Abstract
- SplitFS - file system for persistent memory (PM) that reduces software overhead compared to state-of-the-art PM file systems
- Split of responsibilities between a user-space library file system and an existing kernel PM file system
- User-space library file system handles data operations by intercepting POSIX calls, memory-mapping underlying file, and serving the read and overwrites using processor loads and stores
- Metadata operations are handled by the kernel PM file system
open(),close(), any operation that modifies file metadata- User space library can’t enforce this across processes
- Split of responsibilities between a user-space library file system and an existing kernel PM file system
Background
Persistent Memory
- New memory technology that offers durability and performance close to that of DRAM
- Byte addressable
- large storage size
Direct Access (DAX) and Memory mapping
- Linux ext4 file system introduced a new mode called Direct Access (DAX) to help users access PM
- DAX file systems eschew the use of page caches and rely on memory mapping to provide low-latency access to PM
mmap()in ext4 DAX maps one or more pages in the process virtual address space to extents on P
Goals
- Low software overhead
- Transparency
- Does not require the application to be modified any way to obtain better perf
- Minimal data copying and write IO
- Needed for strong guarantees like atomic ops
- Low implementation complexity
- Flexible guarantees
- Choice of crash-consistency guarantees
SplitFS
Benefits of split architecture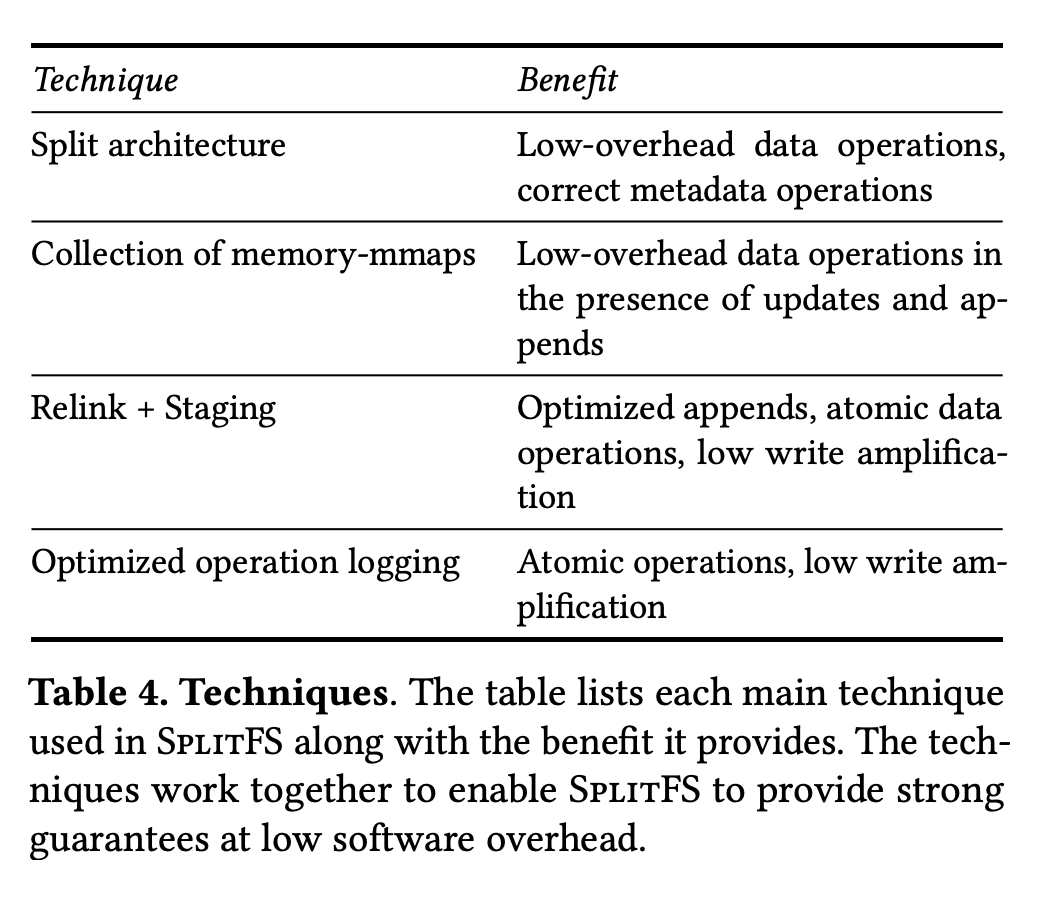
- Take advantage of mature code in ext4 DAX (kernel PM file system) for metadata operations
- User-space library file system in SpitFS allows each application to run with on of three consistency modes (POSIX, sync, strict)
Split FS Modes
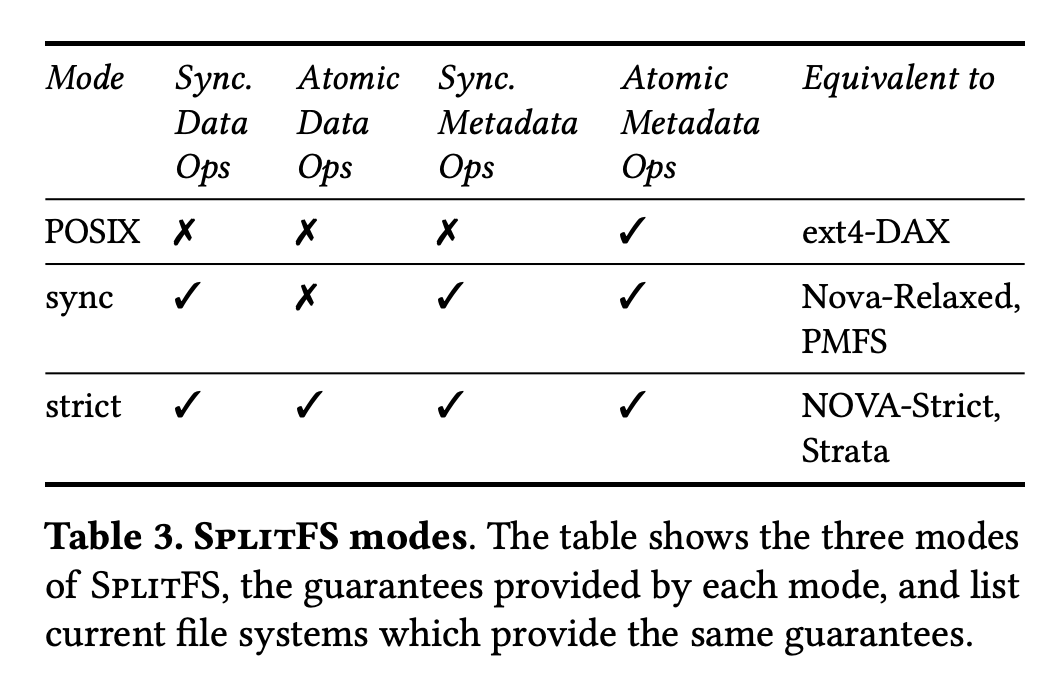
- POSIX mode - metadata consistency
