Source: https://pdos.csail.mit.edu/6.824/papers/vm-ft.pdf
Abstract
- Production grade system for providing fault-tolerant virtual machines
- Done by replicating the execution of a primary virtual machine (VM) via a backup virtual machine on another server
Background
Approaches to fault-tolerant servers
- Primary/backup, where backup server is always available to take over when primary server fails
- Backup server state must be kept nearly identical to primary server at all times
- Two ways of replicating state:
- copy changes over (heavy bandwidth)
- State machine, ensure requests are received in same order (less bandwidth) VMs running on top of a hypervisor is a natural platform for implementing fault-tolerance using the state machine approach. A VM can be defined as a “well-defined” state machine whose operations are being virtualized. This creates a layer to control ordering of requests.
- Two ways of replicating state:
- Backup server state must be kept nearly identical to primary server at all times
FT Design
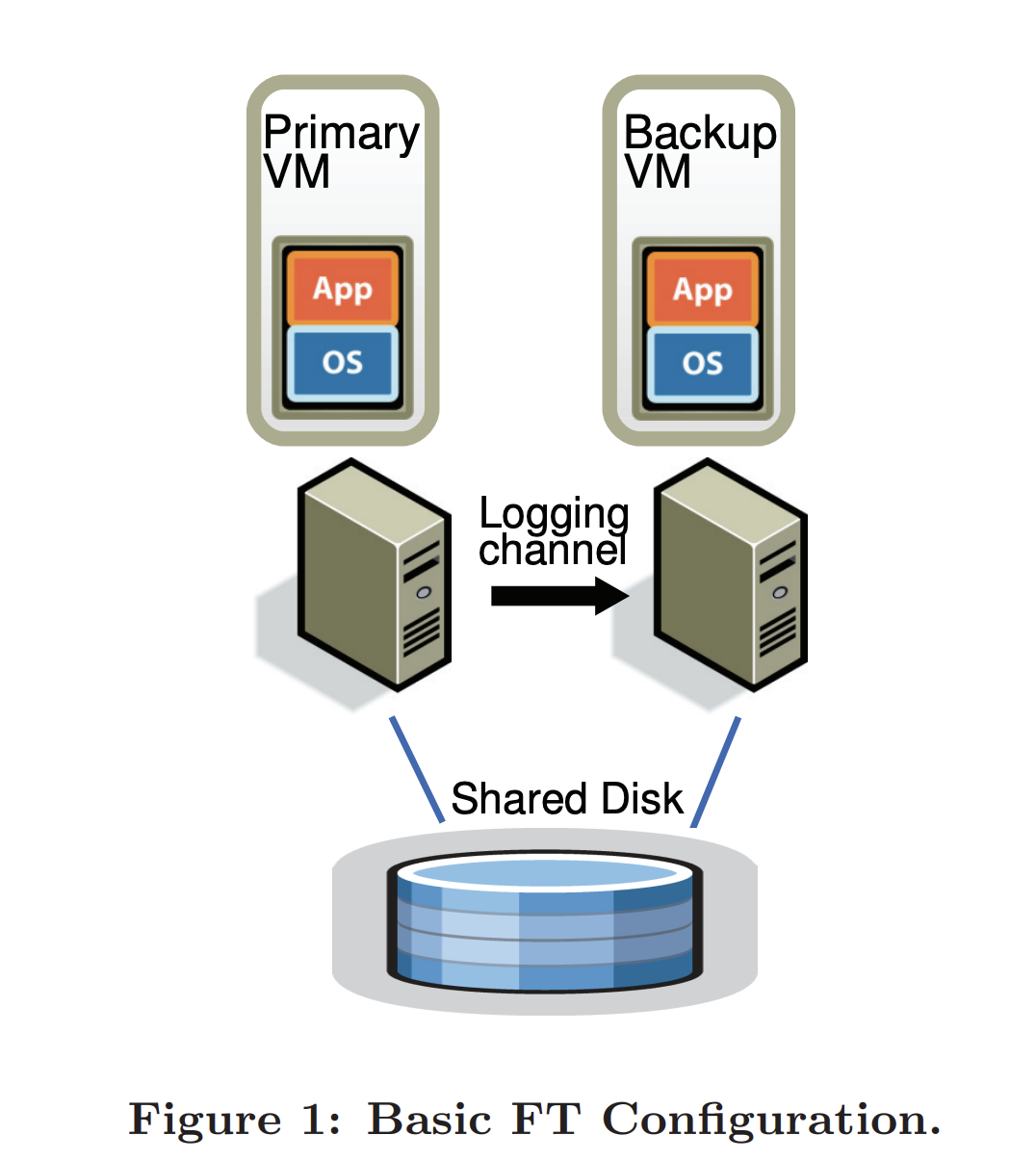
- For a given VM (primary VM), a backup VM is ran on another server
- The servers are kept in sync through a logging channel
- The backup executes identically tot he primary VM with a small time lag.
