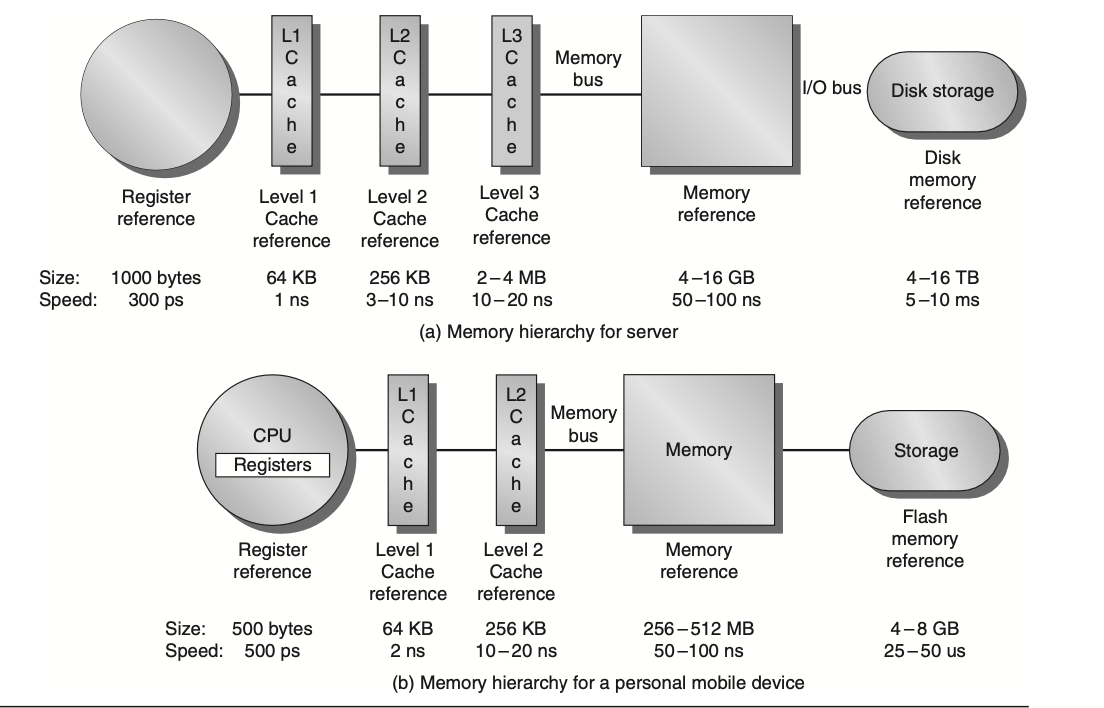
Big Idea
Programmers would want unlimited amounts of fast memory, the economical solution is to create a memory hierarchy that takes advantage of locality.
In most cases data in lower level area are a superset of the next higher level, called inclusion property, like caches are a subset of the total data.
Static power - consumption of power as both leakage when not operating Dynamic power - consumption of power when performing a read or write
Memory Hierarchies
- Word - smallest accessible chunk in system
- Block - multiple words
- Tag - indicates which memory address a cache block corresponds to
A key design decision where blocks (or lines) can be placed in a cache
- Set associative - set is a group of blocks in the cache
- Finding a block consists of first mapping the block address to set then searching the set
- One way is
(block address) MOD (number of sets in cache)
- n-way set associative - n blocks in set
- direct-mapped cache - 1 block / set
- fully associative cache - 1 set, block can be placed anywhere
Updating Cache
Caching data for reads are EASY!
- Since cache and memory would be identical Caching data for writes is hard…
- How can the copy in the cache and memory be kept consistent?
