Background
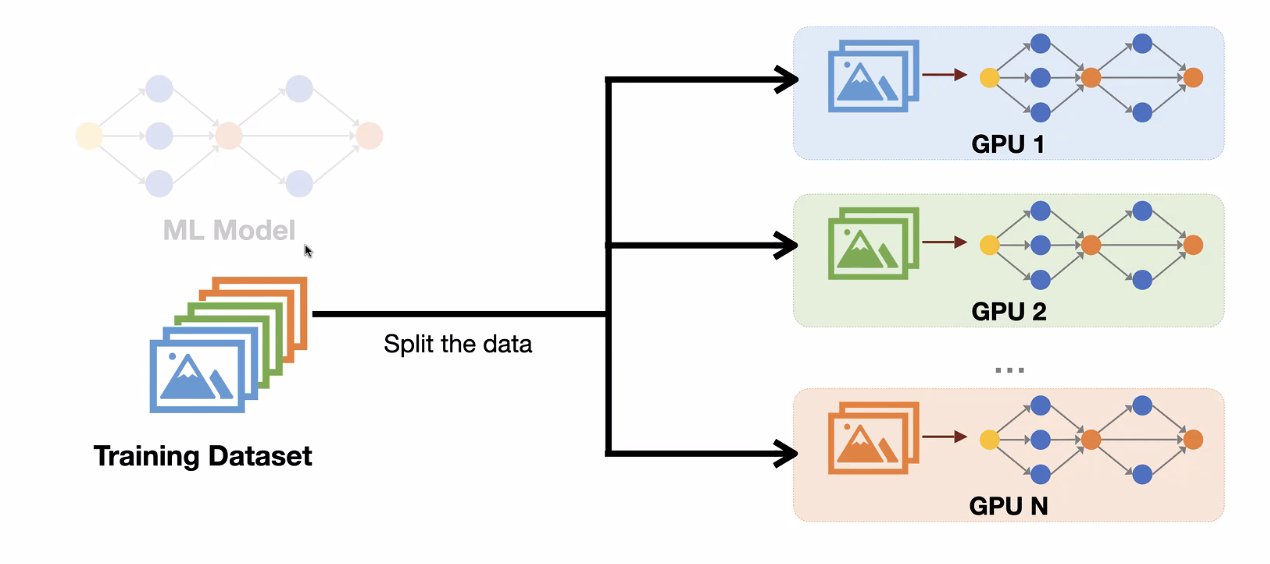
Data Parallelism
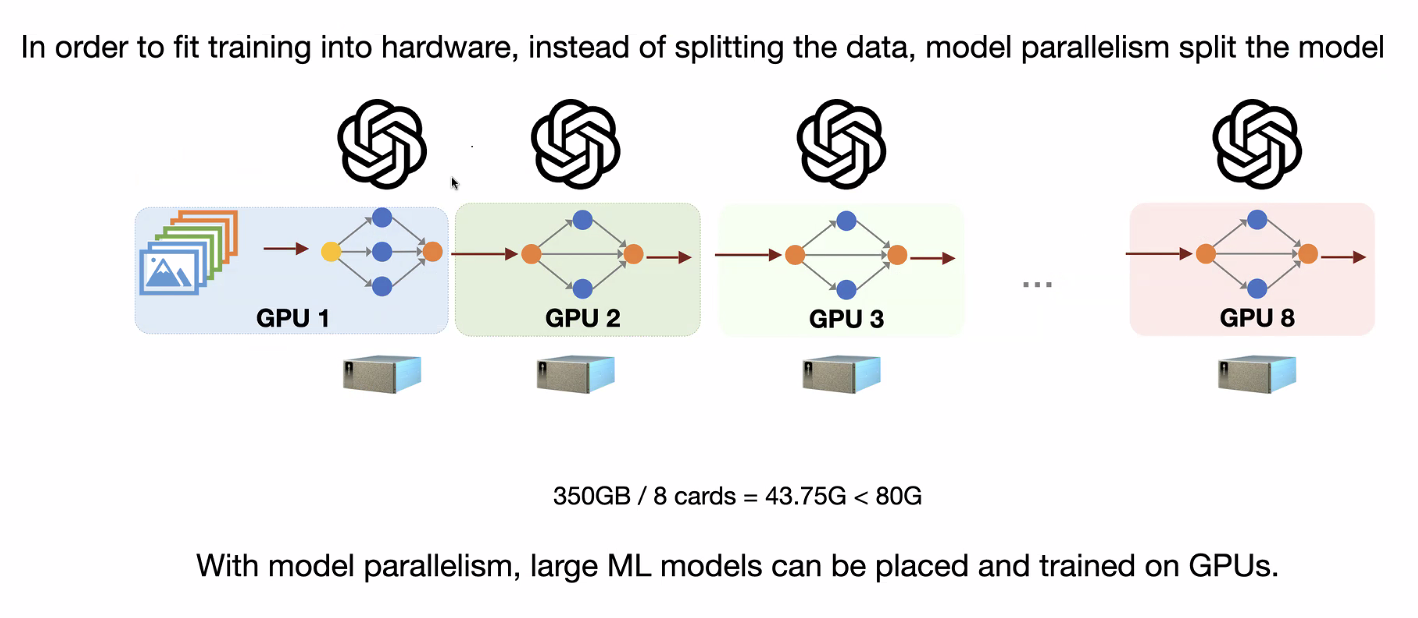
 Model Parallelism
Model Parallelism
How to server long context in a systems sense