- The two VMs are in virtual lockstep
Handling Failure
- The system uses a combination of heartbeating between the relevant servers and monitoring of the traffic on the logging channel.
- To ensure only one of the primary or backup VM takes over execution, HOW???
Deterministic Replay Implementation
Big Idea: if two deterministic state machines are started in the same initial state and provided the exact same inputs in the same order, then they will go through the same sequences of states and produce the same outputs.
Thus tracking every event (even some non-deterministic events) is required because it can affect the VM’s state. Need to find a way to:
- Correctly capture all input and determinism to ensure deterministic execution of a backup virtual machine
- Correctly applying the inputs and non-determinism to backup machine
- Do it in a way to mitigate degradation of performance
VMware deterministic replay records the inputs of a VM and all possible non-determinism associated with the VM execution in a stream of log entries written to a log file. The VM execution may be replayed later by reading the log entries from the file.
Interesting fact: the authors didn’t have to batch the events by epoch, their delivery system was efficient enough without batching.
Fault Tolerance Protocol
Deterministic replay is used to produce the log entries. Log entries is send to backup VM through logging channel. Backup VM replays the entries in real time and executes identically to the primary VM.
The authors propose a fundamental requirement:
Output Requirement: if the backup VM ever takes over after a failure of the primary, the backup VM will continue executing in a way that is entirely consistent with all outputs that the primary VM has sent to the external world.
Hence, if a failover occurs, as long as the back VM satisfies the Output Requirement, clients will notice no interruption or inconsistency in their service
