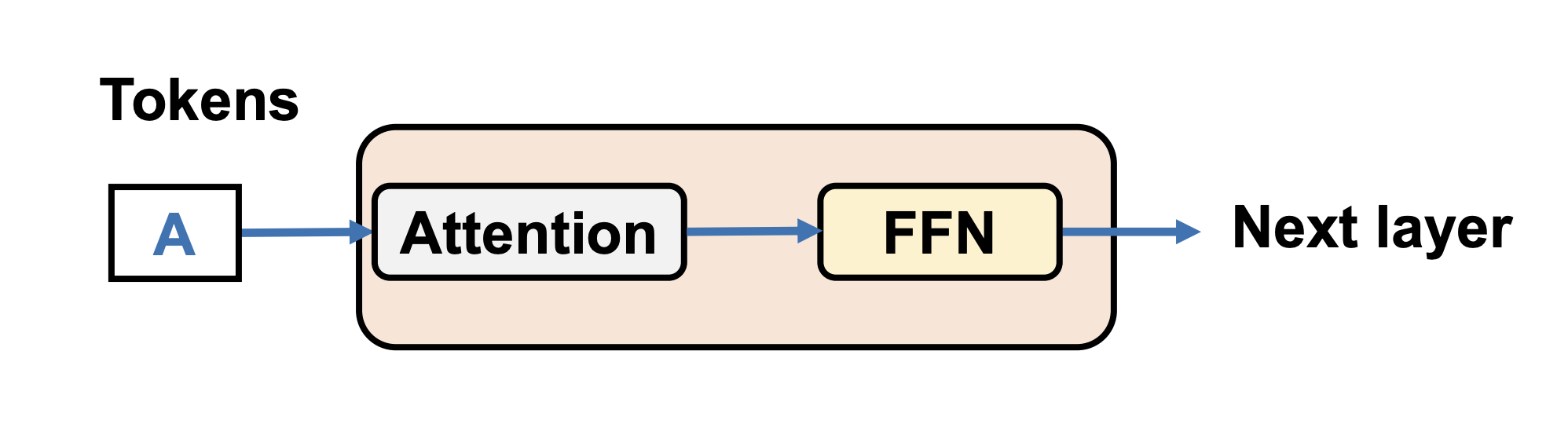
Components of Transformer-Based LLMs
- Each layer contains two modules
- Attention
- FFNs
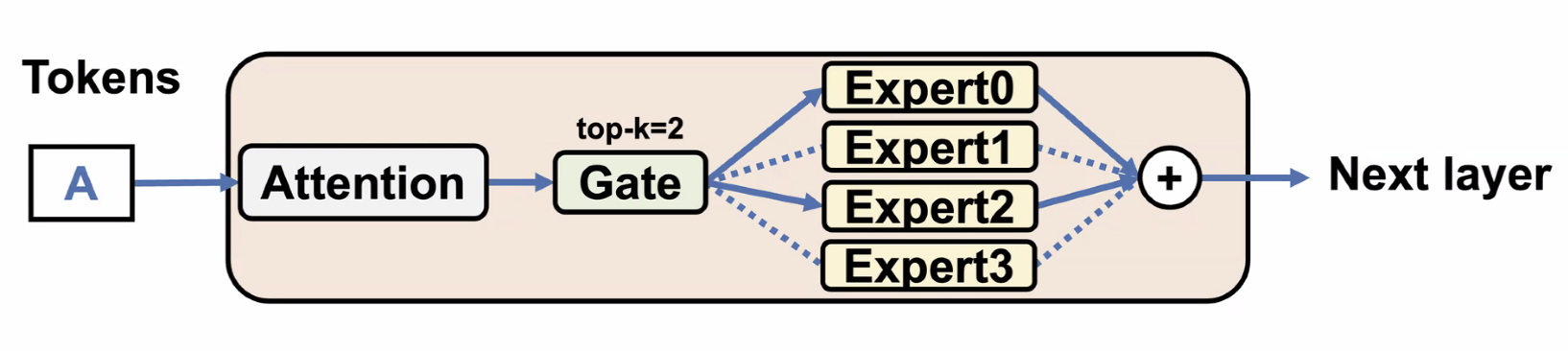
Mixture-of-Experts (MoE)
