Motivation
- Modern processors fail to utilize execution resources well
- Start to see wide superscalars that weren’t utilized well
- IPCs ⇐ 1
- No single culprit
- Attacking the problems one at a time always had limited effectiveness (e.g. specific latency-tolerance solutions)
- However, a general latency-tolerance solution which can hide all sources of latency can have a large impact on performance
- Main issue is HW multithreading
HW multithreading
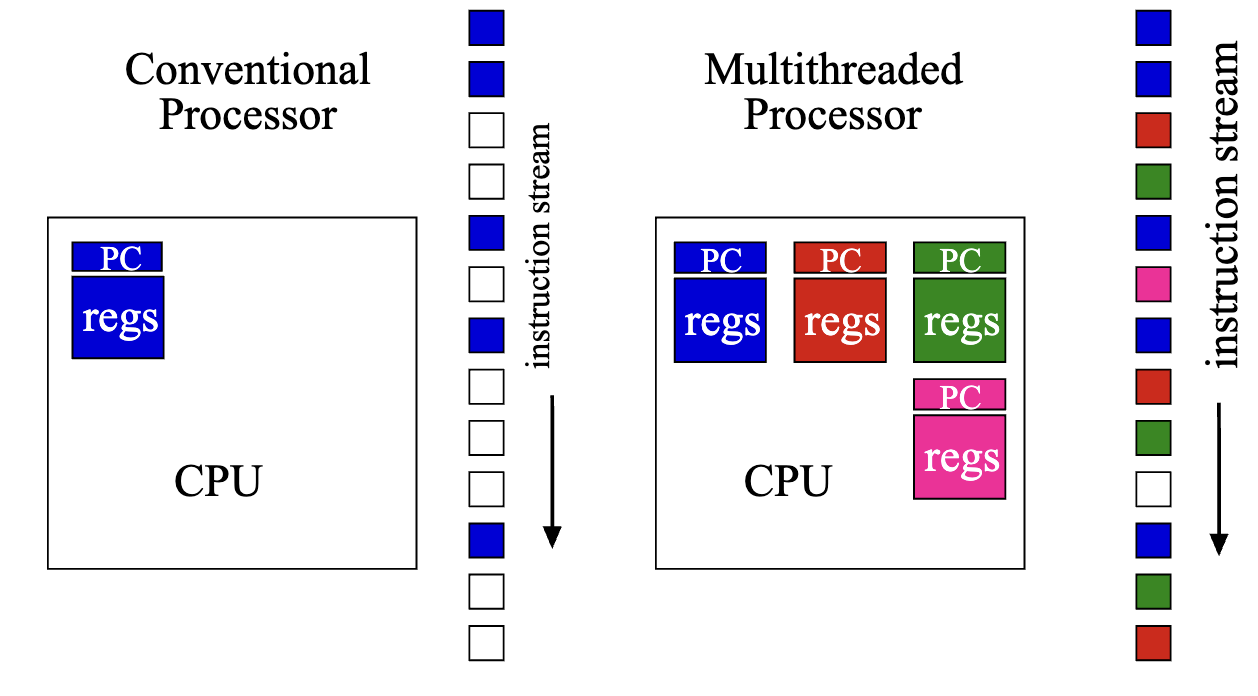
- Left: One thread on CPU at once, need to do a context switch to run instructions from another thread
- Right: Multiple threads, multiple PCs and registers. Execute instructions from multiple threads at once
- can think of it as HW context switch
Superscalar Execution
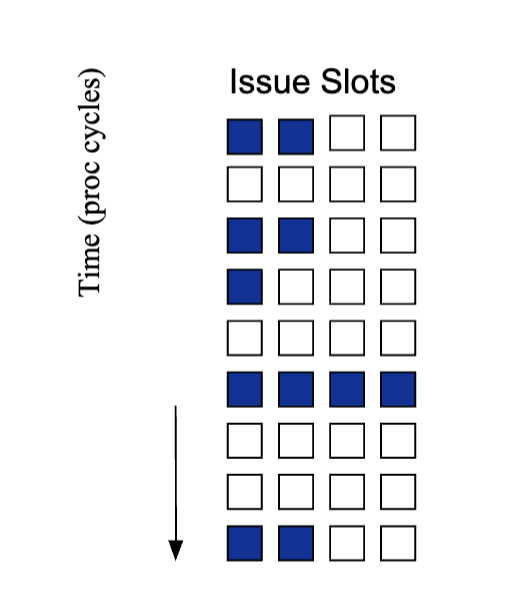
Horizontal Waste vs Vertical Waste
Lack of ILP in superscalar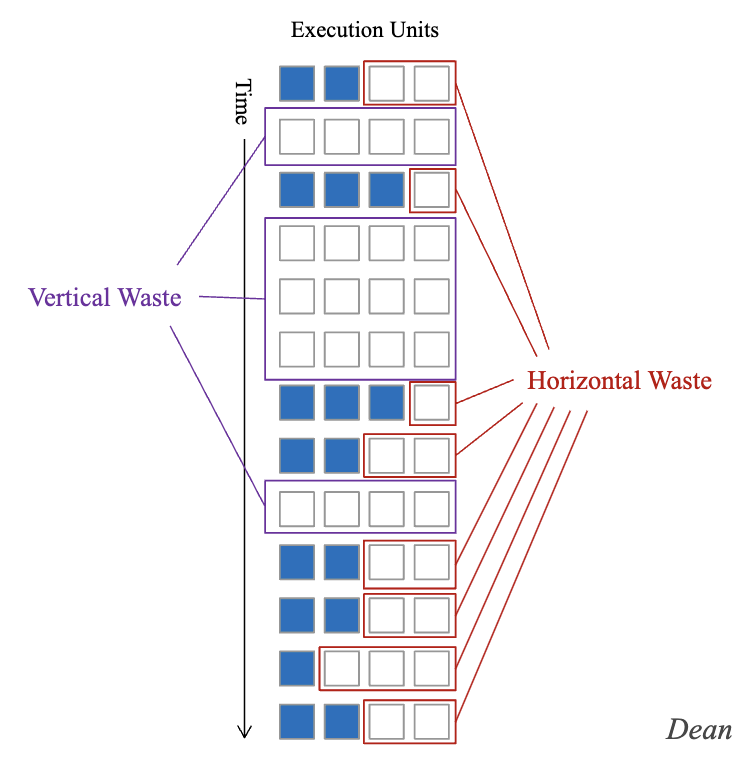
- Vertical waste - nothing is done in the cycle
- Horizontal waste - not utilized unit in cycle
- What kinds of hazards or scenarios causes vertical or horizontal waste?
