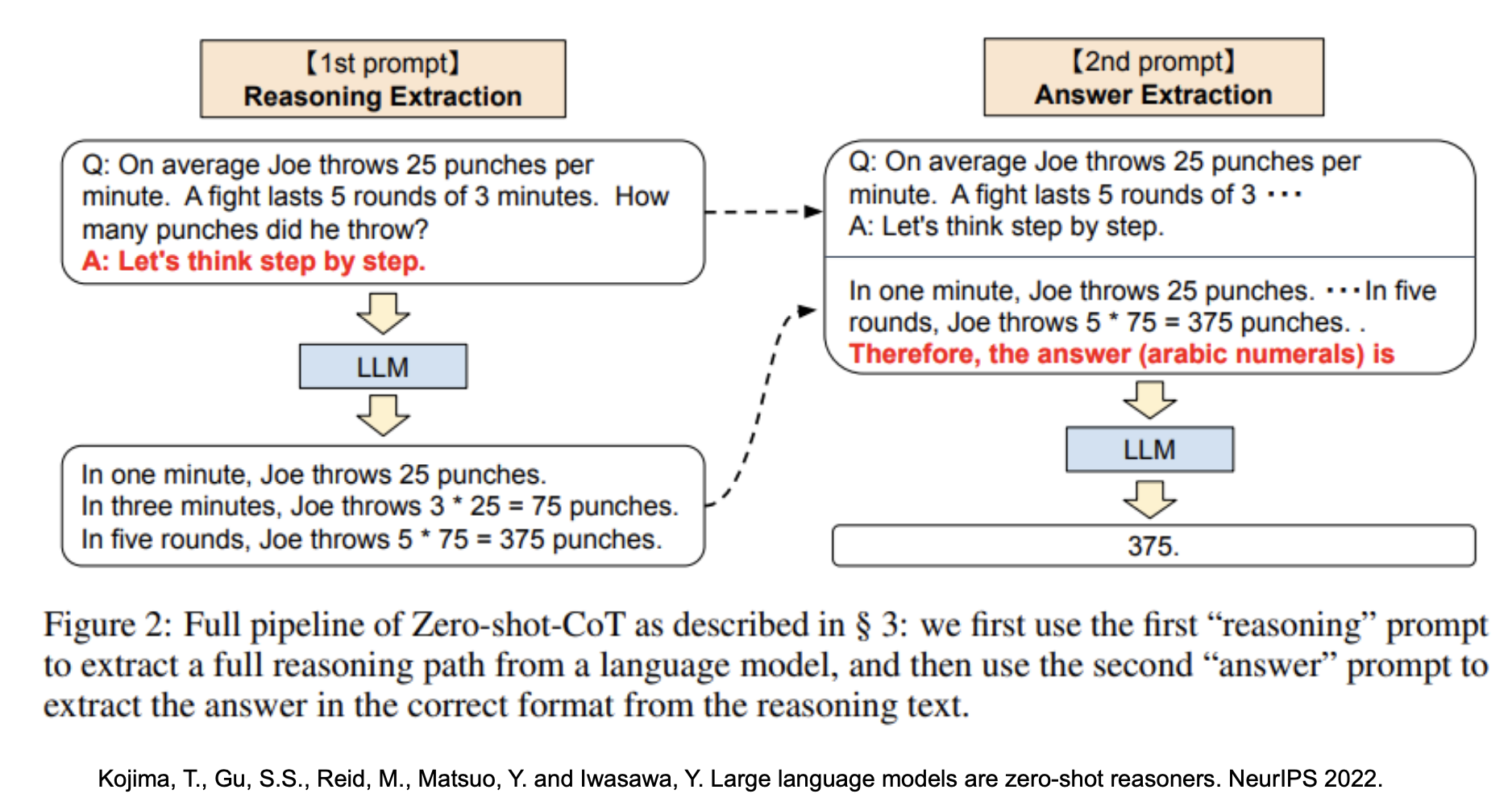
What is LLM reasoning?