- Replace FFNs with multiple FFNs each called “expert”, an expert in a domain
- Each token is only sent to top-k experts
- increases sparsity
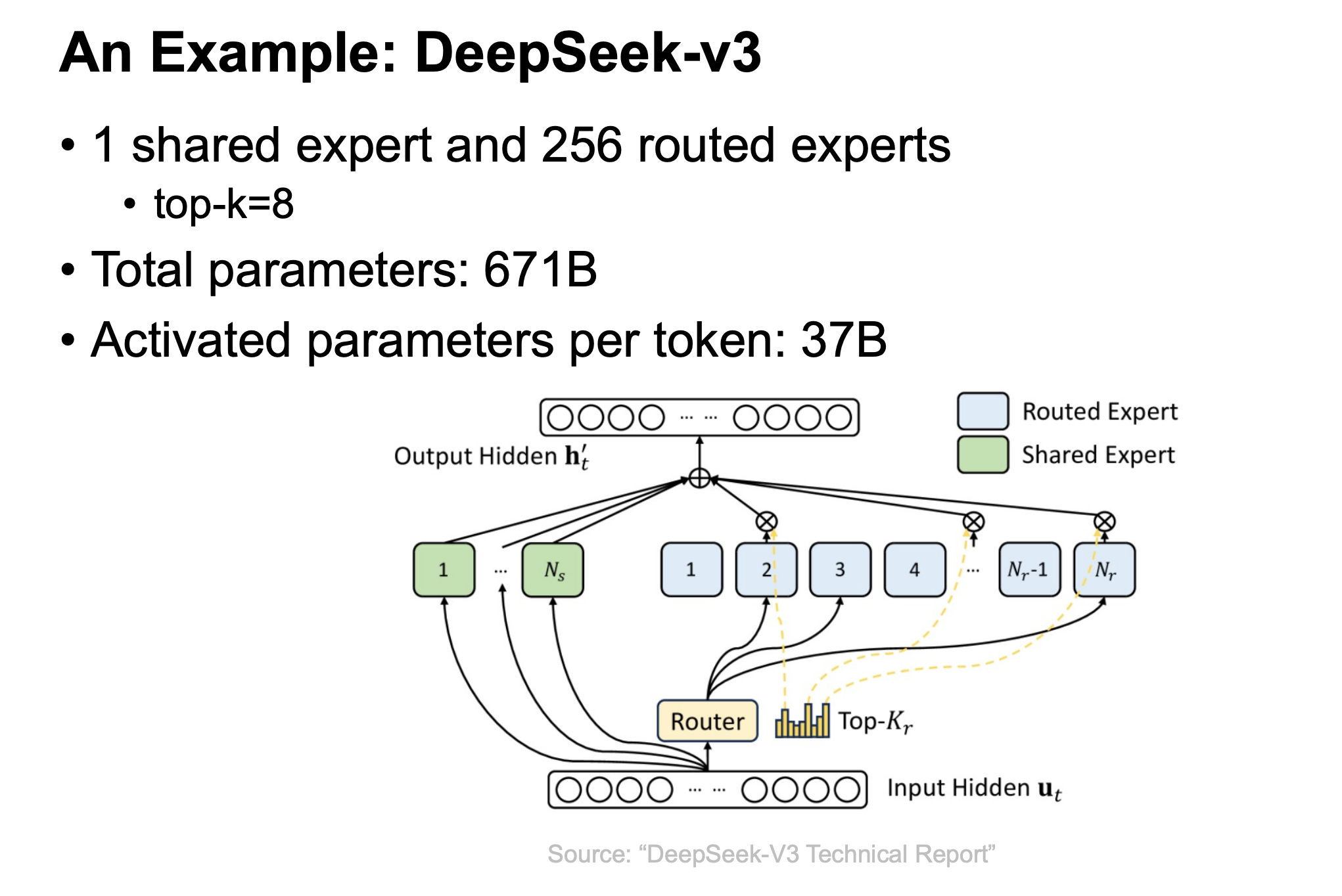
Latest Large-Scale LLMs
- Doubao-Seed-1.6