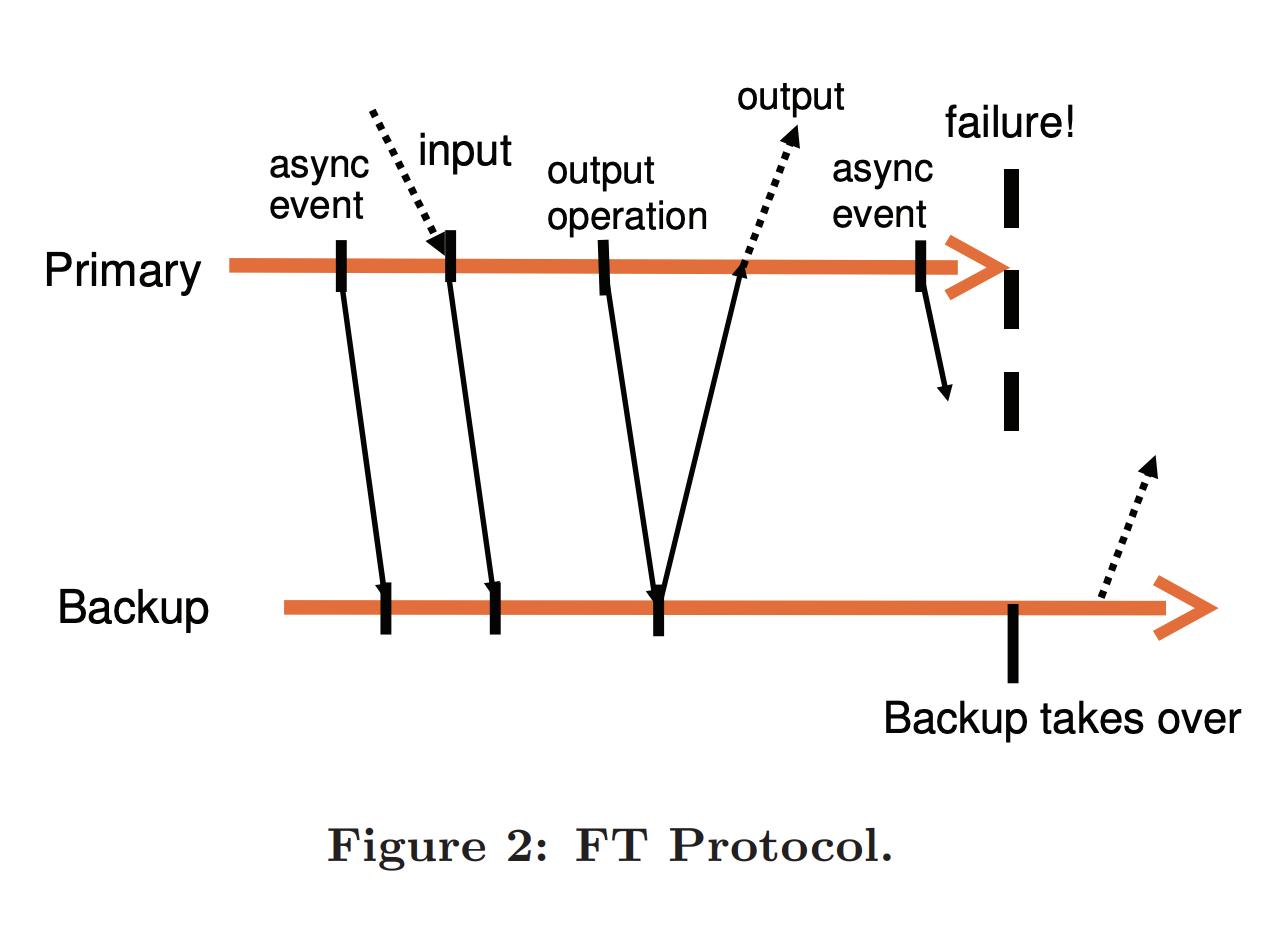
The backup VM must keep replaying right up to the point of the last output operation. The backup VM can’t switch to primary before this output operation because some other non-deterministic events might be delivered that affects the output. To assure that the Output Requirement is enforced:
Output Rule: The primary VM may not send an output to the external world, until the backup VM has received and acknowledged the log entry associated with the operation producing the output.
Think about it like writing back to durable memory in OS terms in the sense that if it’s not written back, the information is lost and may not be exactly the same on restart.
Detecting and Responding to Failure
If backup VM fails, the primary VM will go live and leave recording mode (sending entries through logging channel) and execute normally
If the primary VM fails, the backup VM will go live and continue replaying its execution from the log entries until it has consumed the last log entry. Then backup VM will stop replaying and start executing normally.
Split-Brain Problem
Split-brain problem - failure detection could be falsely triggered due to network connectivity loss where servers are still functioning, but servers are blind to each other, assuming failure.
This leads to the potential issue of VMs going live when they’re not supposed to. Hence, the need to ensure only one of the primary or backup VM goes live when a failure is detected.
The solution is to use shared storage between the VMs and execute an atomic test-and-set operation on shared storage.
- If operation succeeds VM goes live.
- If operation fails VM halts itself.
- If VM can’t access shared storage, wait until it can. Useful work can’t be done without the shared storage anyways.