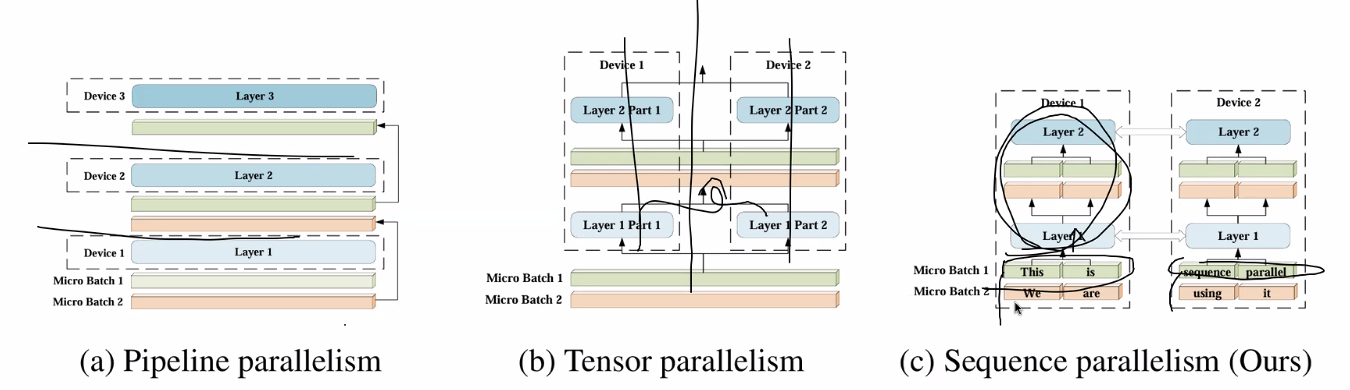 Within a single request parallelizing the context
Within a single request parallelizing the context
Self attention