- DeepSeek v3.1
- GPT-OSS
- Gemini 2.5 Pro
All use MoE
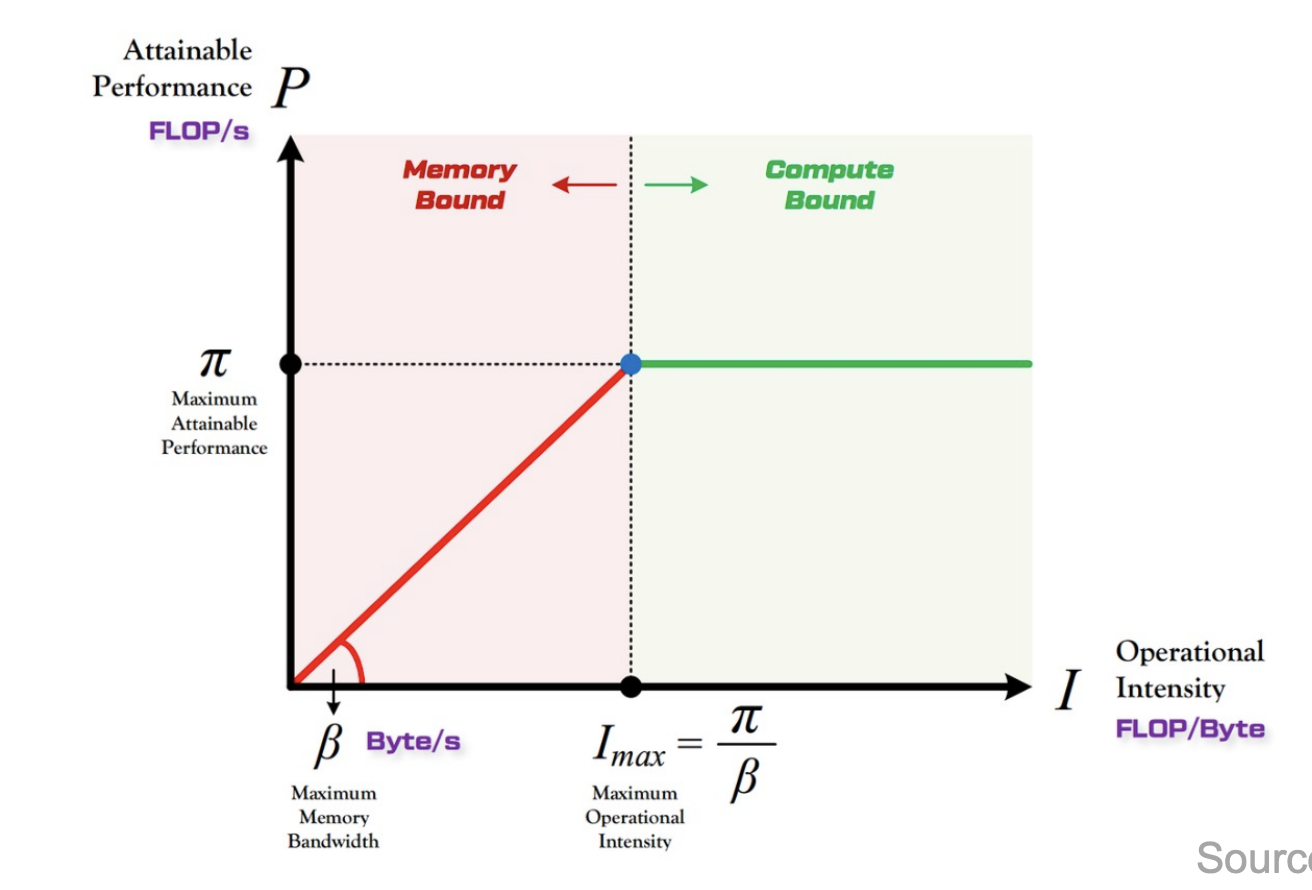
Roofline Model
- Operational Intensity: the number of operations per byte of memory traffic
- Memory-bound vs. Compute-bound