Two main strategies:
- write-through cache updates item in cache and updates to the block in the lower-level memory
- write-back cache only updates copy in cache. When the block is about to be replaced, it’s copied back to memory Both strategies use a write buffer to allow the cache to proceed as soon as the data are placed in the buffer. As opposed to waiting the full latency to write the data in memory
- Uses dirty bit that indicates whether the block is dirty (modified while in cache) or clean (not modified)
- write buffers lowers the chance of write stalls
Since the data are not needed on a write, there are two options on a write miss:
- Write allocate - block is allocated on a write miss, followed by the write hit actions above. Write misses act like read misses
- No-write allocate - write misses do not affect the cache. Instead, the block is modified only in the lower-level memory
- key idea: putting blocks in cache is a waste of memory if it’s not read soon
- reads might add to cache so write after reads will be hits but not the other way around, since writes are not allocated a block in cache
Performance of cache
Typical causes
- Compulsory - the very first access to a block
- Capacity - cannot contain all the blocks needed during execution, capacity misses due to eviction
- Conflict - block may be discarded and later retrieved if multiple blocks map to its set and access to different blocks are intermingled. AKA: thrashing in the context of not having enough capacity
- With multithreading and multiple cores… coherency - misses due to cache flushes to keep multiple caches coherent in a multiprocessor
Average memory access time - factors in misses
- Hit time - time to hit in cache
- Miss rate - fraction of cache accesses that result in a miss
- Miss penalty - time to replace the block from memory
Basic Cache Optimizations
- Larger block size to reduce miss rate
- Take advantage of spatial locality and increase the block size!
- Can increase capacity or conflict misses
- Bigger caches to reduce miss rate
- Reduce capacity misses by increasing cache capacity
- Higher associativity to reduce miss rate
- Reduces conflict misses, more blocks with same set index
- Increases hit time to search through set
- Multilevel caches to reduce miss penalty
- Rather than deciding between to make cache hit time face to keep pace with clock rate or large to reduce the gap between processor access and main memory access…
- Create levels of caches between
- ends ups with access time
- Rather than deciding between to make cache hit time face to keep pace with clock rate or large to reduce the gap between processor access and main memory access…
- Giving priority to read misses over writes to reduce miss penalty
- reads are more likely to reaccess cache
- Write buffer can be used to check for RAW hazard
- Avoiding address translation during indexing of the cache to reduce hit time - Use page offset to index the cache (identical in both virtual and physical addresses)
10 Advanced Optimizations of Cache Performance
5 key categories of optimizations
- Reducing the hit time - with small and simple first-level caches and way-prediction
- Increasing cache bandwidth - pipelined caches, multibanked caches, and nonblocking caches
- Reducing the miss penalty - critical word first and merging write buffers
- Reducing the miss rate - compiler optimizations
- Reducing the miss penalty or miss rate via parallelism - hardware prefetching and compiler prefetching
1. Reducing hit time with small and simple first-level caches to reduce hit time
- Big idea: utilize the fast clock cycle of a processor, although limited by the power limitations
- Category: Reduces hit time
- In recent designs three factors that have lead to the use of higher associativity in first-level caches
- Many processors take at least 2 clock cycles to access the cache and impact of a longer hit time may not be critical
- To keep the TLB out of the critical path, almost all L1 caches should be virtually indexed
- Multithreading, conflict misses can increase, making higher associativity more attractive.
2. Way Prediction to Reduce Hit Time
Reduces conflict misses yet maintains hit speed of direct-mapped cache.
- Category: Reduces hit time Way prediction - extra bits are kept in the cache to predict the way or block within the set of the next cache access.
- This prediction means the multiplexor is set early to select the desired block
- Only a single tag comparison is preformed that clock cycle in parallel with reading the cache data.
- A hit results in direct access speeds
- A miss results in needing to check the other ways (blocks in set)
3. Pipelined Cache Access to Increase Cache Bandwidth
Pipeline cache access so that the effective latency of a first-level cache hit can be multiple clock cycles, giving fast clock cycle time and high bandwidth but slow hits.
