Summary
The paper introduces Mirage Persistent Kernel (MPK), aimed to transform LLM inference into a single megakernel. MPK consists of two key components: the compiler and the runtime. The compiler turns an LLM’s computation graph into an optimized task graph. The runtime executes the task graph with MPK’s event-driven pipeline. MPK event-driven pipeline is structured by partitioning all streaming multiprocessors on the GPU with two roles: worker and schedulers.
Questions
- What’s the pros and cons of megakernel as compared to traditional more fine-grained GPU kernels?
The pros of a megakernel is it takes out the overhead from starting up independent GPU kernels for operations and allows for pipelining of operations because they aren’t isolated by separate kernels. The cons of a megakernel is the support. It doesn’t support modern GPU architecture and it’s not modular. Having separate kernels allows for flexibility to optimize kernels for specific operations, but having a megakernel defeats that flexibility.
- Do you think it’s feasible to build a megakernel that incorporates speculative decoding? How?
I think it is possible to build a megakernel that incorporates speculative decoding. The biggest challenge that I see is in speculative decoding, there is a clear order in the inference process. The draft model predicts. Then the target model validates. In the megakernel, the work is event driven. If it was possible to keep the draft model’s work separate from the target model like another scheduler that handles making sure the draft completes before the target, then it might be possible.
TL;DR
- Developed a compiler that automatically transforms LLM inference into a single megakernel
- a fused GPU kernel that performs all necessary computation and communication in one launch.
- This end-to-end GPU fusion approach reduces LLM inference latency by 1.2-6.7x.
- compiler is easy to use — you can compile your LLM into a high-performance megakernel with just a few dozen lines of Python.
Key Idea
- Traditional LLM systems rely on sequences for GPU kernel launches and external communication calls
- results in underutilized HW
- Introduce compiler that fuses these operations together into a megakernel
Megakernel
Combines all computation and communication, also known as a persistent kernel
- No interruptions Benefits:
- Eliminates kernel launch overhead
- Enables software pipelining across layer
- Overlaps computation and communication
Background
Existing ML frameworks do not natively support e2e megakernel generation. Modern LLM systems are built from a diverse collection of specialized kernel libraries.
The paper looks to see if they could automate the turning the inference pipeline into a single, unified kernel with compilation
- Developed Mirage Persistent Kernel (MPK) - compiler and runtime system that automatically transforms multi-GPU LLM inference into a high performance megakernel.
Mirage Persistent Kernel (MPK)
The Compiler
terms:
- computation graph - computation performed by LLM where each node corresponds to a compute op or collective communication primitive
- kernel-per-operator execution model - traditional systmes where each operator is executed via a dedicated GPU kernel
MPK introduces a compiler that automatically transforms the LLM’s computation graph into a fine-grained task graph. This task graph explicitly captures dependencies at the sub-kernel level, enabling more aggressive pipelining across layers
Graph labels:
- task - unit of computation/communication
- event - synchronization point between tasks
- each tasks has an outgoing edge to a triggering event
- each tasks also has an incoming edge from a dependent event
Task graph is used to pipeline work
The Runtime
Executes the task graph entirely within a single GPU megakernel. MPK statically partitions all streaming multiprocessors (SMs) on a GPU into two roles: workers and schedulers. The number of worker and scheduler SMs is fixed at kernel launch time and matches the total number of physical SMs, avoiding any dynamic context switching overhead.