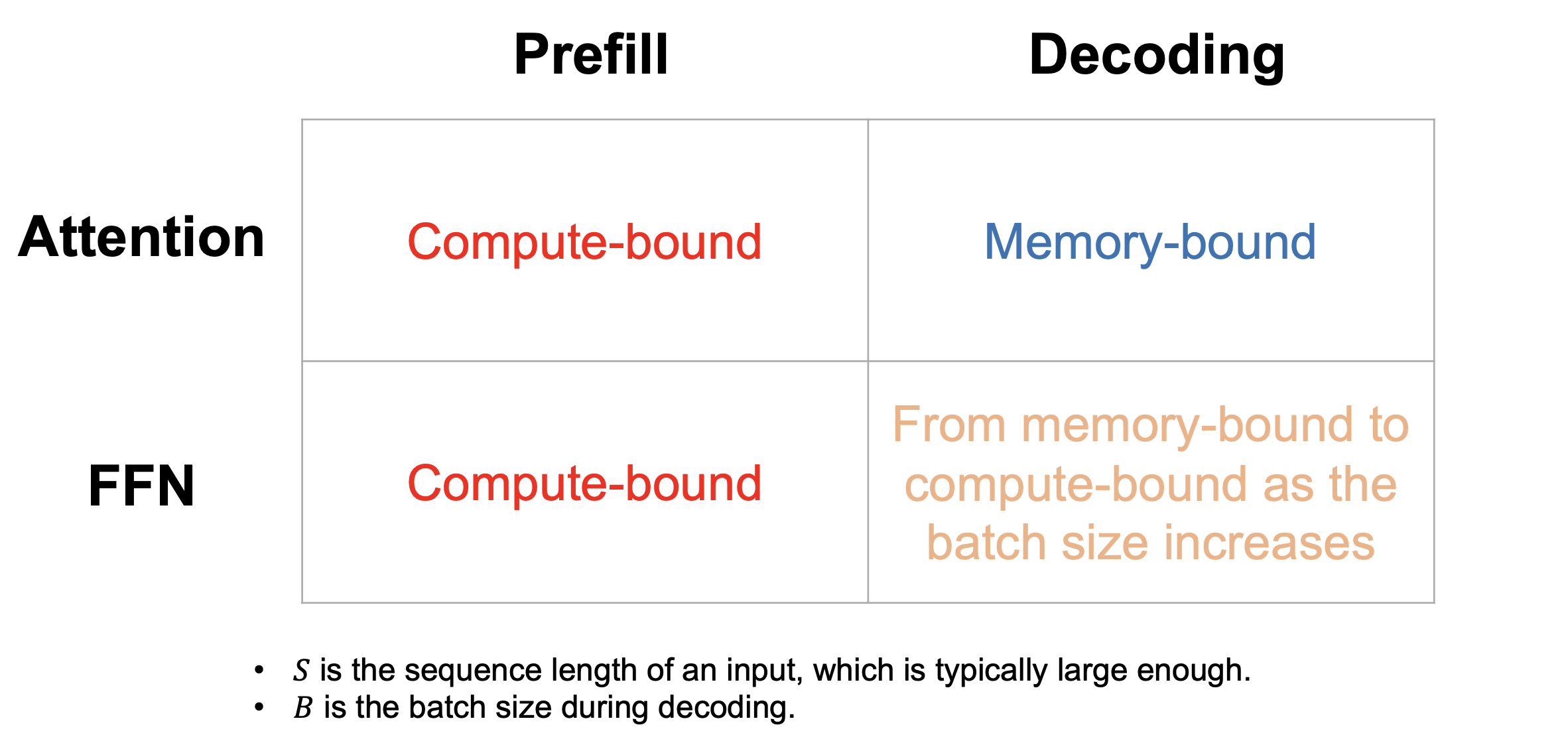
Characteristics of two phases in LLM serving
Disaggregate Attention and FFN
- Independent scaling: Aggregating multiple attention requests can improve the computational efficiency of FFN
