Changes to Schema or Data Formats
In a large application, code changes often cannot happen instantaneously.
- In server-side applications:
- Rolling upgrade (staged rollout) or deploying the new version to a few nodes at a time, checking for issues, and eventually to all nodes
- This lowers downtime and more frequent releases
- Rolling upgrade (staged rollout) or deploying the new version to a few nodes at a time, checking for issues, and eventually to all nodes
- In client-side applications:
- Need to wait for user to update…
In an instance of time, old and new versions of code can coexist in the system. To order for the system to run smoothly, we need to maintain compatibility for both new and old.
- Backward compatibility - newer code can read data that was written by older code.
- Forward compatibility - older code can read data that was written by newer code
Formats for Encoding Data
Data are usually represented in two different ways:
- In memory, data is kept as objects, structs, lists, arrays, hash tables, trees, etc.
- Over the network, encoded as a self-contained sequence of bytes: JSON or Protobuf
Translation between the two representation is called encoding / serialization / marshaling and decoding / deserialization / marshaling
Language-Specific Formats
Many programming languages come with built-in support for encoding in-memory objects into byte sequences.
- Eg.
pickelfor python
Issues:
- Encoding is not generalized between languages
- Restoring data in the same object types, decoding process needs to be able to instantiate arbitrary classes which is a security vulnerability from malicious injections.
- Versioning data is often not supported, forward and backward compatibility issues
- Efficiency is also an afterthought
Typically bad idea to use your langauge’s built-in encoding for anything other than very transient purposes.
JSON, XML, and Binary Variants
Language-independent formats: JSON, XML, CSV and Binary Textual formats: JSON, XML, and CSV
Issues of JSON, XML, and CSV besides syntax:
- ambiguity in encoding numbers
- In XML and CSV can’t distinguish between a number and a string that consist of digits
- Large numbers may not be represented correctly due to floating-point limits
- JSON and XML has good support for Unicode char strings, but not binary strings
- A workaround is encoding the binary data as text with Base64, but is somewhat hacky and increases the data size by 33%
Biggest issue is getting different organizations to agree on anything lol.
Binary Encoding
For more compact and performance cases.
