Source: https://dl.acm.org/doi/pdf/10.1145/121132.121137
Abstract
- New technique for disk storage called a log-structure file system
- A log-structured file system writes all modifications to disk sequentially in a log-like structure, thereby speeding up file writing and crash recovery
- The log is the only structure on disk
- contains indexing information for efficient reads
- In order to maintain large free areas on disk
- divides into segments and use segment cleaner to compress the live information from heavily fragmented segments
- Sprite LFS can use 70% of the disk bandwidth for writing, wheras Unix file systems typically can use only 5-10%
Goals
- Maintain large free areas on disk
- Speed up file writing and crash recovery by batching writes
- Higher utilization of disk bandwidth
Design for file systems of the 1990’s
Three components of tech are significant for file system design: processsor, disks, and main memory
- Processors rapid improvements
- Disk improvements to size not necessarily performance
- Main memory exponential rate improvement
Larger file cahes
- absorb greater fraction of read requests
- serve as write buffers where large numbers of modified blocks can be collected before writing to disk
Workloads
- For office and engineering:
- Small file accesses tend to dominate use case which results in small random disk I/Os
- For supercomputing:
- Dominated by sequential accesses to large files
Existing problems
Two general problems
- Spread information around the disk in a way that causes too many small accesses
- File systems tend to write synchronously
- Application must wait for the write to complete
Log-structured file systems
Fundamental idea:
- Improve write performance by buffering a sequence of file system changes in the file cache and then writing all the changes to disk sequentially in a single disk write operation
- For workloads that contain many small files, a log-structured file system converts the many small synchronous random writes of traditional file systems into large asynchronous sequential transfers that can utilize nearly 100% of the raw disk bandwidth Challenges
- How to retrieve information from the log
- How to manage free space on disk so that large extents of free space are always available for writing new data

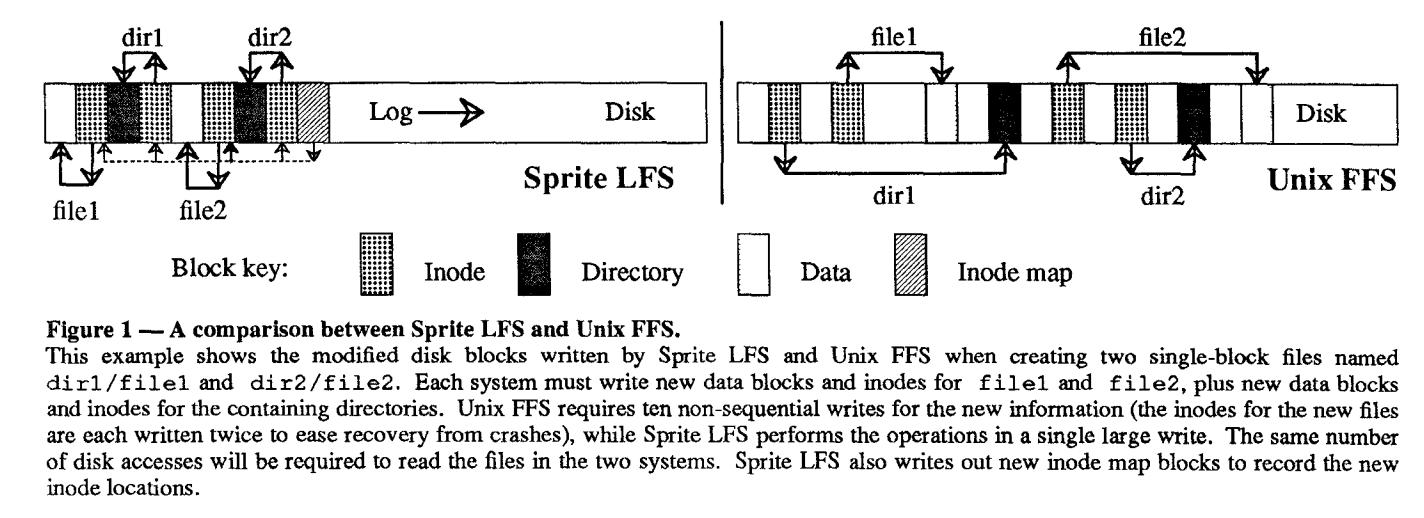
File Location and Reading
Sprite LFS outputs index structures in the log to permit random-access retrievals
- Sequential scans are NOT required!