Example

Overall design
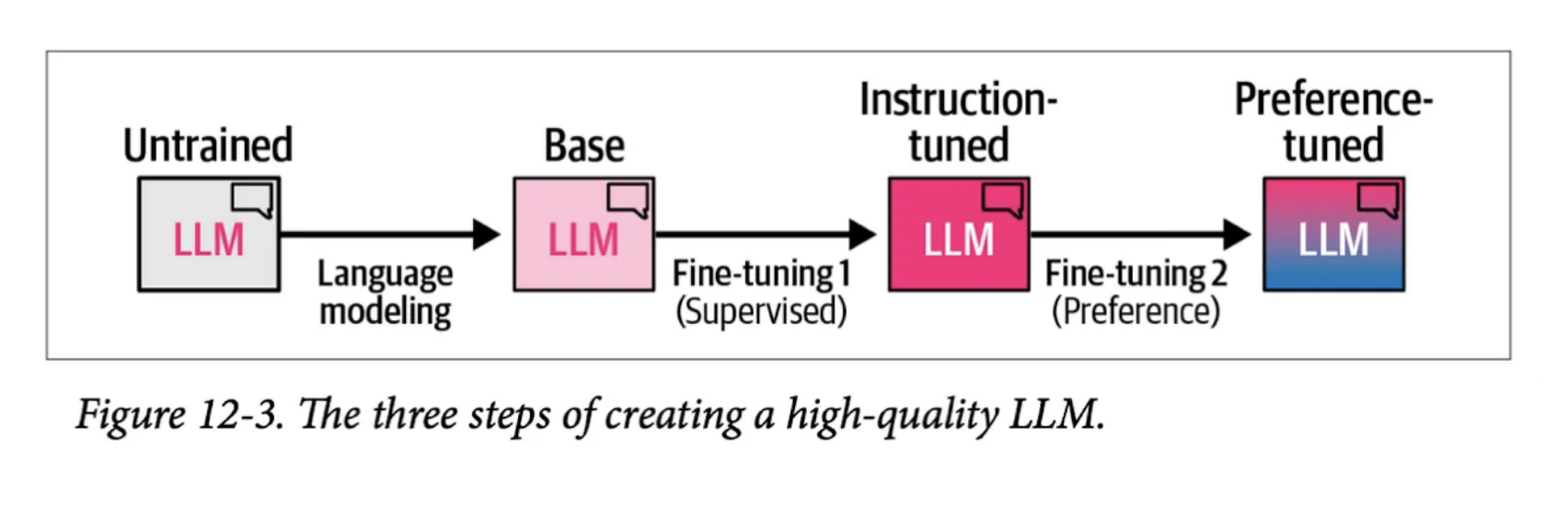
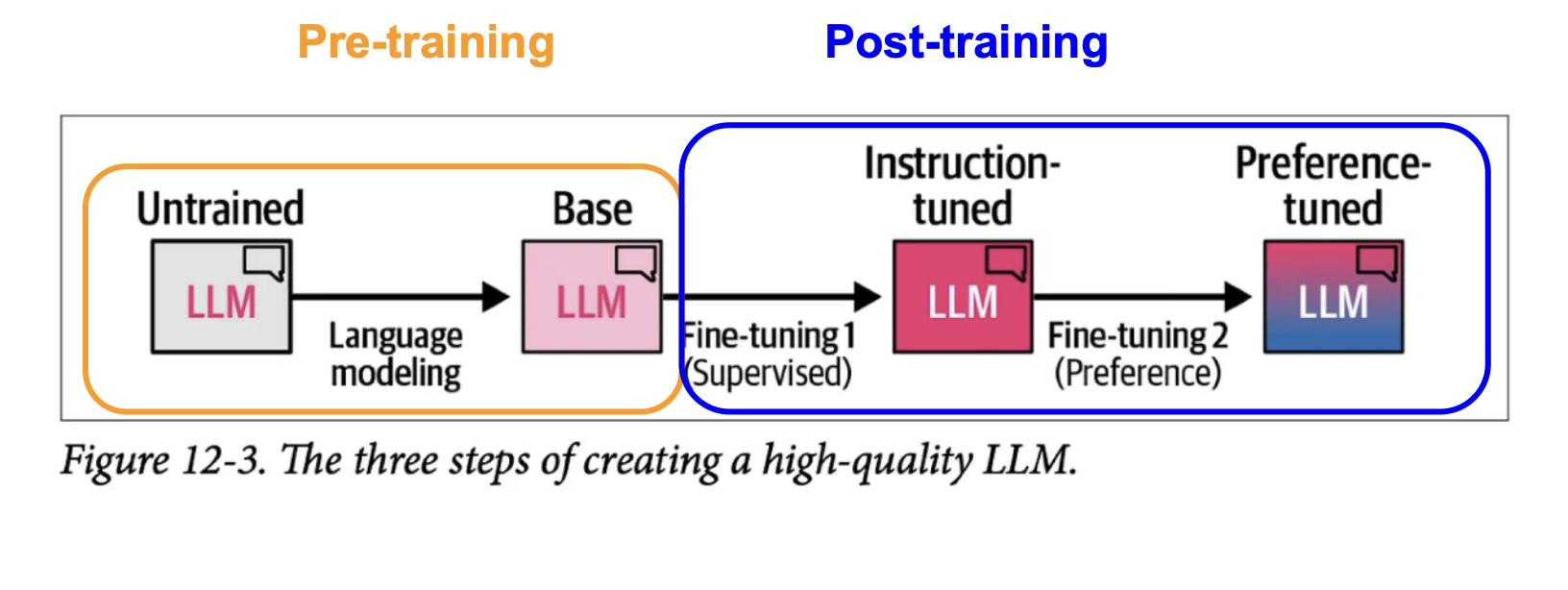
