How are LLM interceptions handled now?
- SoTA LLM serving systems tread LLM interceptions as end of requests
- Discard all KV context
- (Re)compute KVs or tokens in context when interception ends
- 37%-40% e2e request latency spend on recomputation
- wastes 40% GPU resources
InferCept
- Pause a request upon intercepting
- Adaptively choose strategies for dealing with KV context
- Efficient implementation of intercept strategies
- Multiple intercepting endpoints supported (tool, other model, human, …)
- 1.6x to 10x improvement over vLLM (SoTA LLM serving system)
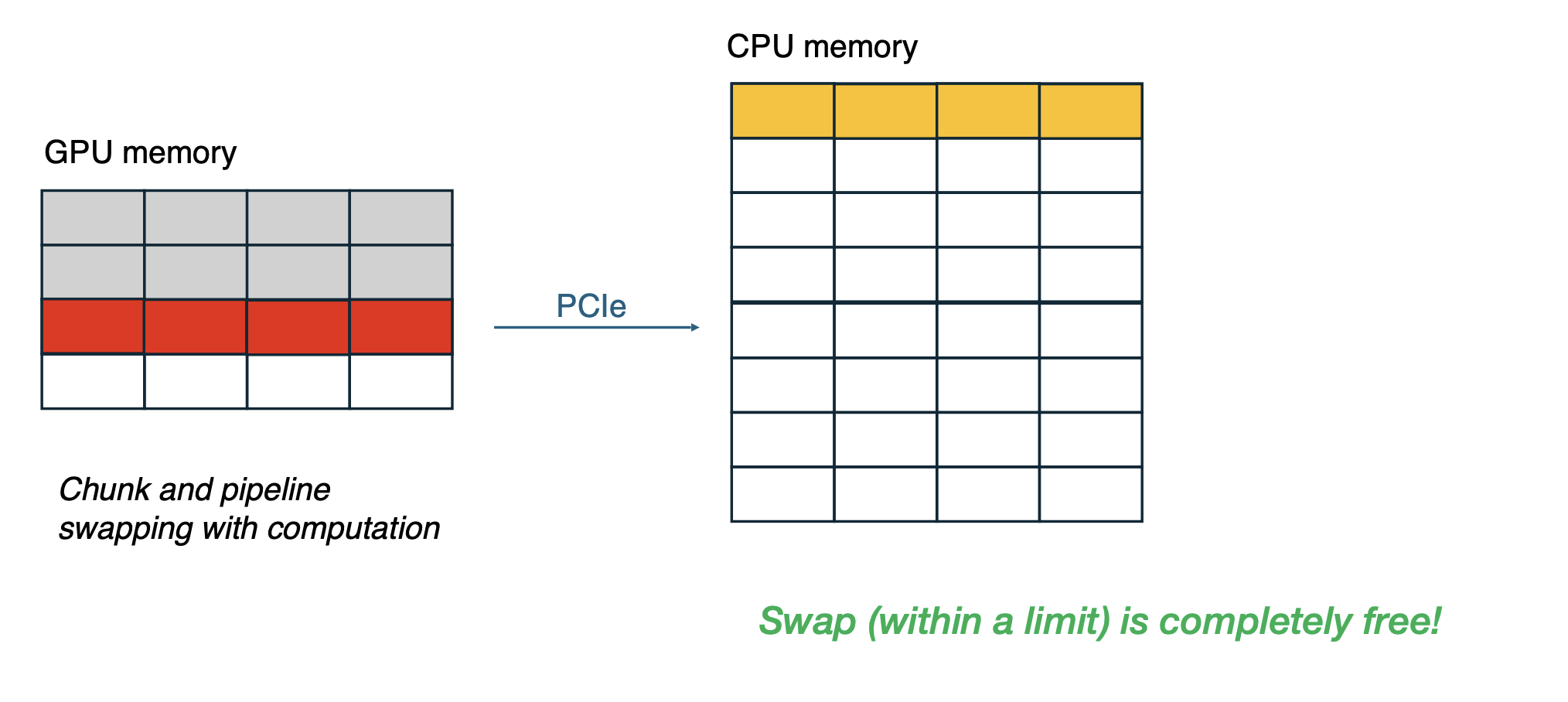
Three Intercepting Strategies - when dealing with KV context
- Discard KV context and recompute upon return
- Preserve KV in GPU memory during interception