- Goal is to match or exceed the performance of Unix FFS Sprite LFS outputs index structures in the log to permit random-access retrievals
- Sprite LFS doesn’t place inodes at fixed positions; they are written to the log
- Sprite LFS uses a data structure called an inode map to maintain the current location of each inode - fixed region in memory
Free Space Management: Segments
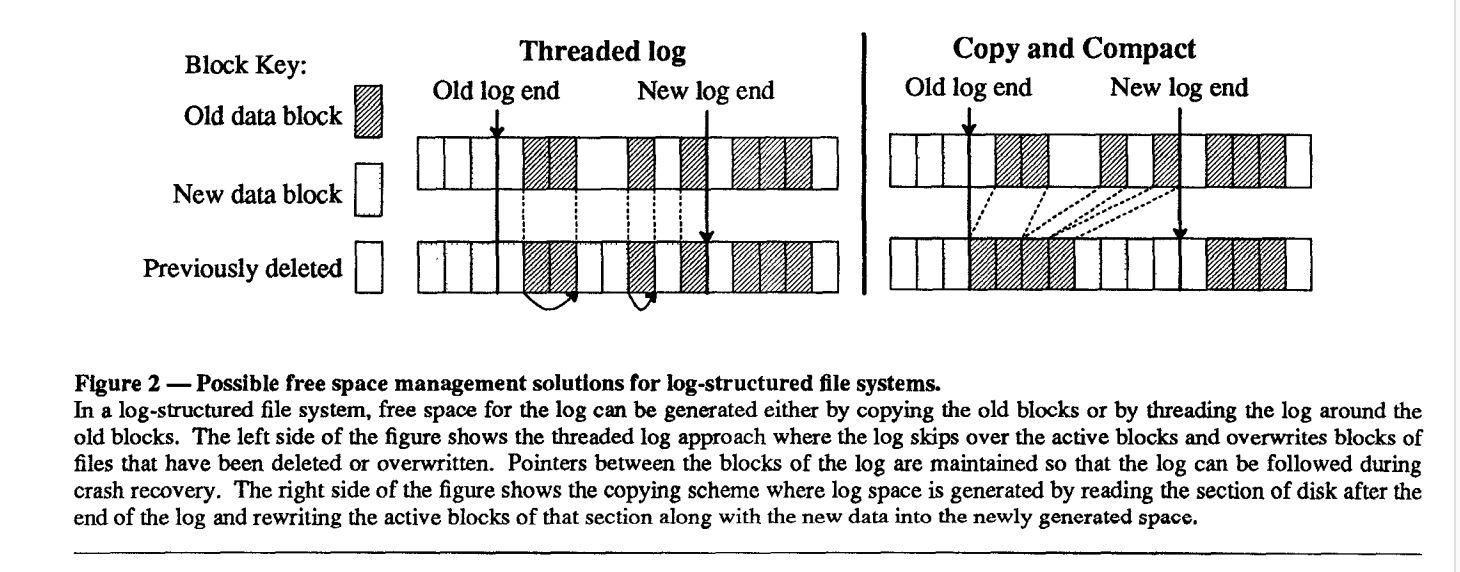
How to deal with internal fragmentation:
- Either
- Threading - leave live data in place and thread the log through the free extents
- creates further fragments
- Copying - copy live data out of log in order to leave large free extents for writing, assuming the data is written back in a compacted form
- high cost, particularly for long-lived files Sprite LFS uses a combination of threading and copying
- Threading - leave live data in place and thread the log through the free extents
- Disk is divided into large fixed-size extents called segments
- Any given segment is always written sequentially from its beginning to its end
- All live data must be copied out of a segment before the segment can be rewritten
- Log is threaded on a segment-by-segment basis
- The system can collect long-lived data together into segments, reducing the effect of copying long-lived data repeatedly Segment size either 512kb or 1mb
Segment cleaning mechanism
- Segment cleaning - the process of copying live data out of a segment
- Three step process:
- Read a number of segments into memory
- Identify the live data
- Write the live data back to smaller number of clean segments
- Segment summary block - identifies each piece of information that is written in the segment, helps keep track of live data for cleaning
- Once a block’s identity is known, its liveness can be determined by checking the file’s inode or indirect block to see if the appropriate block pointer still refers to this block
- Because of this, there’s no need for a free-block list or bitmap in Sprite
- Doubles as a log with versioning for files
Segment cleaning policies
- write cost - average amount of time the disk is busy per byte of new data written, including cleaning
- used to compare cleaning policies
- 1.0 = perfect - new data written at full disk bandwidth with no latency