How “normal” LLMs are created
DeepSeek’s Process
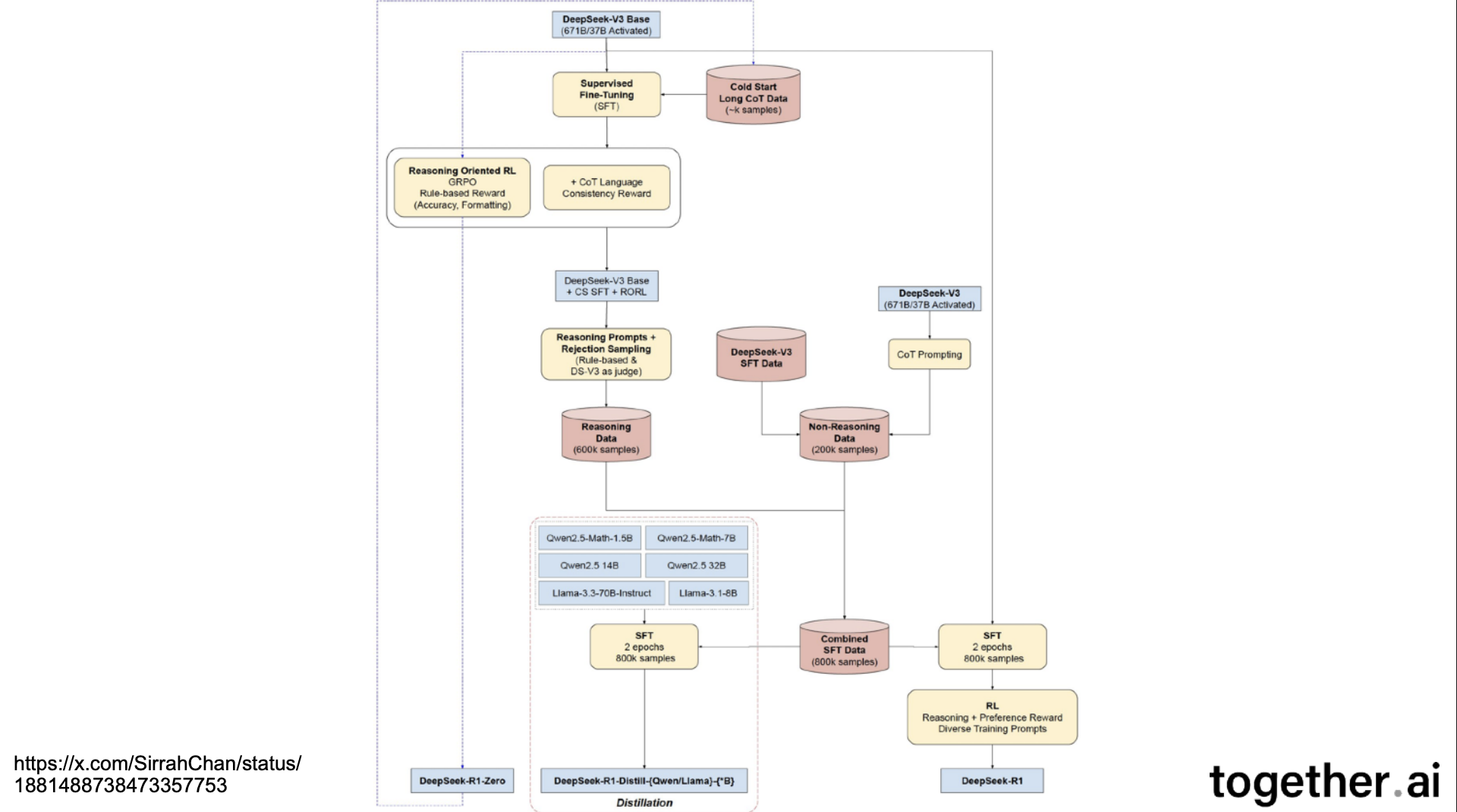
What is different with R1?