Workers Each worker operates on a SM and maintains a dedicated task queue. It follows a simple but efficient execution loop:
- Fetch the next task from its queue
- Execute the task
- Notify the triggering event upon task completion
- Repeat
Schedulers Scheduling decisions are handled by MPK’s distributed schedulers, each of which runs on a single warp (execution unit on a NVIDIA GPU) It continously:
- dequeues activated events whose dependencies are satisfied
- launches the set of tasks that depend on the activated set
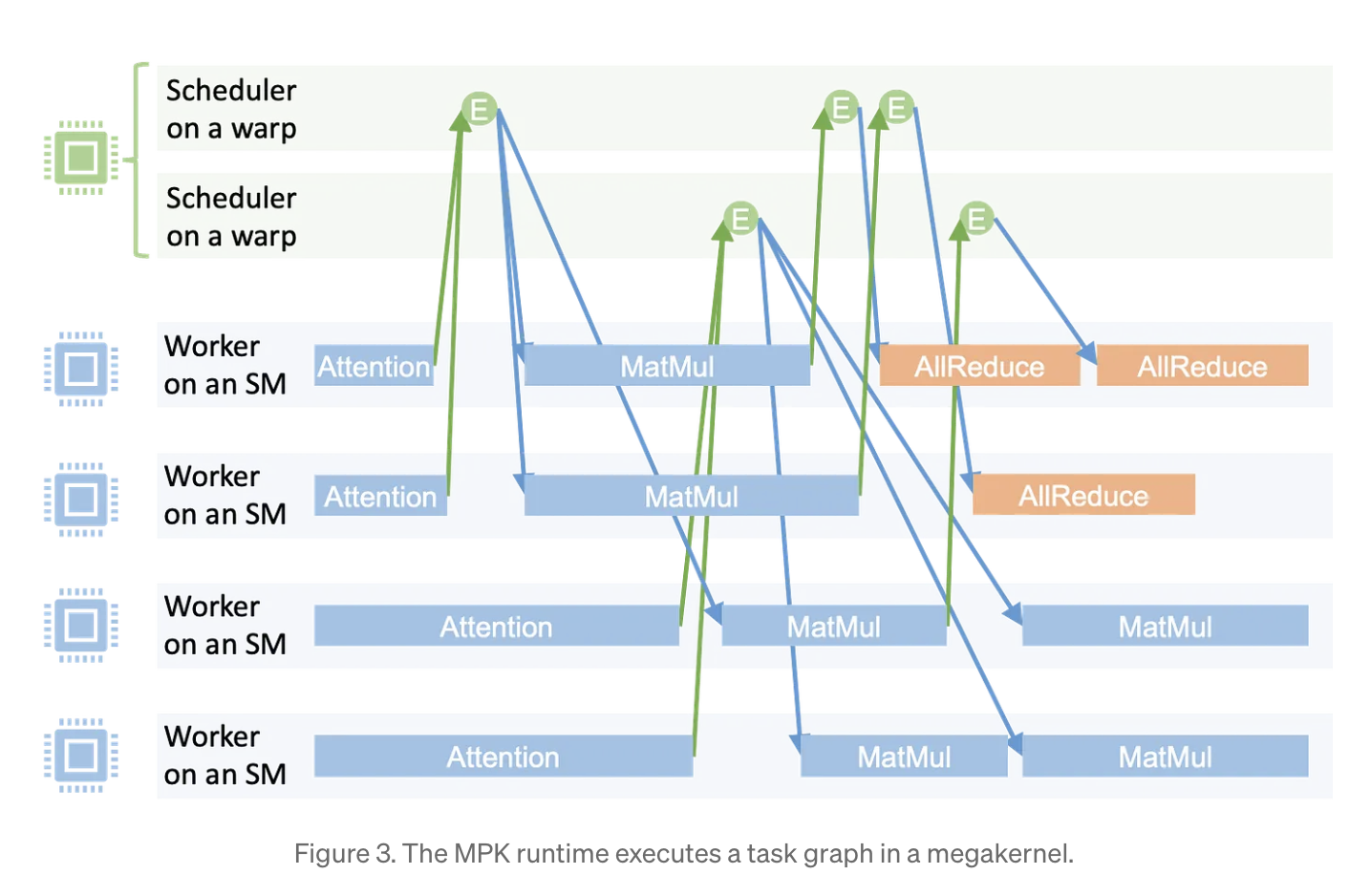
Event-Driven Execution Allows for fine-grained software pipelining and overlap between computation and communication