- Heterogeneous deployment: Adopt more cost-effective hardware for each module

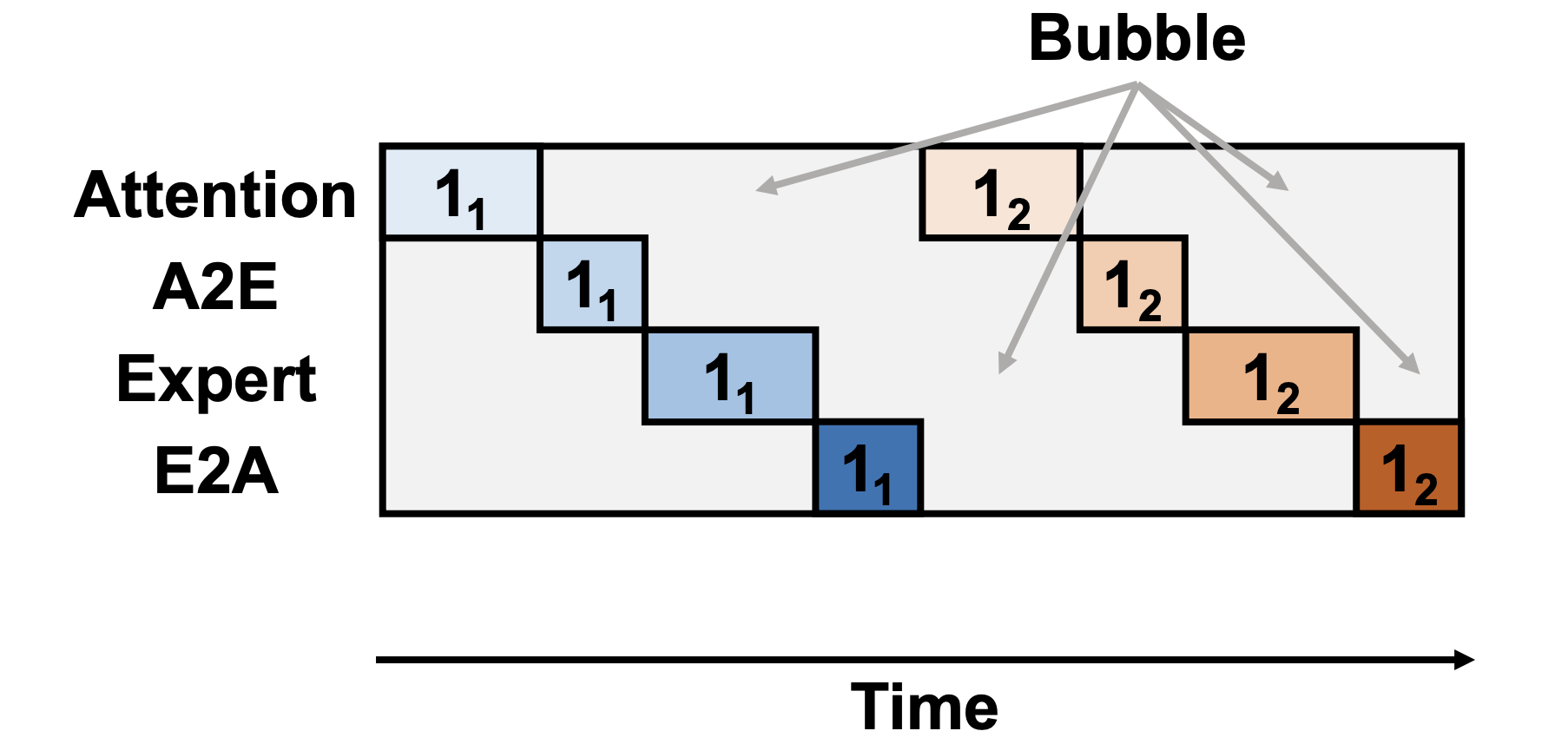
Challenge 1: Idle Resource Due to Dependencies
