Question
How does core slicing differ from traditional virtualization (e.g., in Xen)?
Abstract
- VMs are the basis of resource isolation in today’s public clouds
- But can we trust the cloud provider’s hypervisor
- Motivated hardware extensions for “confidential VMs” that seek to remove the hypervisor from the trusted computing base
- However, the hypervisor retains control of resource management and is vulnerable to hypervisor-level side channel attacks
- Observed that typical cloud VMs run with static allocation of memory and discrete cores and increasingly rely on I/O offload
- Negates the need for a hypervisor
- They present a new design: core slicing
- Enable multiple untrusted guest OSes to run on shared bare-metal hardware
- Introduce hardware extensions that restrict guests to a static slice of a machine’s cores, memory and virtual I/O devices, and delegate resource allocation to a dedicated management slice.
Introduction
- New generation of Trusted Execution Environment (TEE)
- Motivated by cloud workloads, their main feature is the ability to run “confidential Vms” inside the TEE
- Side channel attack - take advantage of the fact that the attacker and victim run on the same core and share a multitude of sometimes obscure microarchitectural components
- Although today’s confidential VM architectures remove privileges from the host hypervisor, it still retains a large degree of control over guest execution
- Introduce more robust TEE architecture, core slicing
- For infrastructure-as-a-service (IaaS) workloads
- Rather than making confidential guests share cores with an adversarial hypervisor, we give guest exclusive access to its own CPU cores
- Moves isolation boundary to the much more defensible and robust one, between processor cores
- Demonstrates how this boundary can be enforced
- Doesn’t prevent cross-core side channel, like CrossTalk
- Resource allocations are determined by a slice manager that runs on a dedicated core (ideally, a separate low-power processor)
- Responsible for starting and stopping slices and is untrusted by the guest
VMs in public clouds
Focusing on IaaS workloads, amazon EC2 and microsoft azure
- VMs are allocated at core granularity
- Amazon states that host cores are “pinned” to specific guest vCPUs and are not shared across guests
- Microsoft Azure doesn’t not oversubscribe customer vCPUs, “only oversubscribe servers running first-party workloads”
- Both providers have burstable VMs
- For workloads that are mostly idle with occasional bursts of CPU activity
- Requires hypervisor to perform time-slices to account for VM’s actual CPU utilization
- All other VMs have guaranteed allocation of physical CPUs, no need for hypervisor time-slicing
- Virtual I/O is becomming fully offloaded
- increaing deploy dedicated hardware “cards” that replace software I/O virtualization stacks, exposing virtual devices to guests directly via SR-IOV (Single Root I/O Virtualization).
- allows for a single physical PCIe device to be split into multiple virtual devices
- Amazon Nitro and Azure AccelNet enable low-overhead networking
- EC2 → direct access to NVMe
- Azure → SR-IOV
- increaing deploy dedicated hardware “cards” that replace software I/O virtualization stacks, exposing virtual devices to guests directly via SR-IOV (Single Root I/O Virtualization).
- Advanced VM features are not needed
- users only need a subset of features
- Bare-metal clouds
- Why?
- Avoid CPU overhead (“virtualization tax”) for memory-intensive workloads
- Need for predictable performance without any possible contention from other co-located VMs (or “noisy neighbors”)
- Why?
Design
Goals:
- Partition shared hardware at natural boundaries, such as whole cores
- Keep the trusted computing base small and simple, to permit a formally-verified implementation
- Support memory encryption and remote attestation features equivalent to confidential VMs
Overview
- Rather than VMs, partition a machine into multiple guest slices (sliceU)
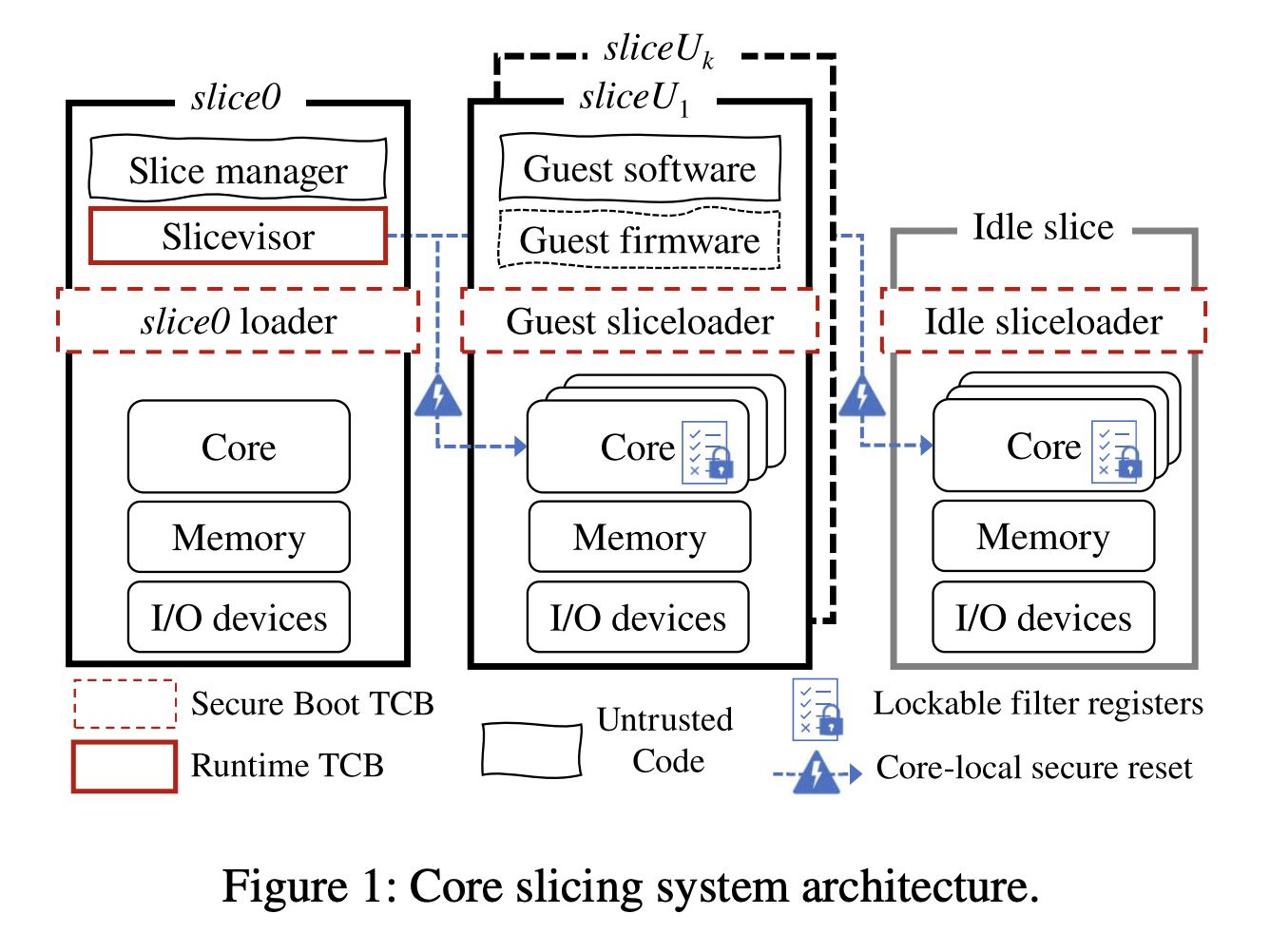
