Model Types
- Relational
- nonrelational
- Document Based: use cases where data comes in self-contained documents and relationships between one document and another are rare
- Graph-like Data Models: use cases where anything is potentially related to everything
Historical Models
- Hierarchical model - represented all data as a tree of records nested within records
- Worked well for one-to-many relationships but not many-to-many relations
- Network model - generalization of hierarchical model, the difference is that a record could have multiple parents rather than one.
Relational Model
Motivations
- Used for business data processing: typically transaction processing and batch processing
- Goal, hide implementation detail behind a cleaner interface
- SQL is declarative language that hides the application developer from having to rewrite their query for optimizations or to use indexes
Pros
Cons
- impedence mismatch - when application models don’t match with database models
- ORMs attempt to reduce the boilerplate code for translating models, but can’t completely hide the differences
NoSQL
Motivations
- Greater scalability than relational database, eg. for write throughput
- A widespread preference for free and open source software
- Specialized query operations that are not well supported by the relational model
- Frustration with the restrictiveness of relational schemas and a desire for a more dynamic and expressive data model
Pros
- Lack of schema - provides more schema flexibility
- Locality - data that is typically grouped together are grouped in documents, this reduced the amount of database fetches
Cons
- Lack of schema - causes impedence mismatch, but as shown before it can also be more useful
Application Design
When choosing which database to use, the best choice of technology may differ from another use case. The idea of polygot persistenceis utilizing multiple different types of databases for different types of data.
Example use cases of various databases from Martin Fowler:
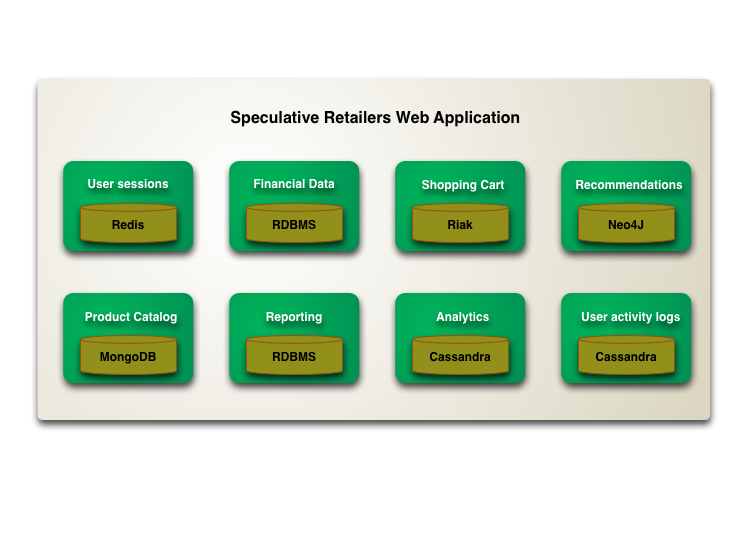
Data Modeling Design
Key factors to consider
- Locality of data
- Self contained data (eg. resume) may be more appropriate for JSON representation and document-oriented databases
- Reduces the amount of queries to the database compared to relational databases with joins
- Avoid plain-text strings as identifiers
- Localization support
- Better search, ties to metadata
- Avoids ambiguity, duplication
- Normalization - removing duplicate data within the database
- Although not a hard fast rule. Duplication can help with optimizing performance through locality
- For document databases, support for joins is weak and may require emulating a join by making multiple queries to the database.
- In this case, the other documents should be small and changing enough that the application can simply keep them in memory to shift the join from database to application code.