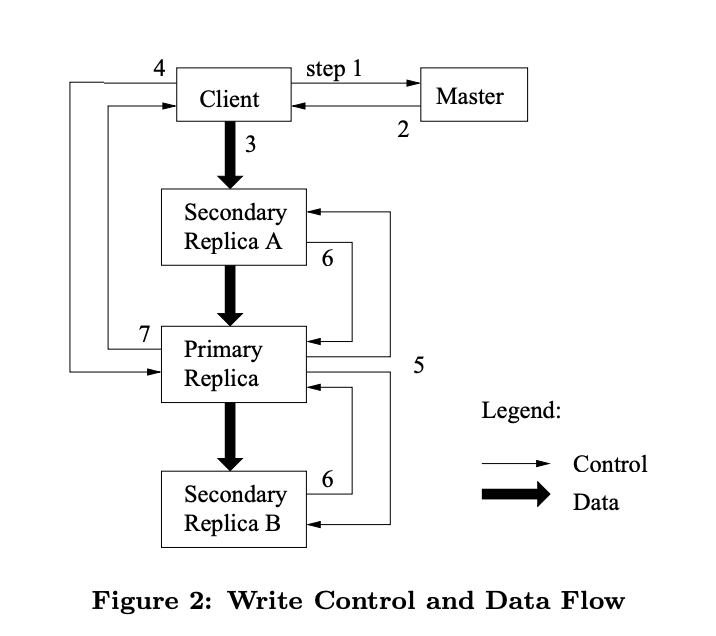
Data Flow
- Decouple data flow from the flow of control
- Control flows from the client to primary then secondaries
- Data is pushed linearly along a carefully picked chain of chunkservers in a pipelined fashion
Atomic Record Appends
Record append - client specifies only the data, GFS appends it to the file at least once atomically at an offset of GFS’s choosing and returns that offset to the client
- Traditional write, client specifies teh offset at which data is to be written
- Concurrent writes to the same region are not serializable
Snapshot
- makes a copy of a file or directory tree almost instantaneously, while minimizing any interruptions of ongoing mutations
- Uses use it to quickly create branch copies of huge datasets (and often copies of those copies, recursively)
Fault tolerance
High avaliablity
- fast recovery
- chuck replciaiton on diff racks
- Master replication, operation log and checkpoints are replicated on multiple machines