- Sequential computation of a batch will result in only a portion of the resources being utilized at the same time
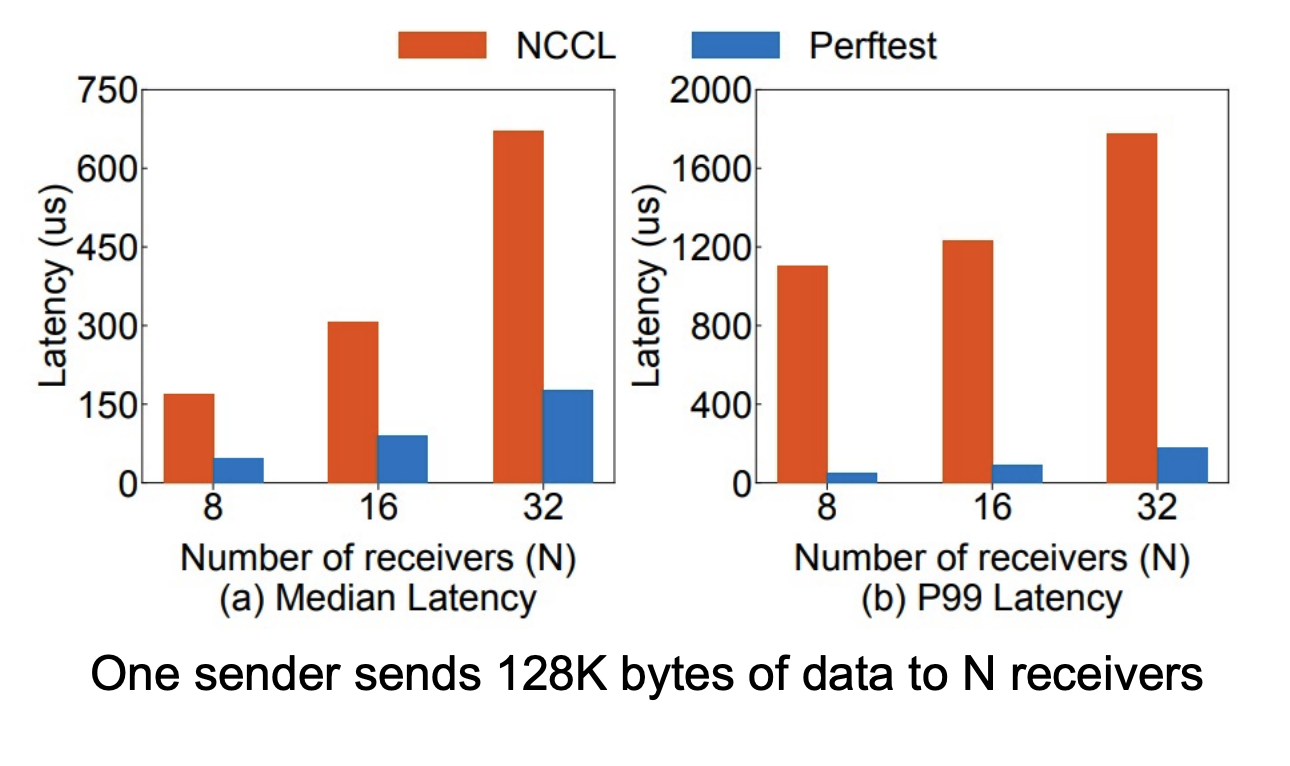
Challenge 2: Requirement of High-Performance M2N Communication