Superscalar Execution with Fine-Grain Multithreading
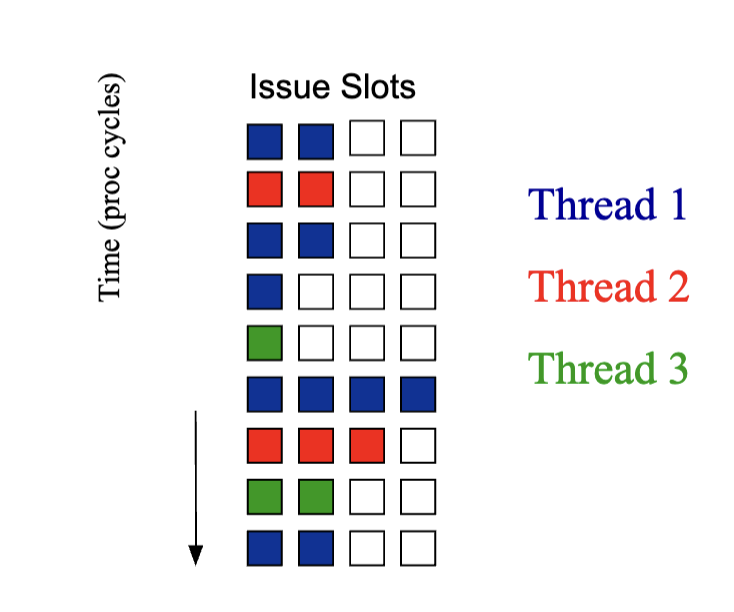
- Able to take advantage of vertical waste but horizontal waste increases, because there are more opportunities where the thread is taking some but not all available slots
- Notice only instructions from one thread runs per cycle
Simultaneous Multithreading
Throw out context switch, issue what ever instructions in machine
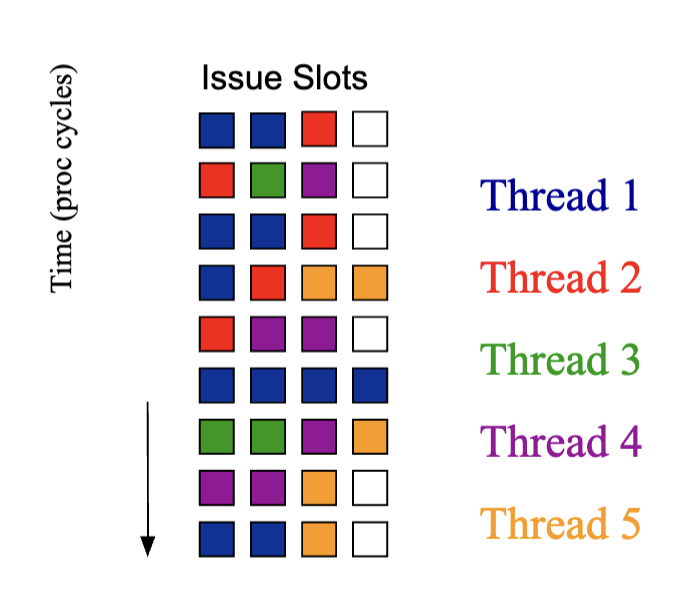
- Any thread in cycle
Coarse-Grain Multithreading
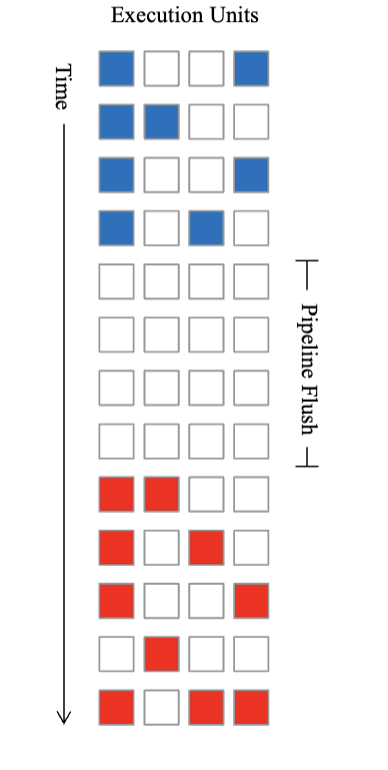
- HW context switch, can hide 200 cycle latency (eg. miss to memory) flush < 200 cycles, can’t hide small latencies
- Pipeline very similar to conventional pipeline, but with extra hardware contexts stored “nearby”
- Replaced the software context switch with the hardware context switch
Fine-Grain Multithreading
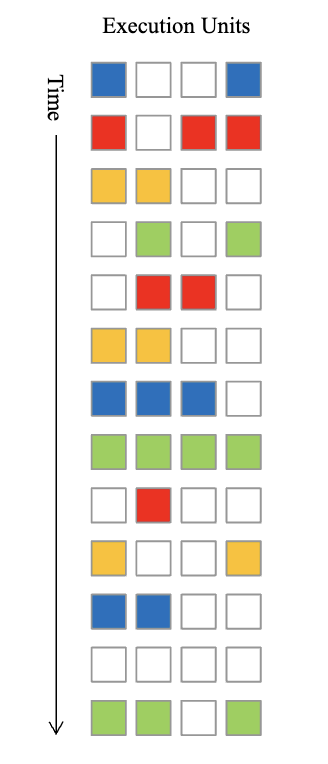
- HW context (thread state) must be stored within the pipeline, but cannot necessarily access multiple contexts at once (within a single pipeline stage)
- Limited to how much parallelism you can find in a single thread in a single cycle
Now SMT
Goals
- Minimize the architectural impact on conventional superscalar design
- Minimize the performance impact on a single thread
- Key mindset change at the time where people assumed that you can either run many threads fast and one thread slow or vice versa
- Achieve significant throughput gains with many threads
SMT on inorder vs out of order
- Out of order machines has register renaming which made SMT easier
- with inorder is much more difficult
Bottlenecks of Baseline Architecture
- Round Robin
- Instruction queue full conditions (12-21% of cycles)
- Lack of parallelism in the queue
- Fetch throughput(4.2 instructions per cycle when queue not full)
Improving Fetch Throughput
ICount!
Prediction - count of instructions from the front of machines, as their instruction count goes up = more blocked instructions (head of line blocking)
TODO watch lecture and understand up or down correlation
SMT
- dip on single thread performance because of a longer pipeline