They used a different post-training recipe on the base model!
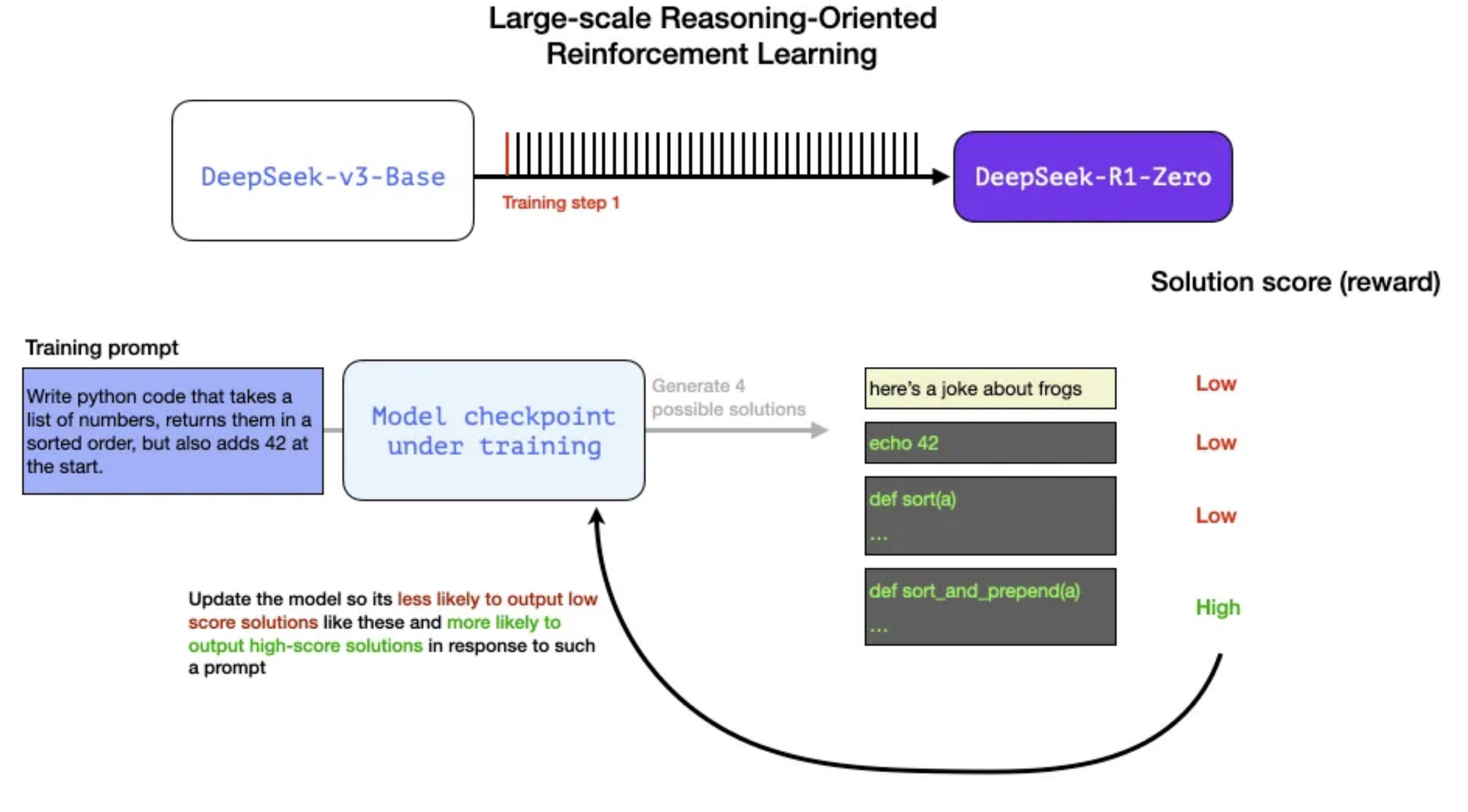 Optimization solution score is fed back into the model for training