- Category: Increases Cache Bandwidth
4. Nonblocking Caches to Increase Cache Bandwidth
For pipelined computers that allow for OOO execution, processor do not need to stall on a data cache miss…
- Category: Increases Cache Bandwidth
- Also reduces miss penalty A nonblocking cache or lockup-free cache allows the data cache to continue supply cache hits during a miss
- “Hit under miss” - cache can still service a hit when a miss occurs
- Need hw to maintain misses
- “Miss under miss or hit under multiple miss - attemps to lower miss penalty if cache can overlap multiple misses
- “Hit under x miss - cache services after x misses
5. Multibanked Caches to Increase Cache Bandwidth
- Category: Increases Cache Bandwidth
- Divide cache into independent banks that can support simultaneous accesses
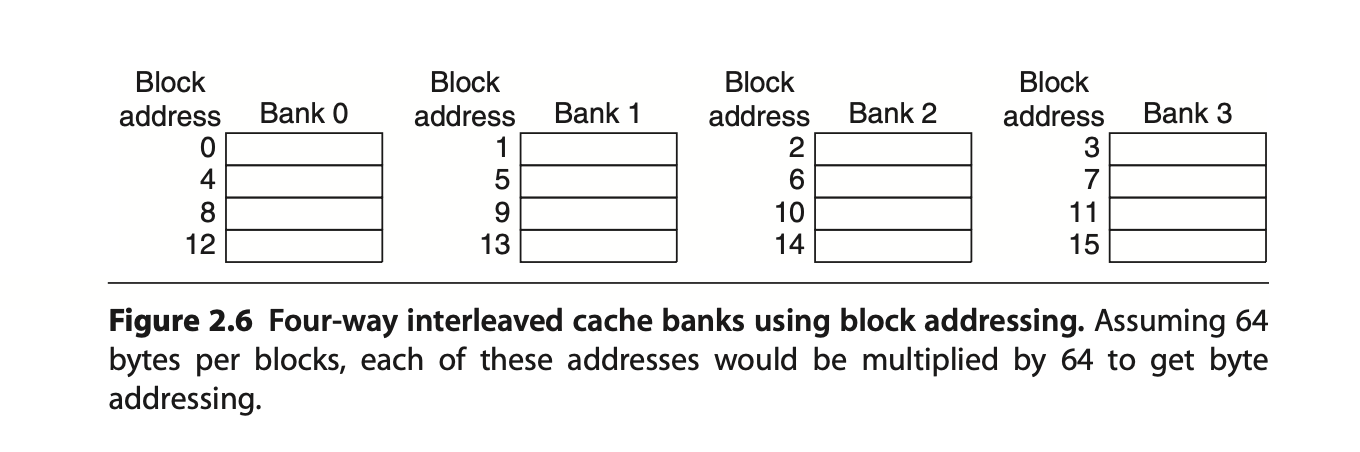
- Depends of accesses spreading themselves among banks
- Sequential interleaving - using
address % # of banksto spread addresses among the banks
6. Critical Word First and Early Restart to Reduce Miss Penalty
- Category: Reduce Miss Penalty
- Don’t wait until the full block to be loaded before sending the requested word and restarting the processor
- Strategies:
- Critical word first - request the missed word first from memory and send it to the processor as soon as it arrives; let the processor continue execution while filling the rest of the words in the block
- Early restart - fetch the words in normal order, but as soon as the requested word of the block arrives send it to the processor and let the processor continue execution
- Most benefits at large cache blocks to stop reading the block as early as possible.
7. Merging Write Buffer to Reduce Miss Penalty
- Write-through caches rely on write buffers which hold dirty data to write in the background
- Write-back caches rely on write buffers when a block is evicted
- big idea
- Merge entries in write buffer that share block addresses and combine the data in both entries
- Reduces stalls due to the write buffer being full by reducing entries
8. Compiler Optimizations to Reduce Miss Rate
- Loop Interchange
- reordering to maximize use of data in cache block before discarded
- Maximizes array locality

- Blocking
- Improves temporal locality to reduce misses
- Instead of operating on entire rows or columns of an array, blocked algorithms operate on submatrices or blocks
TODO review
9. Hardware Prefetching of Instructions and Data to Reduce Miss Penalty or Miss Rate
Prefetch items before the processor requests them. Both instructions and data can be prefetched, either directly into the caches or into an external buffer that can be more quickly accessed than main memory.
- Instruction prefetch is frequently done in HW outside of cache
- Fetches two blocks on a miss: the requested block and the next consecutive block
- Missed block placed into cache
- next consecutive block placed into instruction stream buffer
- Fetches two blocks on a miss: the requested block and the next consecutive block
- Research found that 8 stream buffers could capture 50% to 70% of all misses.