- Swap KV to CPU memory during interception
Idea minimizing waste
A unified measurement for all strategies
- Waste = unused GPU memory * time
- Accounting for intercepted request and remaining request
For each intercepted request, choose the minimal-waste strategy
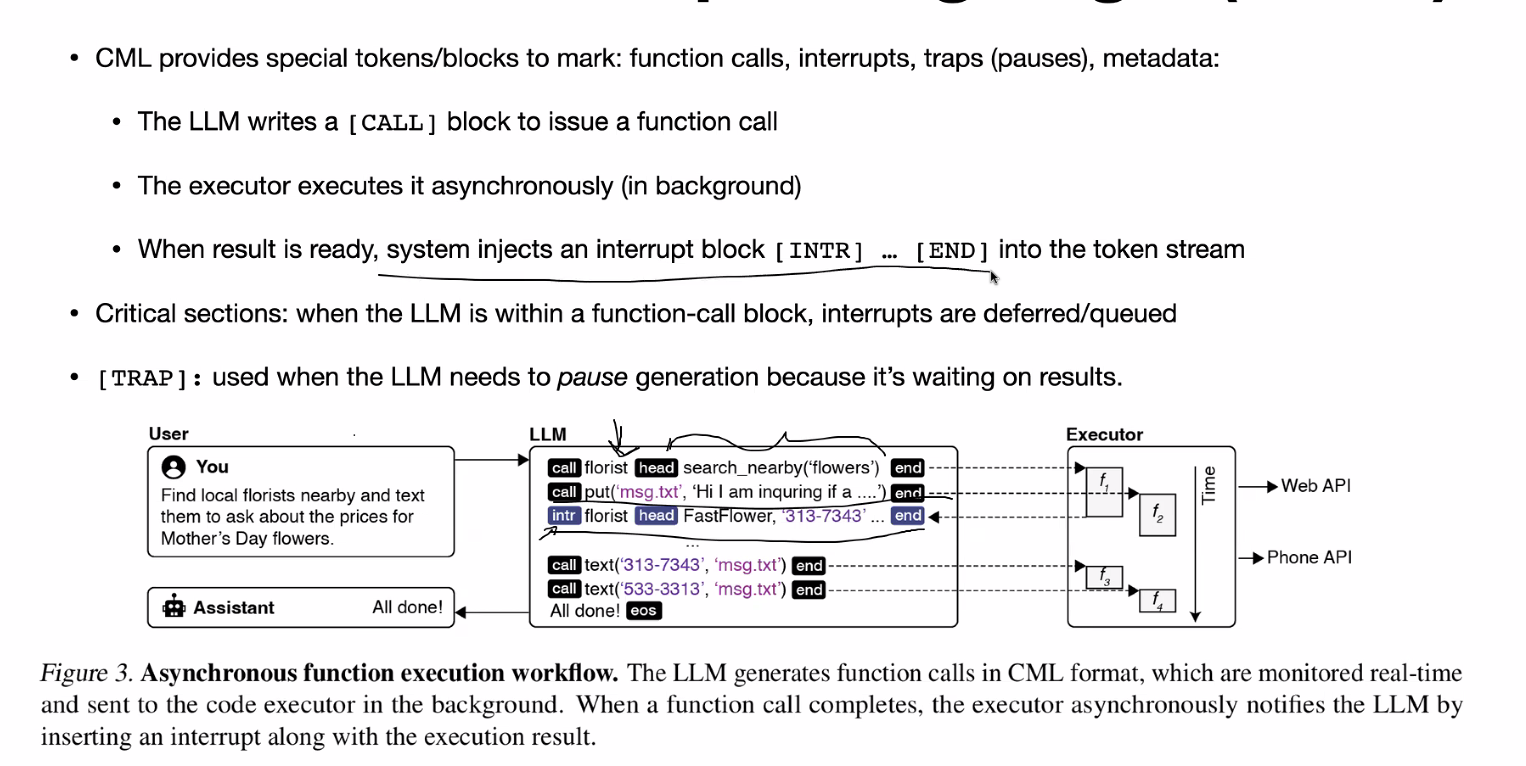
MinWaste Discard: Chunk Recomputation
 Idea: don’t recompute everything at once
Idea: don’t recompute everything at once
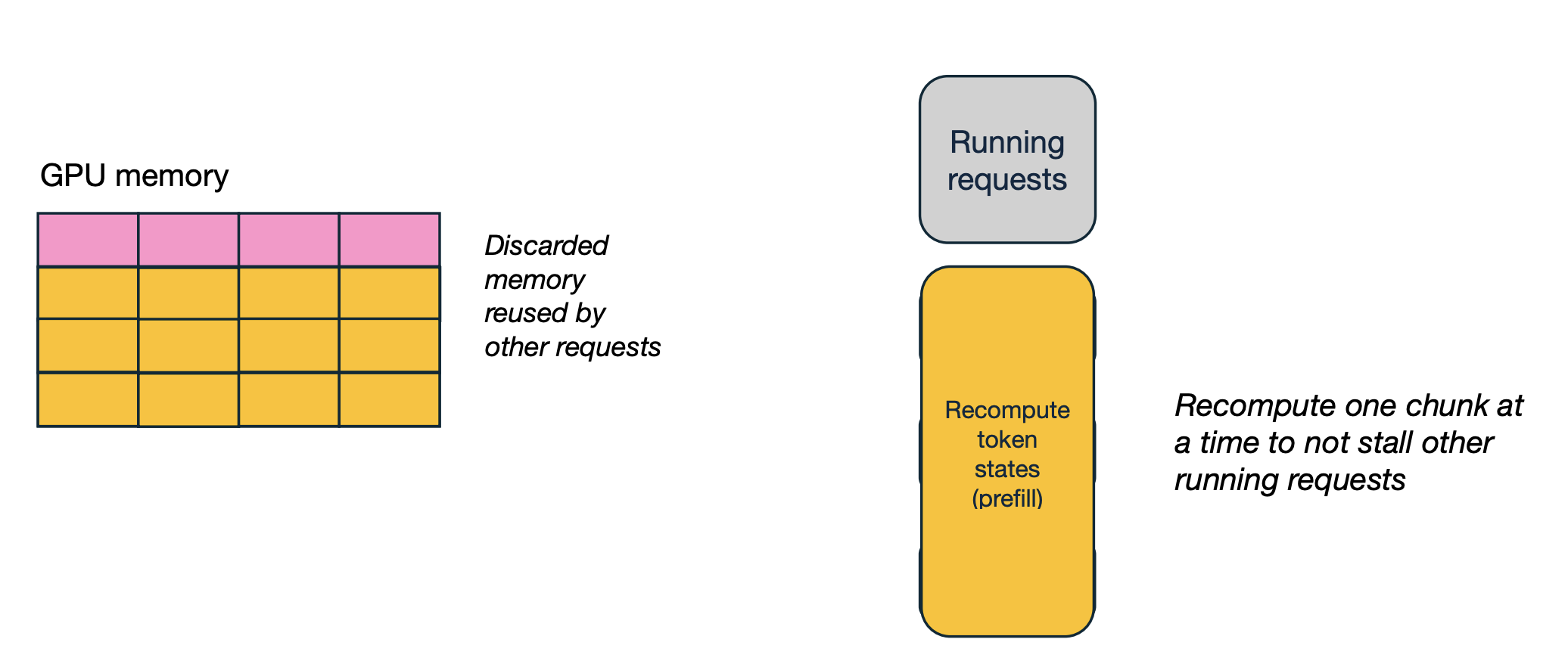
MinWaste Swap: Hide Swap Latency
 Overlap computation with communication, if computation is within the PCIe bandwidth, it’s essentially free (bottleneck is PCIe)
Overlap computation with communication, if computation is within the PCIe bandwidth, it’s essentially free (bottleneck is PCIe)