There are binary formats for JSON: MessagePack, BSON, BJSON, UBJSON, BISON, and Smile.
MessagePack
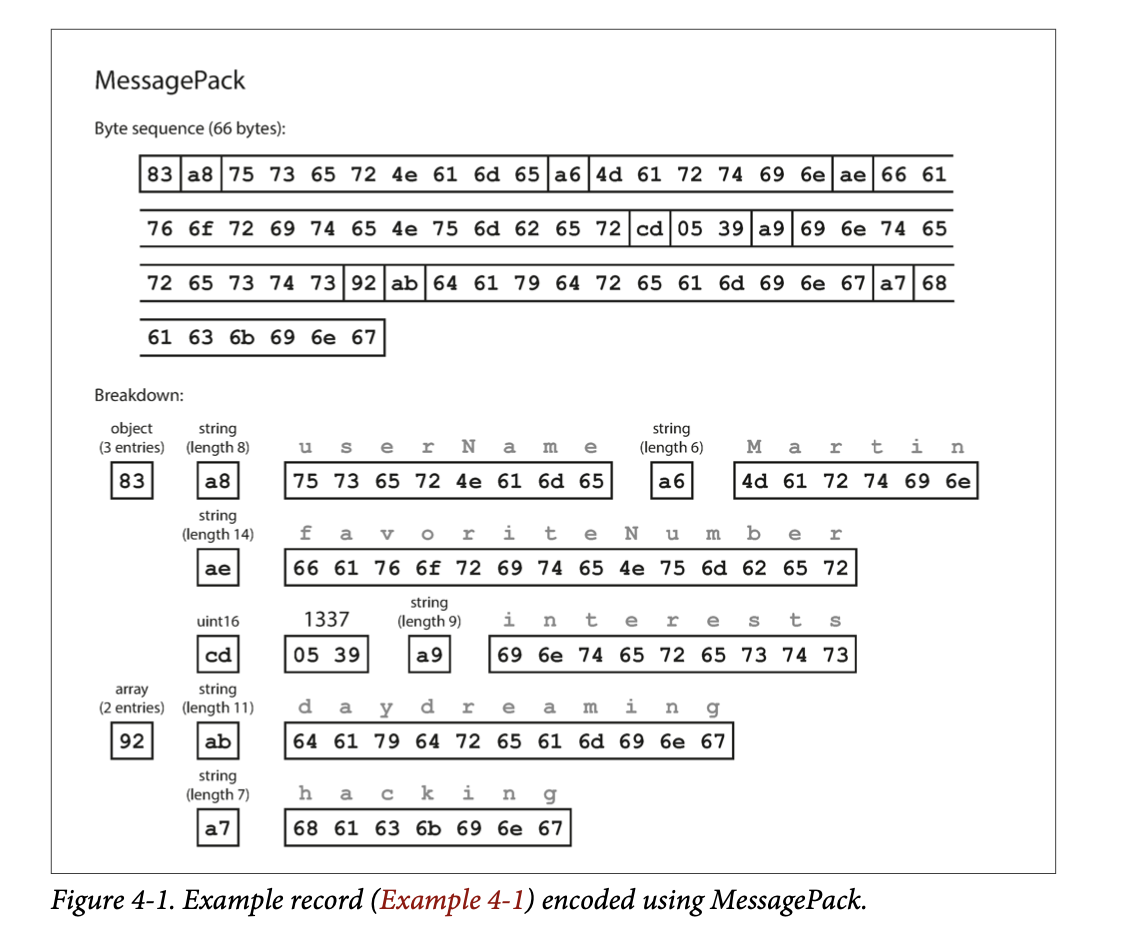
Thrift and Protocol Buffers
Apache Thrift and Protocol Buffers (protobuf) are binary encoding libraries that generalizes encoding based on a user specified schema.
- Both Thrift and Protobuf has a code gen tool that takes a schema definition and produces code that implement the schema in various programming languages.
Thrift
Thrift has two binary encoding formats, BinaryProtocol and CompactProtocol
BinaryProtocol:
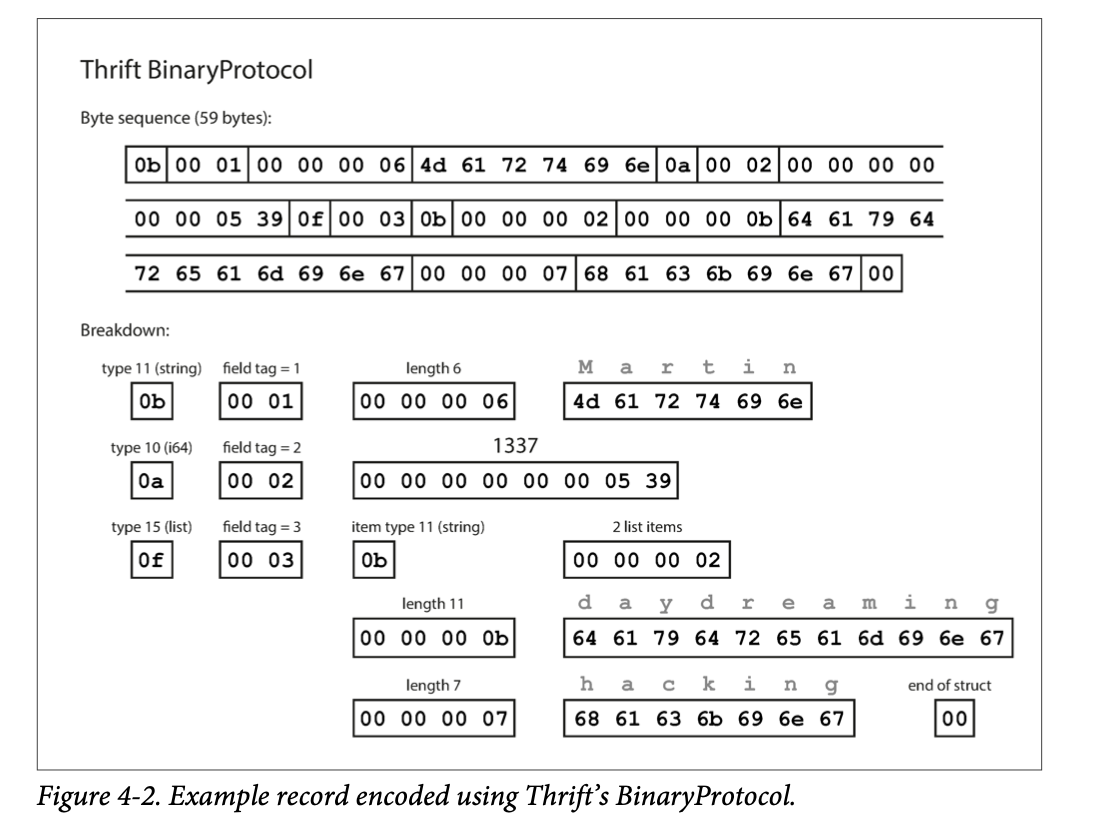 Key difference from MessagePack:
Key difference from MessagePack:
- Field names are encoded as field tags which are numbers (1, ,2, 3…) that appear in schema definition
- Portable and good for migrations/updates since it allows for forward and backward compatibility since the name of the field is decoupled from the actual position in message. Similarities to MessagePack:
- Each field has a type annotations and where required, a length indication.
CompactProtocol: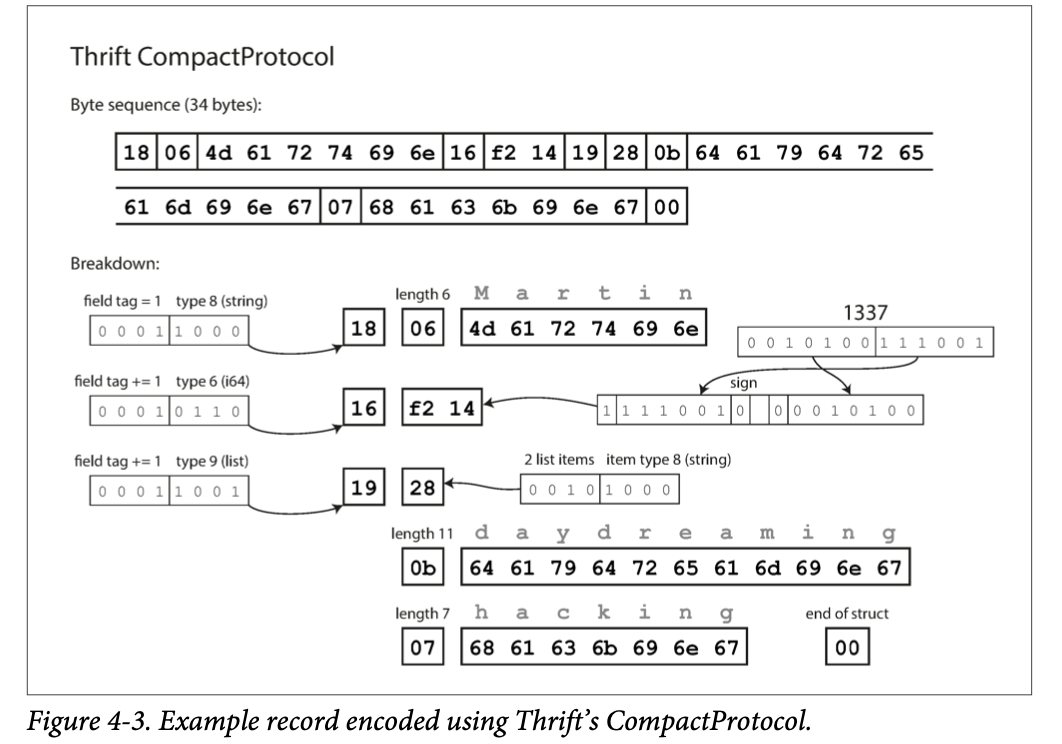 Key difference from BinaryProtocol:
Key difference from BinaryProtocol:
- Packs field type and tag number into a single byte
- Uses variable-length integers by using the top bit within each bytes to deliminate between bytes.