- Resources are allocated exclusively to a slice, this means that the guest code runs in the highest privilege level (hypervisor mode) and controls every CPU cycle executed on that core until the slice is terminated
- Key invariant is: at any given time no two slices may share access to the same resource
- To allocate resources the control slice (slice0) runs a slice manager to create and destroy user slices
- Its further divided into a small, privileged portion called the slicevisor
- This must be trusted by both cloud guests, the host and larger, unprivileged portion
- Its further divided into a small, privileged portion called the slicevisor
- To isolate resources, rely on new hardware mechanism, lockable filter registers
- Restricts access to resources from a given core
- Once configured and locked, these registers are read-only until the core is reset by core-local secure reset
- only a slicevisor can initiate a reset
- A trusted loader, the sliceloader is the first code to execute after a reset
- similar to a secure bootloader
- uses a slice table of configuration information maintained by slicevisor
Security
Eliminates interference between all slices (including control slice)
- The resources assigned to a slice are static from its creation until its termination
- A slice cannot access memory outside the slice, neither from cores nor via DMA (direct memory access)
- A slice cannot interrupt cores outside the slice
- A slice cannot access I/O devices outside the slice
- Only slice0 may terminate another slice or reset its cores
Threat Model
- Host (cloud provider) and guests (cloud users) are mutually distrusting
- Although with one caveat: a guest relies on the host to provide agreed resources, but can check at runtime that sufficient resources are available
- Cloud provider trusts the management stack executing in the control slice, which determine both which specific resources (CPU cores, memory, etc.) a guest is permitted to use, and for how long it executes
- Guests must trust only HW, the slicevisor, and the sliceloader
- Slicevisor ensures that resource allocations are disjoint and configures hardware protection mechanisms accordingly
- Slicevisor is also responsible for attesting guest slices and forms part of the attestation root of trust
- Sliceloader ensures that lockable filter registers are properly configured and locked before transitioning control to guest code on each core of a slice
- Slicevisor ensures that resource allocations are disjoint and configures hardware protection mechanisms accordingly
- Slicing partitions a machine at core granularity
- the only side channels possible are those that can be observed from another core;
- Side-channel leaks to sibling hardware threads or to a malicious hypervisor are impossible
- the only side channels possible are those that can be observed from another core;
Hardware support for core slicing
Key choice: expose the underlying physical resources directly to guest software
Introduce lockable filter registers that restrict the accessible resources by all software (including the most privileged) running on a given core
- see above
- Memory - lockable memory range registers
- Interrupts - lockable IPI destination mask register
- Cache - L1 cache is never shared by design, however, shared L2 or L3 caches may raise perfomance interference and security concerns
- core slicing uses cache partitioning for this
- I/O - IOMMU (input-output memory management unit) - translates virtual addresses to phyiscally memory addresses to protect against DMA attacks
Slice Management
Slice0 - software stack responsible for resource allocation, slice lifetime, and other runtime services
- requirements:
- Has hardware privilege separation
- Is able to trigger secure resets of guest cores
- Shares some memory, not necessarily cache-coherently, with those cores.
- Doesn’t allocate resources, but checks the correctness of resource assignments provided by the unprivileged slice manager