Optimization solution score is fed back into the model for training
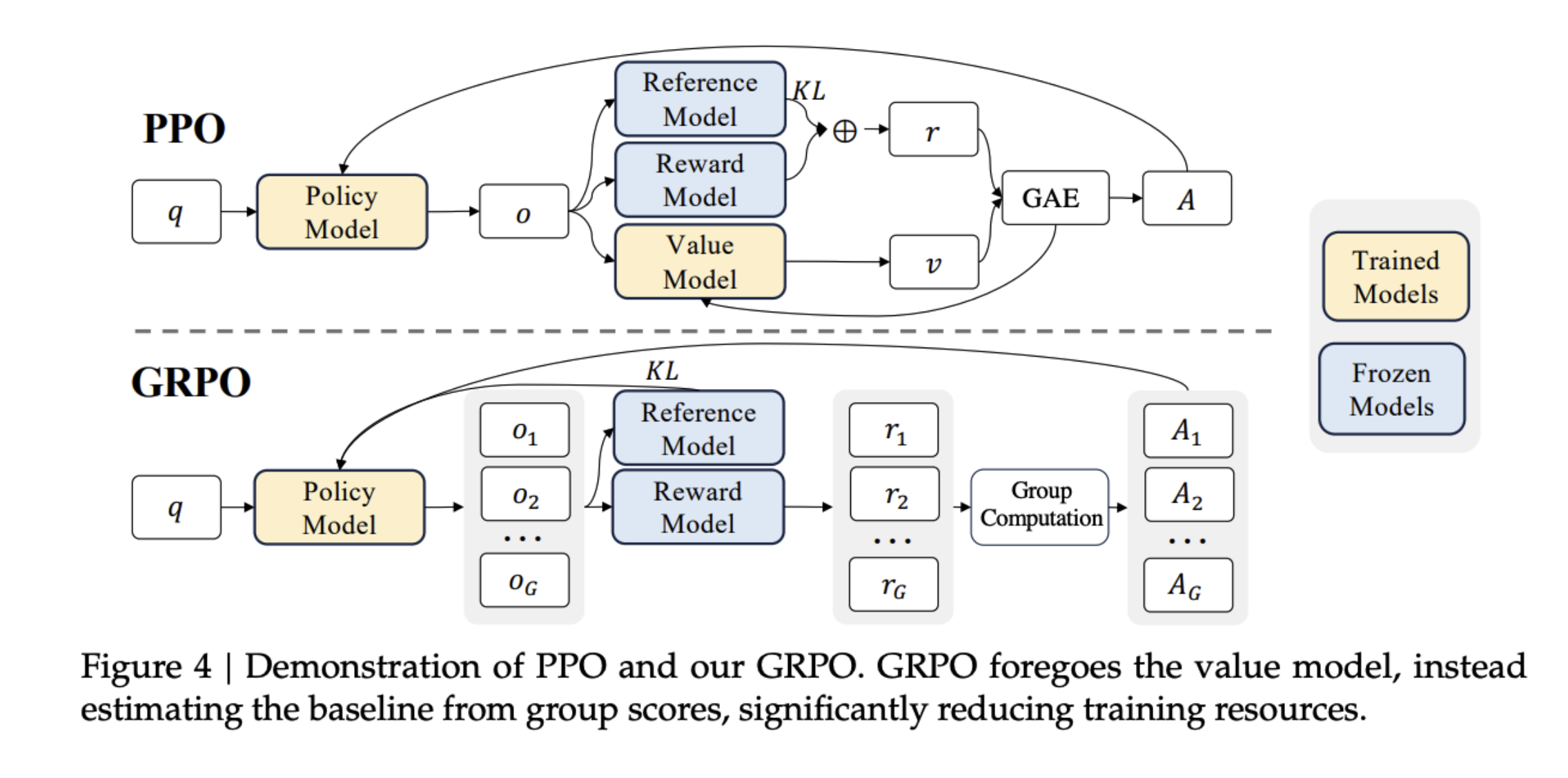 DeepSeek’s training is entirely reinforcement-learning-based, with no supervised fine-tuning.