10. Compiler-Controlled Prefetching to Reduce Miss Penalty or Miss Rate
Compiler inserts prefetch instructions to request data before the processor needs it
- Register prefetch - will load the value into a register
- Cache prefetch - loads data only into the cache and not the register
Either can be faulting or nonfaulting
- Address does or does not cause an exception for virtual address faults and protection violations
- Loads are “faulting register prefetch instruction”
- Nonfaulting prefetches turn into no-ops if they normally result in an exception
Most processors today offer nonfaulting cache prefetches also called nonbinding prefetch
Prefetching makes sense only if the processor can proceed while prefetching the data
- caches don’t stall during prefetching
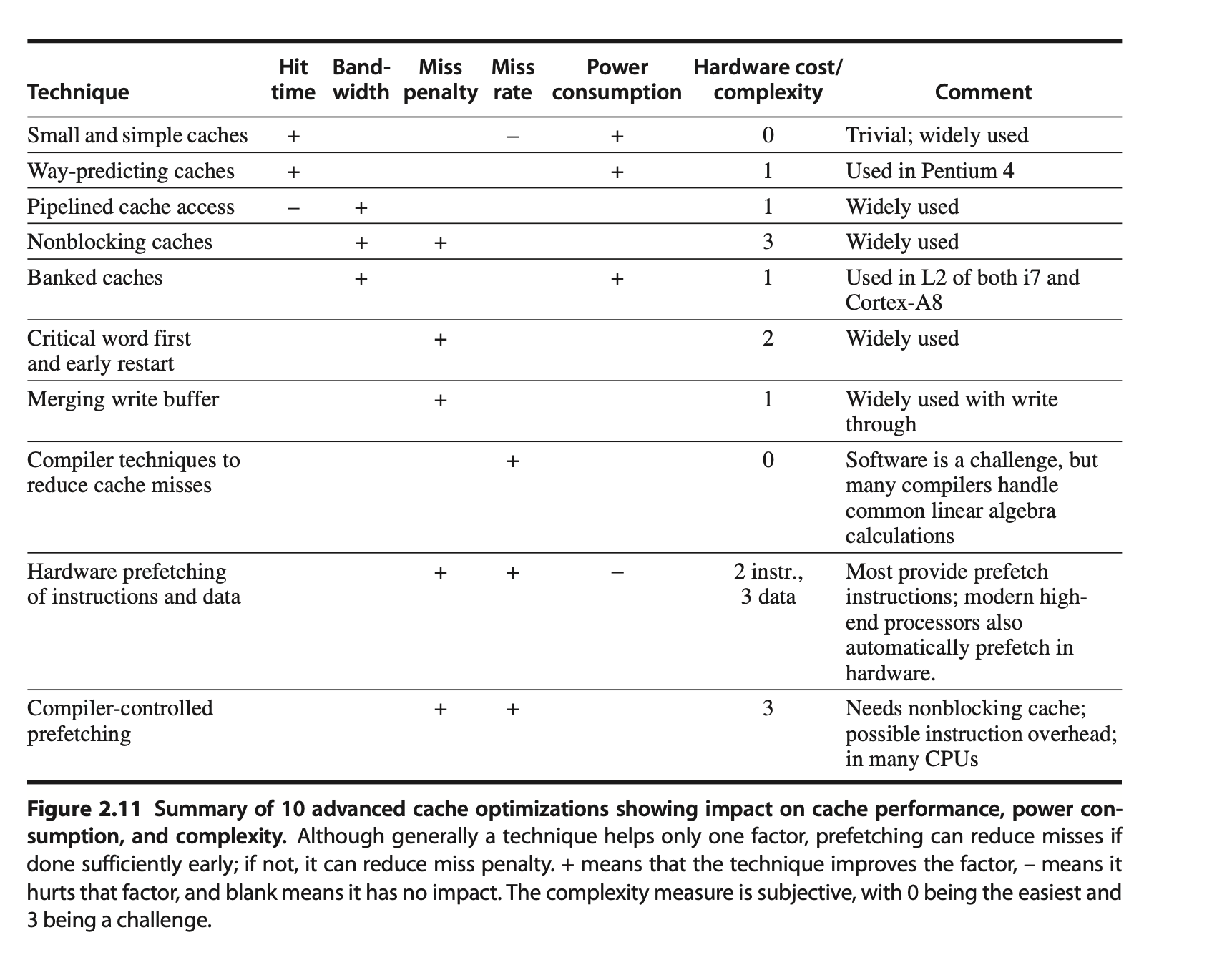
Memory Hierarchies in the ARM Cortex-A8 and Intel Core i7
<TODO>