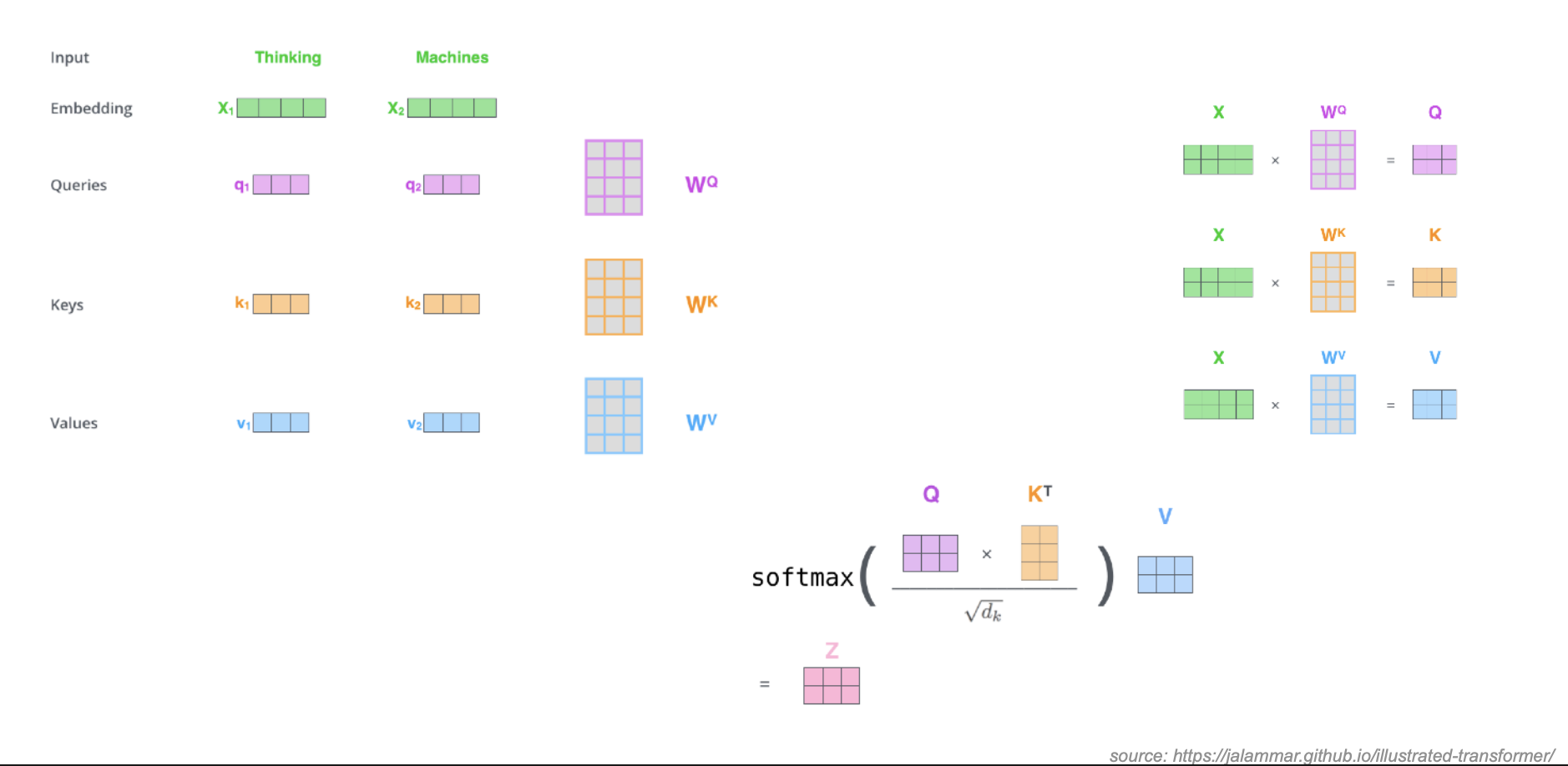
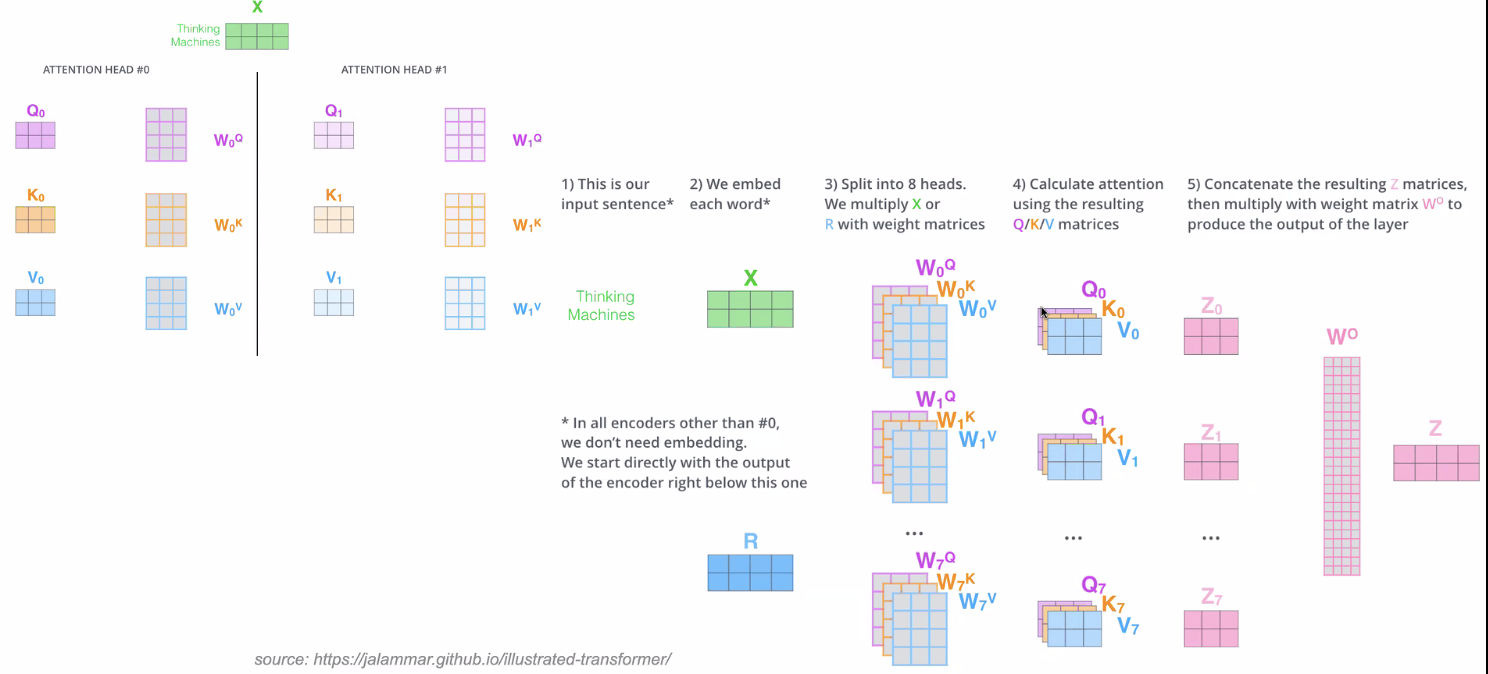
Multi-headed Attention
Data Parallelism
Model Parallelism
Within a single request parallelizing the context