Efficient Scheduling Across Requests
- Out of all intercepted requests in an iteration
- Utilize the swap budget for otherwise most wasteful requests
- Then, make the decision for remaining requests
- Maintain 3 queues: running, waiting, swapped
- When scheduling, follow FCFS
- Fill GPU saturation point with running + waiting
- Fill swap budget with swap in + swap out
Scheduling Across Requests
Out of all intercepted requests in an iteration
- Use the swap budget for otherwise most wasteful requests
- Choose the smaller waste of preserve and discard for the remaining requests
InferCept Takeaways
- Model calls are increasing accompanied by external tool and data calling
- KVs need to be properly managed when external entities intercept model calls
- Three basic strategies, each with pros and cons
- InferCept: first work to manage model/non-model interactions at the system level
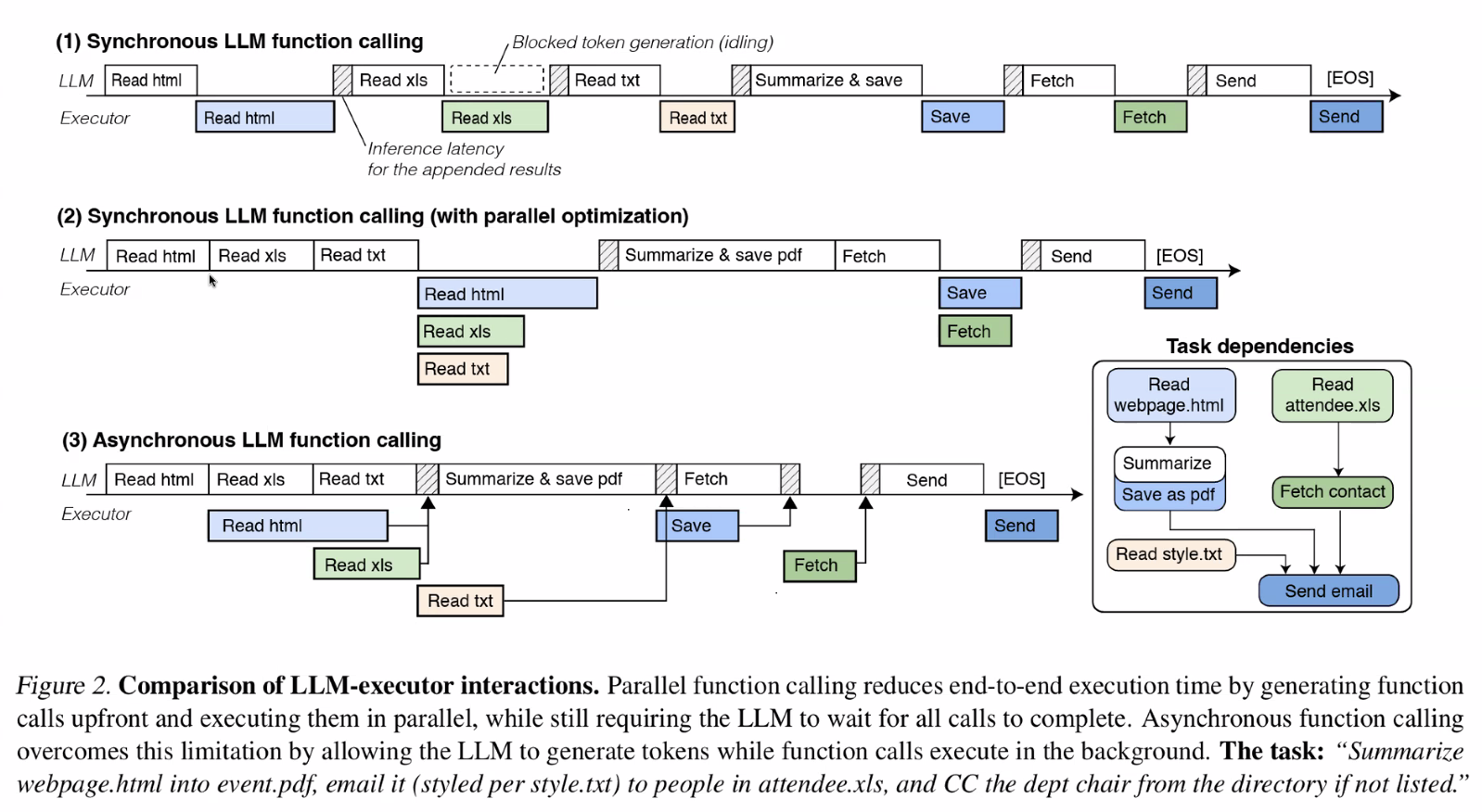
Problem of Synchronous Function Calling in LLM Inference
- Synchronous tool calling: the LLM issues a call → token generation stops → waits for call to return → then resumes
- In efficient in latency (not solved by InferCept) and resource-utilization (partially solved by InferCept)
- Some optimizations: bundle calls and execute in parallel, fuse sequential calls, caching, etc
- But synchronous function calling fundamentally blocks overlap between token generation and function execution
Asynchronous Function Calling in LLM Inference