Practical Implementation of Fault-Tolerance
Starting and Restarting FT VMs
Features:
- Clone and migrate VMs
- Flexibility to run on any server on cluster
- Clustering service determines best server to run backup VM
Managing the Logging Channel
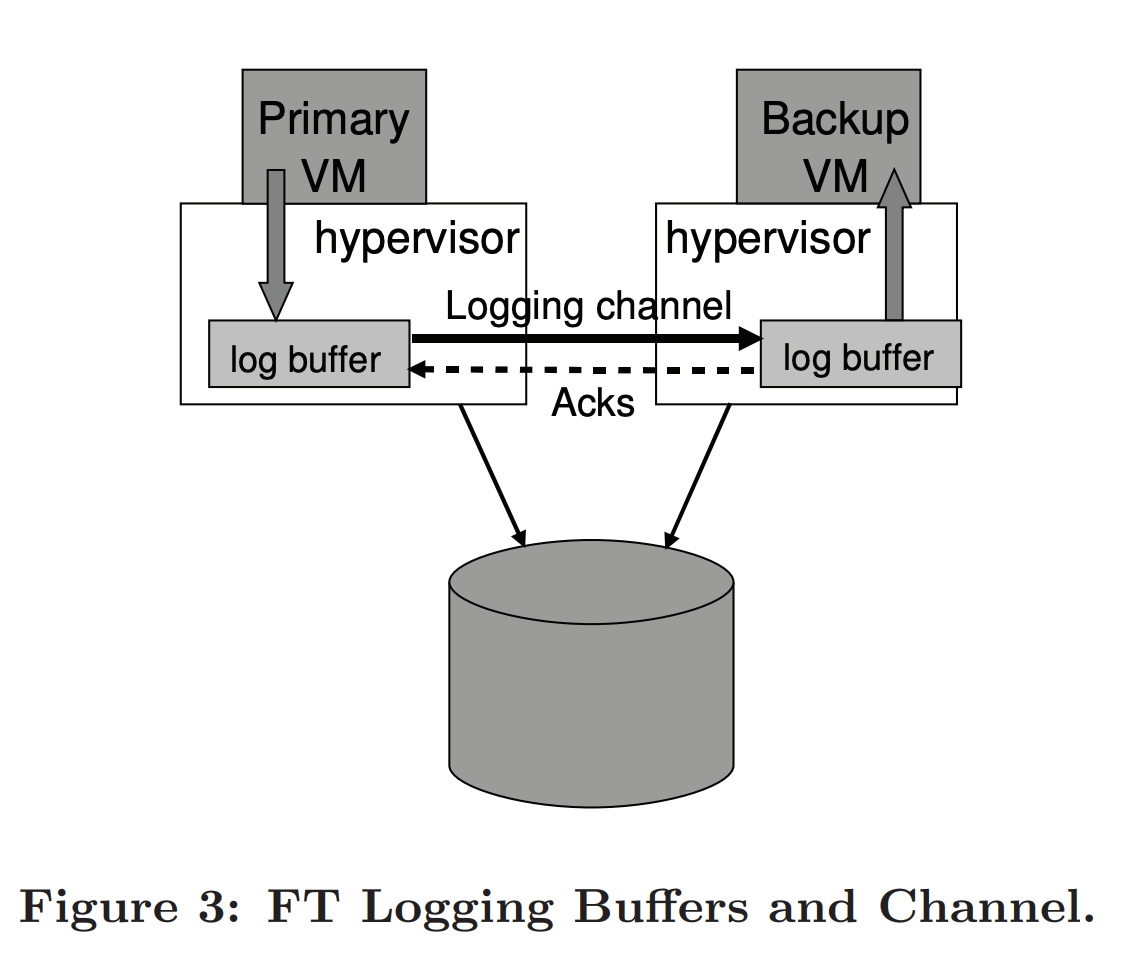 Backup sends acks to primary as confirmations to continue. Paper confirms additional implementation details and correctness of their approach.
Backup sends acks to primary as confirmations to continue. Paper confirms additional implementation details and correctness of their approach.
Implementation Issues for Disk IOs
- Disk operations are non-blocking, can execute in parallel, simultaneous disk operations that access the same disk location can lead to non-determinism
- Also implementation of disk IO uses DMA (direct memory access), same memory access can lead to non-determinism
- Disk operation can also race with memory access by an application in a VM, due to DMA
One solution is adding temporary page protections on pages that are targets of disk operations. Issue is that it’s too expensive to change MMU (memory management unit) protections on pages.
Their solution is bounce buffers.
Bounce buffers is a temporary buffer that has the same size of memory being accessed by a disk operation.
- A disk read operation is modified to read the specified data to bounce buffer, and the data is copied to the guest memory only as the I/O completion is delivered.
- A disk write is modified to write data from the bounce buffer Used to make sure guest VM visible changes are seen at I/O completion time. So the primary and backup can replay the same events the same way without divergence.
- When primary VM fails, the state of disk IOs issued by the primary is unknown.
- To assure the IOs are completed, backup will reissue the pending IOs during the go-live process of the backup.
Implementation Issues for Network IO
Async operations for performance but adds non-determinism. Some operations in Network IO had to be disabled:
- Eliminated network async updates for deterministic events
- To improve performance:
- Batch work to reduce traps and interrupts on transmit and receive.
- Delay in ACKs reduced by making sending and receiving done without any thread context switch. Use a “deferred-execution context”, hypervisor TCP stack has a set function that handles the packet rather than waking up a normal thread.