- 10 = 1/10 of the disk’s maximum bandwidth is actually used
Simulation Results
- Authors built a file system simulator to analyze different segment cleaning policies
- Two test access patterns:
- Uniform: random
- Hot-and-cold: hot spots
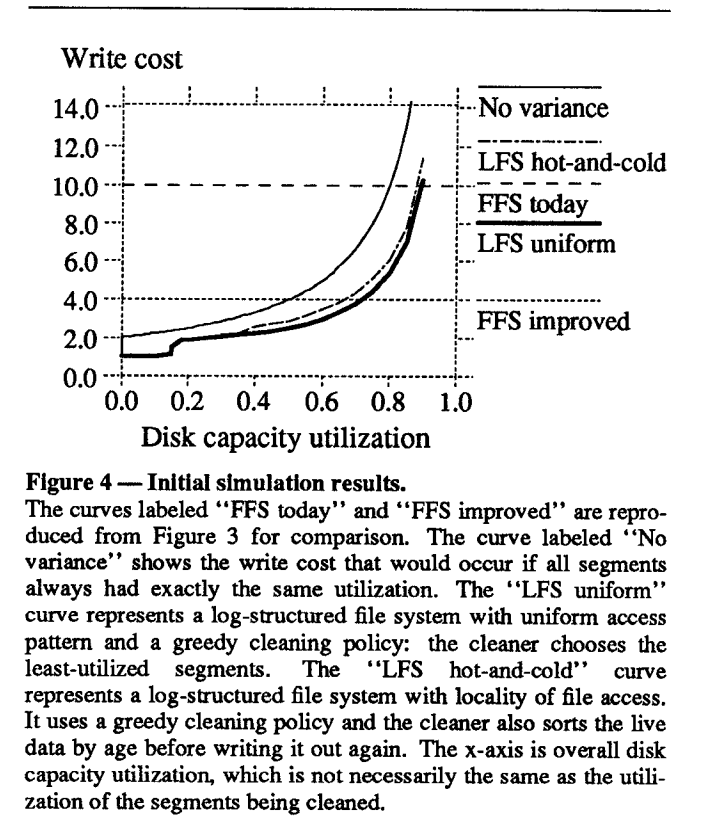
- Insights:
- Free space in cold segment is much more valuable than space in a hot segment because once a cold segment has been cleaned it will take a long time before it accumulates the unusable free space
- cold data will get to “keep” free blocks for a long time
- Free space in cold segment is much more valuable than space in a hot segment because once a cold segment has been cleaned it will take a long time before it accumulates the unusable free space
- Convinced authors to implement a cost-benefit approach to cleaning policy in Sprite LFS…
Segment usage table
In order to support the cost-benefit cleaning policy, Sprite LFS maintains a data structure called segment usage table
- For each segment, the table records
- The number of live bytes in the segment
- if falls to 0, the segment can be reused without cleaning
- The most recent modified time of any block in the segment
- The number of live bytes in the segment
Crash Recovery
Checkpoints
- Position in the log at which all the file system structures are consistent and complete
- Two-phase process to create a checkpoint
- Writes out all modified information to the log
- Writes a checkpoint region to a special fixed position on disk
- contains the addresses of all the blocks in the inode map and segment usage table, time, and pointer to the last segment written
- During reboot, Sprite LFS reads the checkpoint region and uses that information to initialize its main-memory data structures
Roll-forward
- In addition to checkpointing, roll-forward is a process where Sprite LFS scans through the log segments that were written after the last checkpoint
- During roll-forward, Sprite LFS uses the information in the segment summary blocks to recover recently-written file data
- Issue: inode has been written to log with a new reference count while the block containing the corresponding directory entry has not been written
- Sprite LFS has a special record in log for each directory change called directory operation log