- High overhead in existing libraries and instabilities
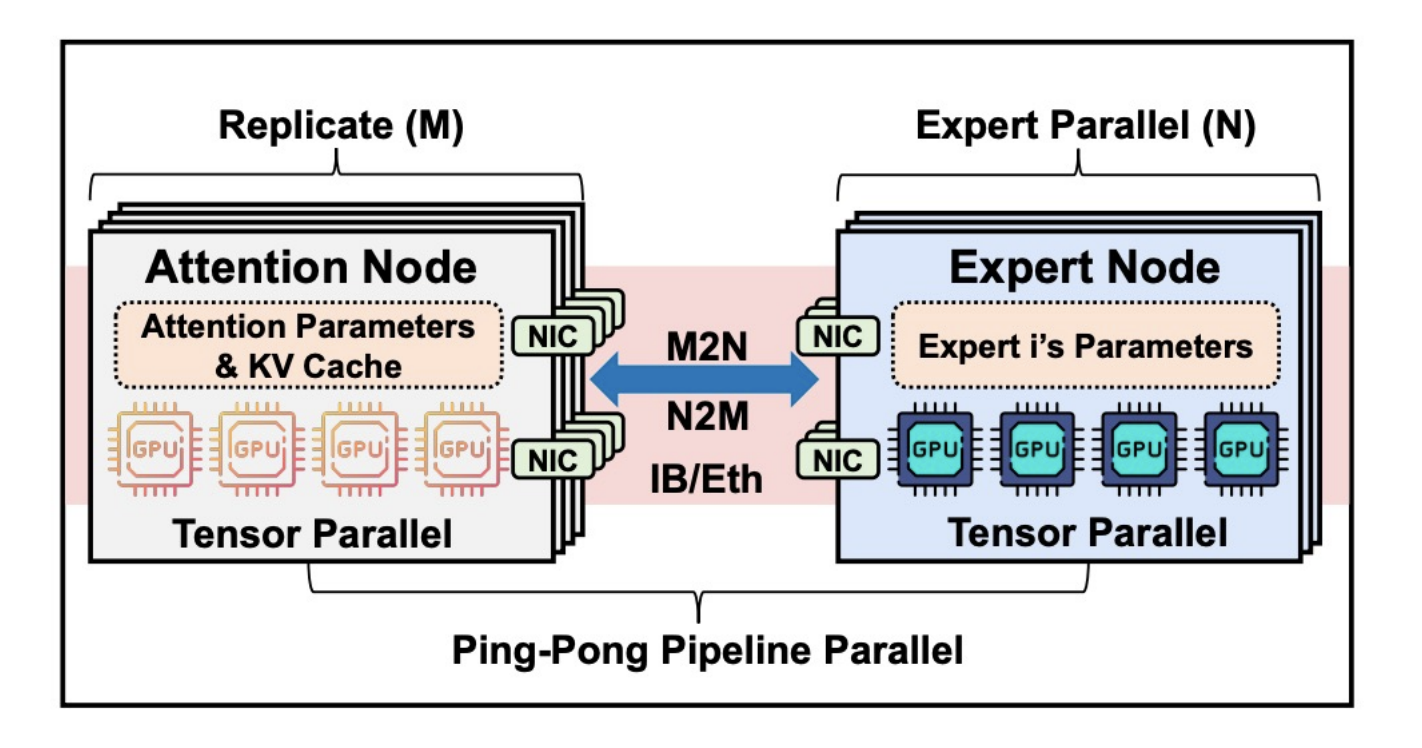
MegaScale-Infer
- Disaggregated expert parallelism
- Ping-pong pipeline parallel
- High-performance M2N communication library