- Writes digits from back to front
Protobuf
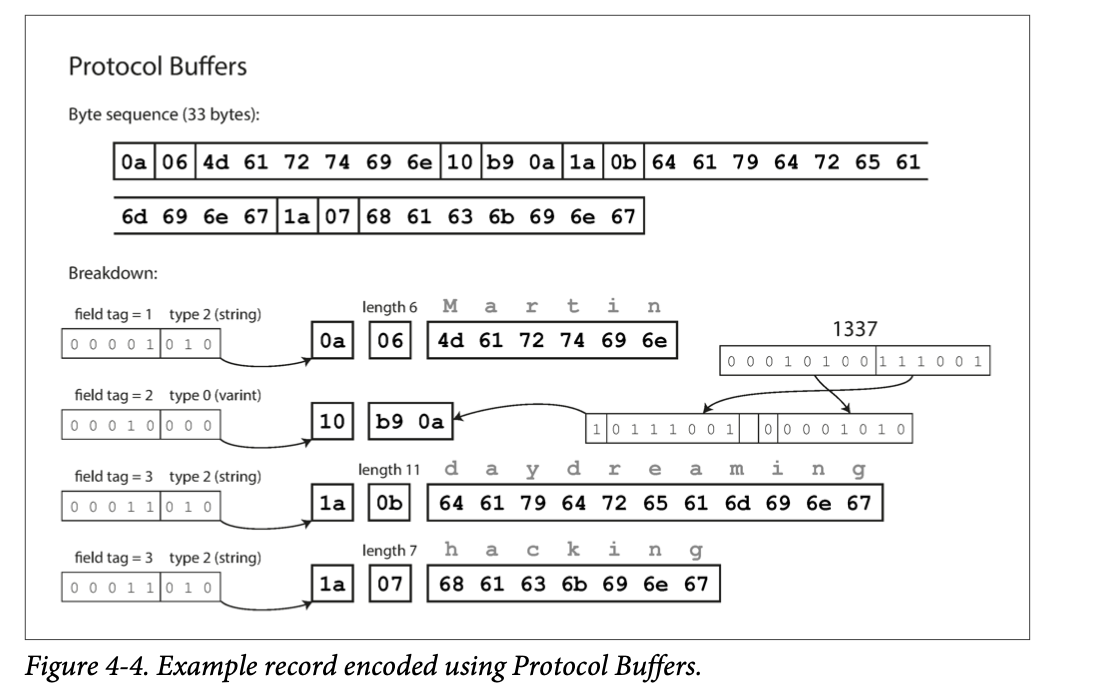 Differences from Thrift’s CompactProtocol
Differences from Thrift’s CompactProtocol
- Bit packing a bit differently
Field Tags and Schema Evolution
Schema Evolution - when schemas changes over time.
Key ideas:
- Encoded data never refers to field names, but field tags are so field names can change.
- Adding new fields to schema will give a new tag number, maintaining forward compatibility
- Old code can read records that were written by new code and not break, just ignores new values
- Each fields have unique tag numbers so new code can always read old data, because tag numbers still have the same meaning
- Only detail is with new fields, it cannot be set as required which will fail on old code.
- Removing is the same as adding but reversed.