- Sync mode - on top of POSIX, ensure operations to be synchronous
- Strict mode - on top of Sync mode, ensure operations to be atomic
Relink primitive
Used to optimize file appends and atomic data operations, without paging faults or data copying Staging
- SplitFS uses temporary files called staging files for both appends and atomic data operations
- This is where the app writes data directly with loads/stores
- SplitFS doesn’t log when writing to staging files
- Staging files are not part of the “real” namespace so the real file metadata is never pointed to it, hence it doesn’t corrupt the FS Relink
- on a
fsync(), all staged appends of a file must be moved to the target file- In strict mode, overwrites have to be moved as well
- One way to move the staged appends to the target file is to allocate new blocks and then copy appended data to them. Although this leads to write amplification and high overhead…
- Their solution is introducing relink primitive
- Relink logically moves PM blocks from staging file to target file without incurring any copies.
relink(file1, offset1, file2, offset2, size)- Moves data from
offset1offile1tooffset2offile2. Iffile2already has data atoffset2, existing data blocks are de-allocated.- Atomicity is ensured by wrapping the changes in ext4 journal transaction
- Relink is a metadata operation and does not involve copying data when the inovlved offsets and size are block aligned
- ext4 updates inode data to point to staged block
Optimized logging protocol
In strict mode, all data and metadata operations in SplitFS are atomic and synchronous
- To achieve this, SplitFS logs every operation in an Operation Log and use logical redo logging to record the intent of each operation
- All log entries consist of a single cacheline in the common case, SplitFS can support up to 2M ops without clearing the log
- Only logs the metadata operations that need to be crash-consistent, does not log the data itself (relink)