DeepSeek’s training is entirely reinforcement-learning-based, with no supervised fine-tuning.
GRPO allows them to:
- Scale efficiently across massive reasoning models,
- Avoid instability from learning value functions,
- And use relative, group-based rewards to encourage better reasoning behaviors. In short:
GRPO = PPO without the value model, replacing learned baselines with group-based comparisons to stabilize and speed up RL for large language models.
Prompt Used for Reasoning RL Training

It learns to think!
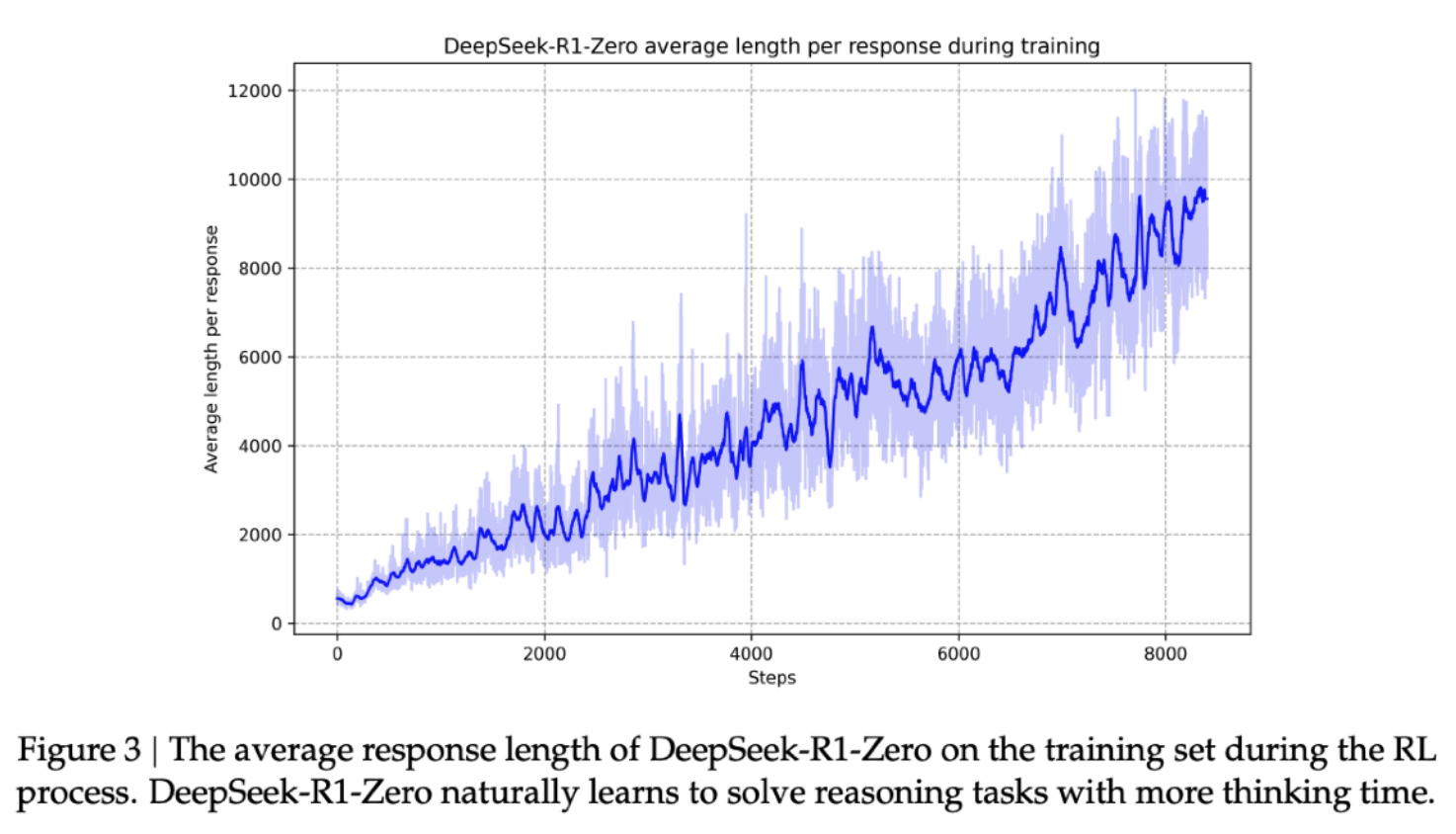
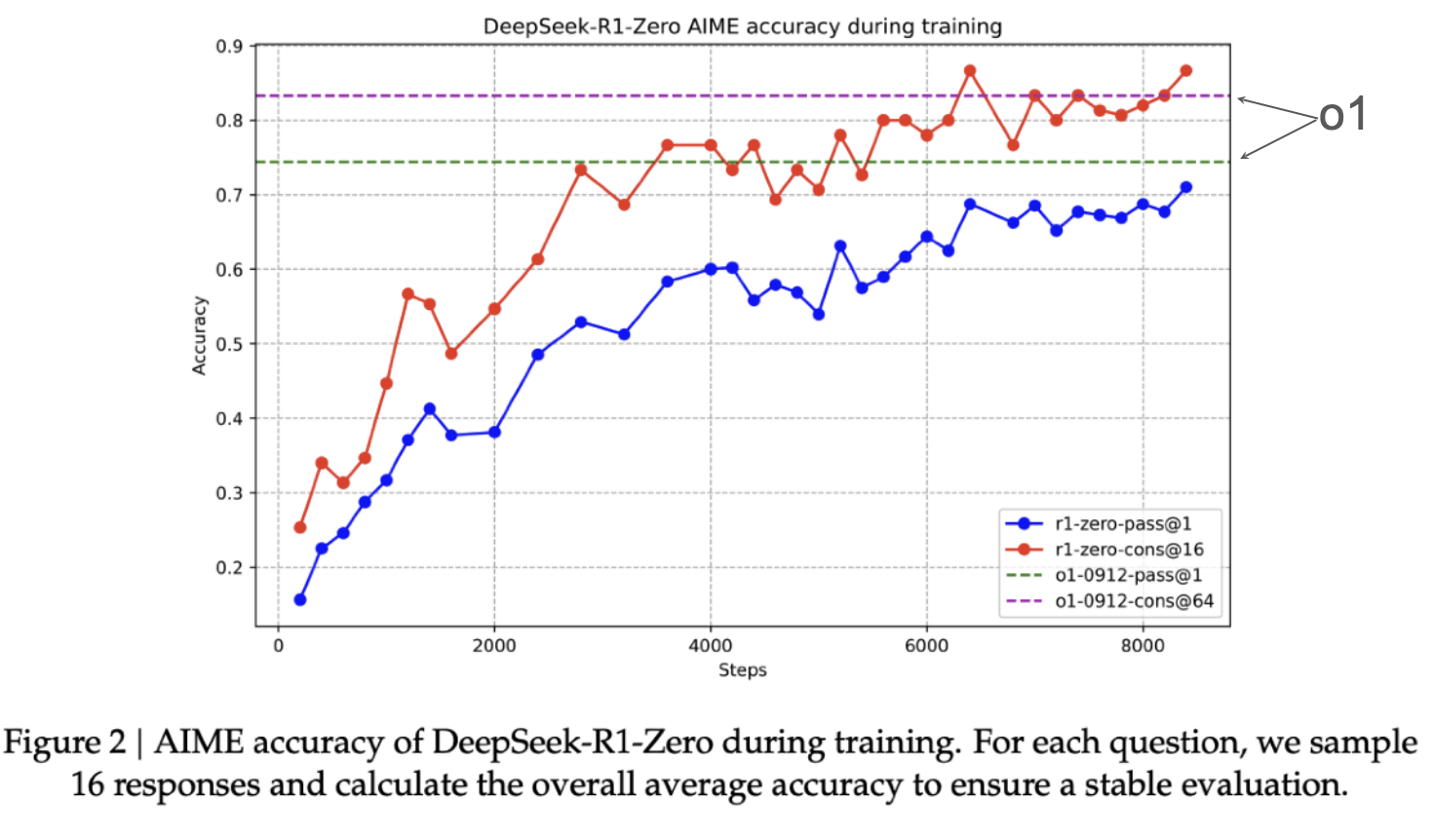 The result of this RL process is that it’s starts to spend more time reasoning through out training
The result of this RL process is that it’s starts to spend more time reasoning through out training
Purely RL is not enough (DeepSeek-R1-Zero)
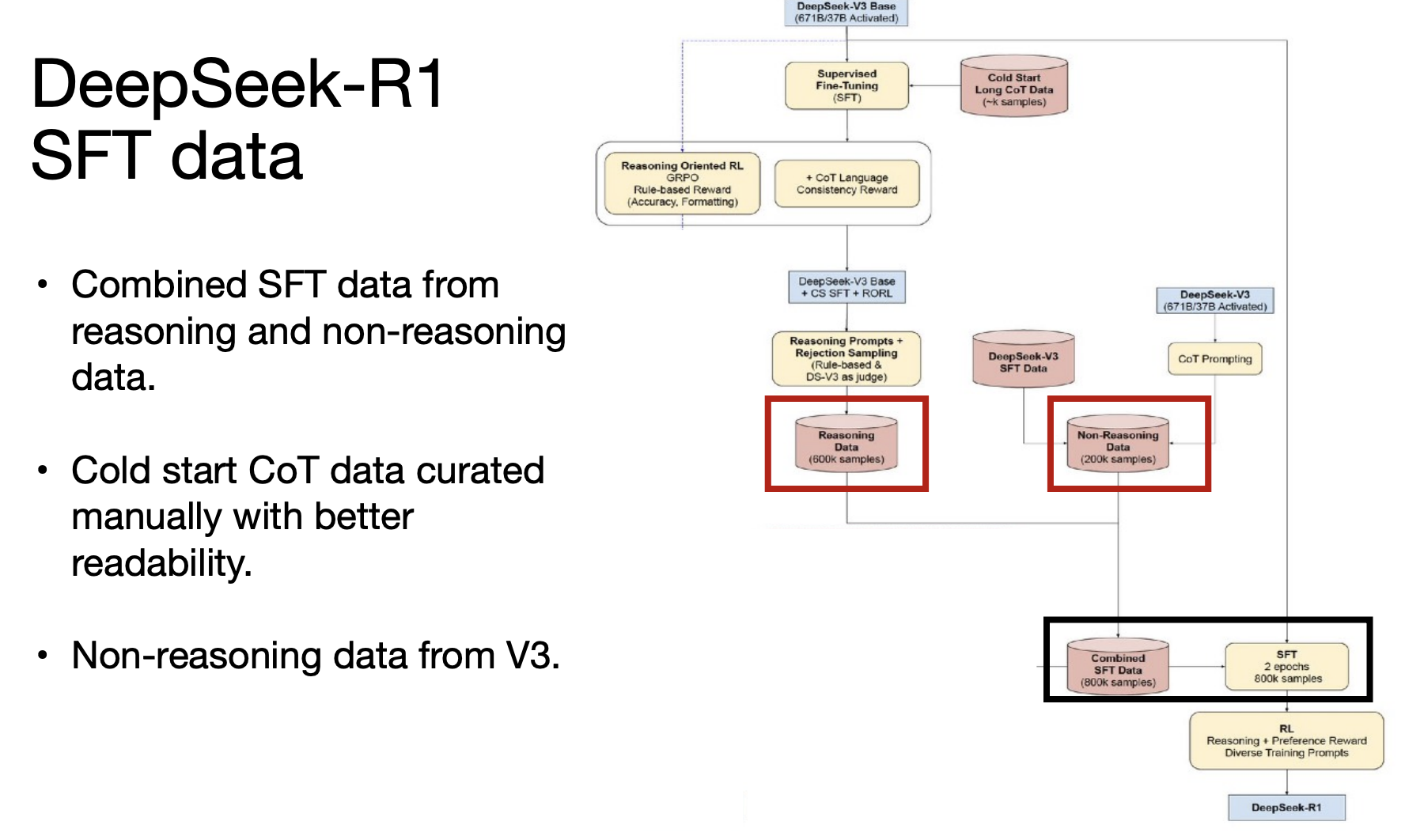
 DeepSeek-R1 uses some SFT data to help with readability and language mixing problems in Zero
DeepSeek-R1 uses some SFT data to help with readability and language mixing problems in Zero
Demystifying Delays in Reasoning: A Pilot Temporal and Token Analysis of Reasoning Systems
Reasoning and deep research study


Implications
- Tool calling, especially web search, accounts for most of the latency for GPT-5 and Open Deep Research
- Insignificant for o3
- Tool calls can often be parallelized
- Higher token counts (e.g., longer reasoning chains) can improve generation quality, but comes with high latency and cost
- More on tool and agents next Monday