- Can only remove optional fields
- Can’t use the same tag number again
Datatypes and Schema Evolution
May be possible, but risk of losing precision or truncated (32-bit to 64-bit ints).
Protobuf have a repeated marker for fields like required or optional. This makes it okay to change an optional (single valued) field to repeated. Old code only sees last elem. New code sees list with zero or one elements.
Avro
Apache Avro, another binary encoding format, started for Hadoop’s use cases.
An example schema written in Avro IDL (interface definition language)

TODO dyn gen schemas thinking like Solr indexes
The Merits of Schemas
Binary encodings of schemas can provide these benefits:
- More compact than binary versions of textual formats due to omiting field names from the encoded data
- Schema can act as documentation
- Database of schemas allows for checks of forward and backward compatibility of schema changes
- Static type checking
Modes of Dataflow
Most common ways of how data flows between processes:
- Via databases
- Via service calls (REST & RPC)
- Via asynchronous message passing
Dataflow Through Databases
Backward compatibility needed for newer clients who read old database entries.
Forward compatibility needed for older clients who might read entries from newer clients.
For writes, what if a newer client wrote to a record that introduces more fields in newer version. Then an old client updates the record. Should the new fields survive?
Different values written at different times A database generally allows any value to be updated at any time. Which means a database contains values from various times and from different versions of clients: data outlives code.
Rewriting (migrating) data into a new schema is one idea, but it’s expensive to do in a large dataset, so most databases avoid it if possible.
Relational databases allow simple schema changes, such as adding a new column with null value.
Archival Storage Snapshots are typically encoded with the latest schema despite containing different versions.
Dataflow Through Services: REST and RPC
With microservices, services evolve and deploy independently. Much like databases, versioning and compatibility is required since old and new versions might be running at the same time.
Web Services Primer
- REST vs SOAP
- RESTful API can follow a definition format such as OpenAPI / Swagger to describe RESTful APIs and produce documentation RPCs A bit dated on the material. gRPC.
Message-Passing Dataflow
Looking at Asynchronous message-passing system now.
Biggest different is the addition of buffered messages through message broker
Advantages of message broker compared to direct RPC:
- Acts as a buffer; improves reliability
- Automatically redeliver messages to a crashed processes
- Avoids the sender needed to know client info, doesn’t require server to maintain connections
- One message can be sent to several recipients
- Decouples sender from recipient
Sender normally doesn’t expect to receive a reply to its messages. Message passing is usually one-way.
Message Brokers
General workflow:
- Process sends message to named queue or topic
- Broker ensures the message is delivered to one or more consumers of or subscribers to queue/topic (can have many producers and consumers on the same topic)
Properties to note:
- Topic provides only one-way dataflow, producer → consumer
- Message brokers typically don’t enforce any particular data model, just a sequence of bytes
Distributed Actor Frameworks
The actor model is a programming model for concurrency in a single process. Rather than dealing with threads, logic is encapsulated in actors. Each actor represents one client/entity. It communicates with other actors by sending and receiving asynchronous messages.
Distributed actor frameworks - programming model is used to scale an application across multiple nodes by using the same message-passing mechanism between actors.
Examples: Akka, Orleans, Erlang/OTP (has actors built in)
- Sandboxed actors might be interesting to see with AI, maybe in companies like Daytona. Wondering if there’s some connections there.
Summary
Key ideas:
- Design for evolvability, data lasts longer than code.
- During rolling upgrades, assume different nodes are running the different versions of our application code
- Several data encoding formats and compatibility properties:
- Programming language-specific encodings → often bad, single language
- Textual formats: JSON, XML, and CSV → widespread, readable, but heavy and vague on datatypes
- Binary schema-driven formats: Thrift, Protocol Buffers, and Arvo → compact, efficient encoding with forward/backward compatibility, NOT human readable and need to be decoded to be
- Areas where data encodings are important:
- Databases
- RPC and REST APIs
- Asynchronous message passing (message brokers or actors)