- LLM continues generating tokens (for independent portions of the tasks) while function calls execute
- AsyncLM: allows the LLM and func-call to operate independently
- Note: Typically not that many independent function calls in single LLM
- more prevalent in agents
- Note: Typically not that many independent function calls in single LLM
- How did find LLM independent tasks
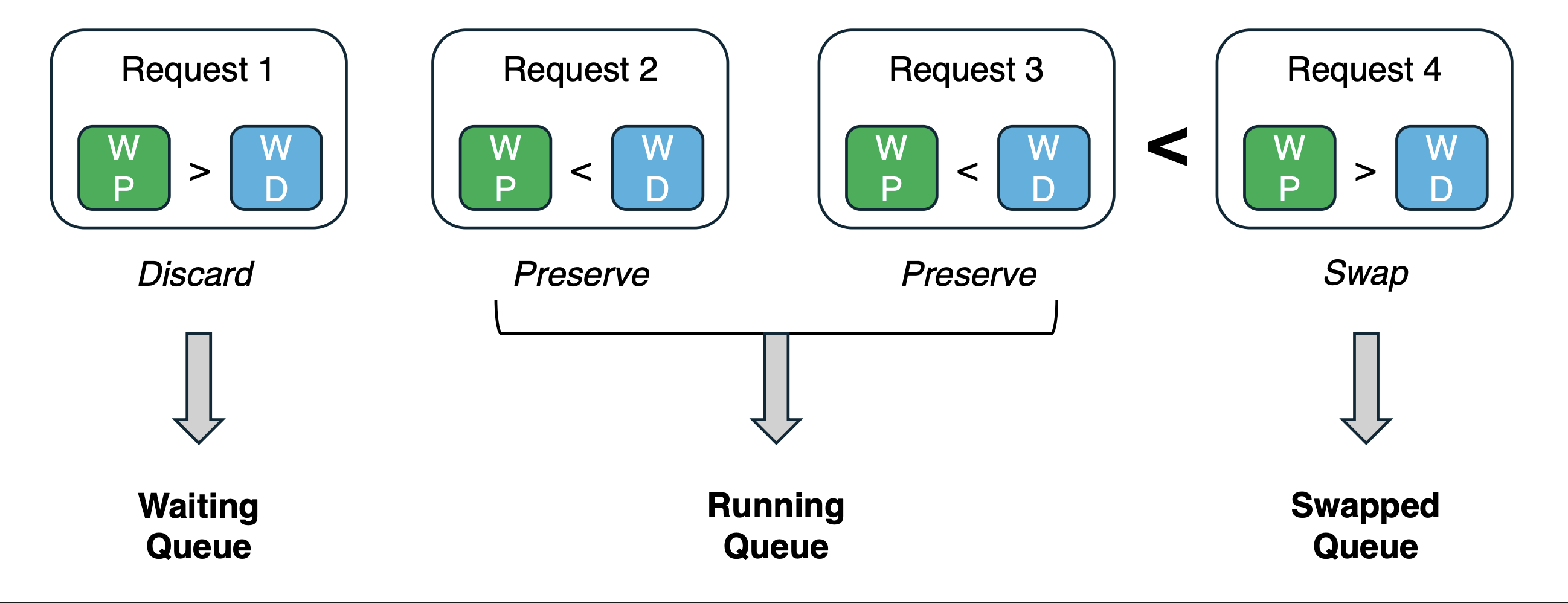
- need to fine tune LLM and use special token [CALL] block to issue a function call
- Context Markup Language (CML)
- Benefits:
- overlapping work
- better resource utilization
- less idle waiting
- automatic parallelism even without explicit dependency graph knowledge
Sync vs Async
Context Markup Language (CML)