Traditional RNN, Attention optimizes model performance by only going through needed decode stages rather than all (reduces path length)
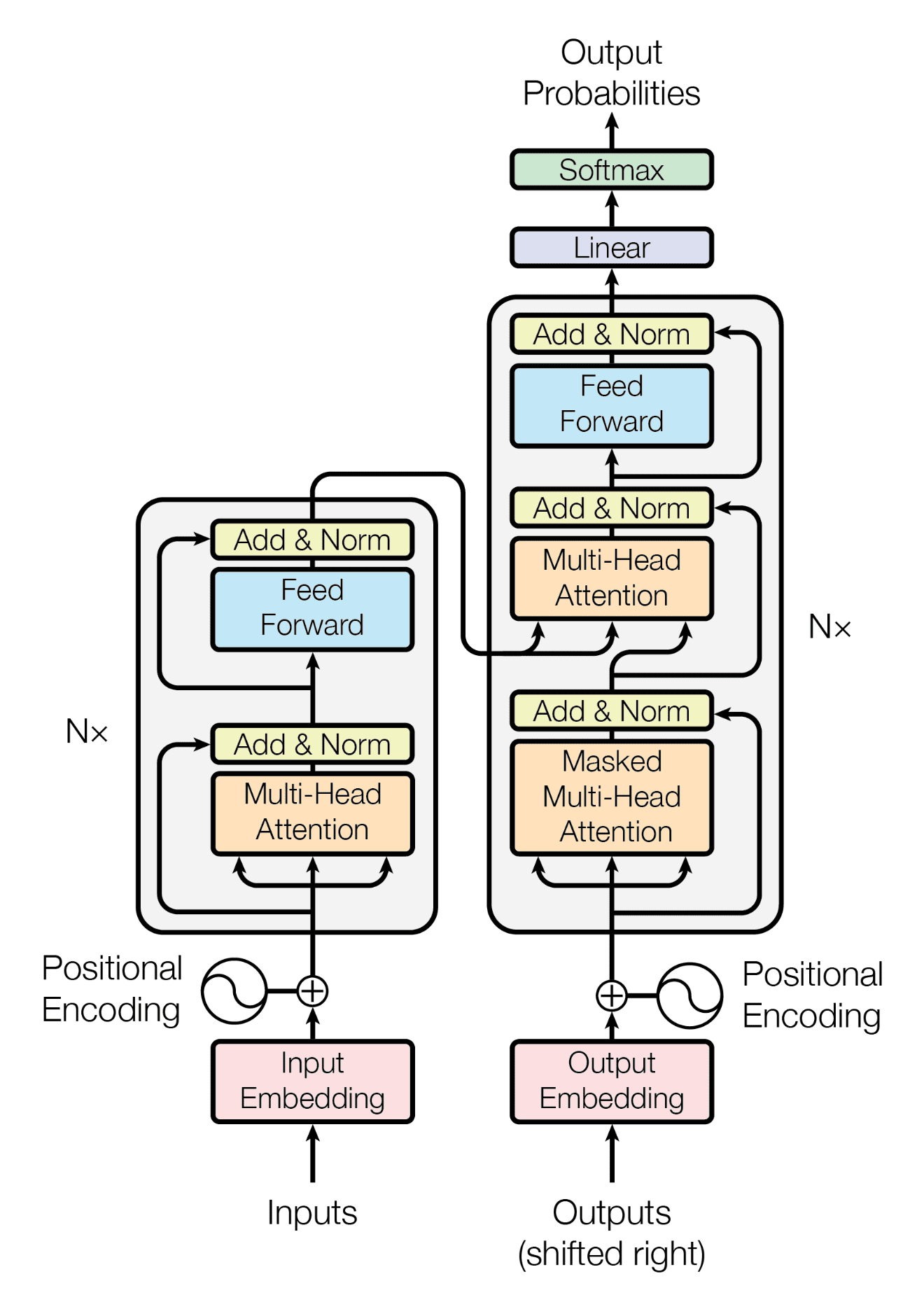
 Transformer Architecture
Transformer Architecture
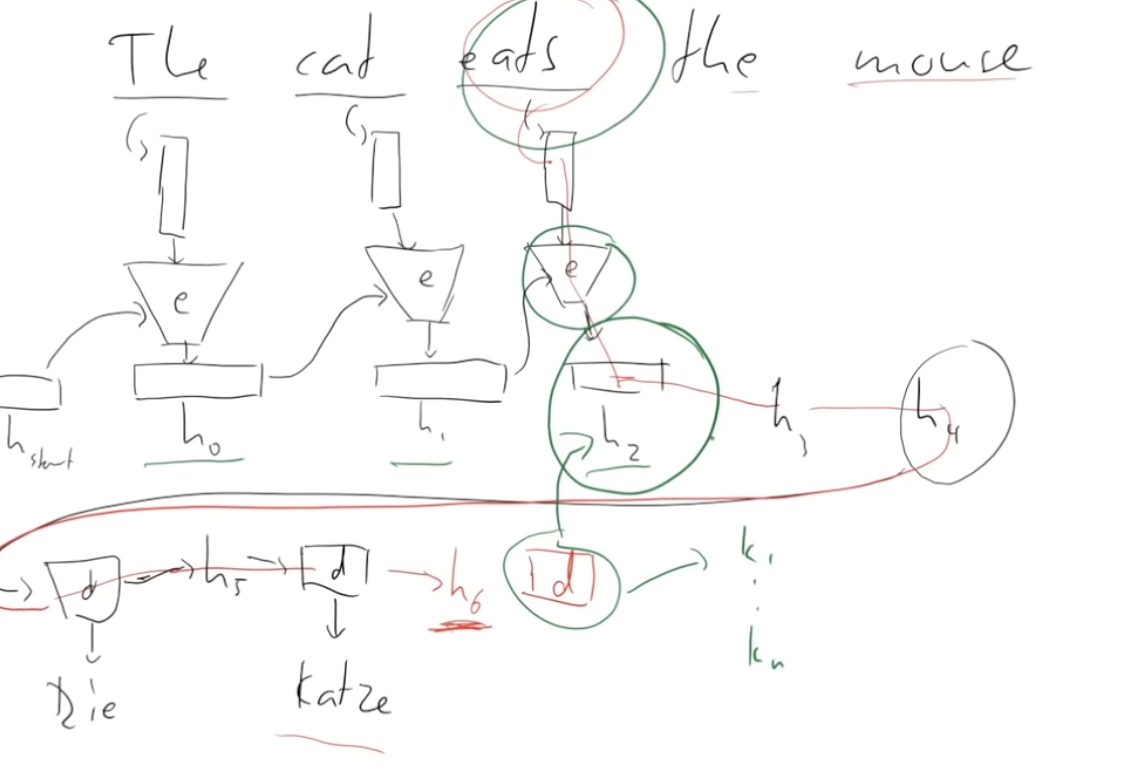
 Feed entire sentence and target output to input and output respectively to get probability of output. Back propagation only on one step (one word) rather than whole sentence
Feed entire sentence and target output to input and output respectively to get probability of output. Back propagation only on one step (one word) rather than whole sentence
- Positional encoding: position of words
- Attention: choose which words to look at the most to feed over to output