Software/Compiler Optimization
Big idea
- Instructions cache
- Reorder procedures in memory to reduce misses
- profiling to look at conflicts
- Data cache
- Merging Arrays
- Improve spatial locality by single array of compound elements vs 2 arrays
- Example:
- key value, can be represented with two arrays, bundle together to provide spacial locality
- Loop interchange
- Change nesting of loops to access data in order stored in memory
- Example
- Multi loop code that accessing a matrix in strides of row in the inner loop. Better locality can be achieved by row column order, by sequential access through columns in inner loop or sequential access in memory.

- Multi loop code that accessing a matrix in strides of row in the inner loop. Better locality can be achieved by row column order, by sequential access through columns in inner loop or sequential access in memory.
- Loop fusion
- Combine 2 independent loops that have same looping and some variables overlap
- Example:
- Below, we get locality between
a[i][j] and c[i][j]when fused. Otherwise, you would lose botha[i][j] and c[i][j]values to the cache in the second pass (have to start from the beginning, 2 misses before vs 1 miss after)
- Below, we get locality between
- Blocking
- Improve temporal locality by accessing “blocks” of data repeatedly vs going down whole columns or rows
- Example:
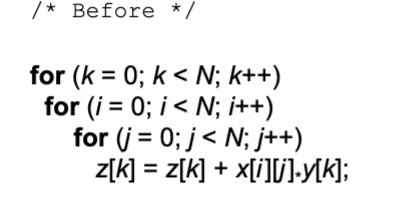
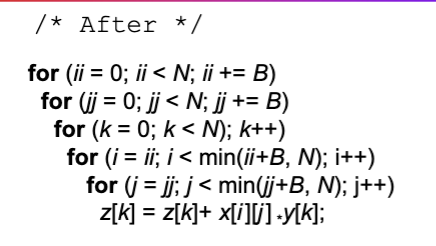
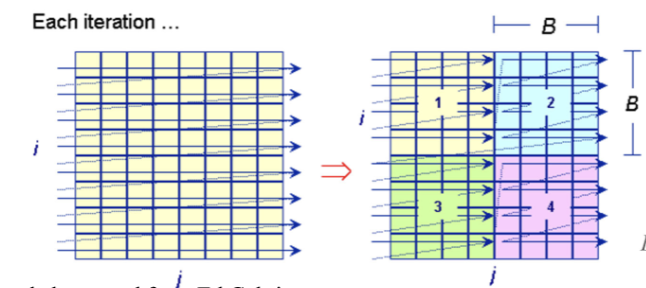
- The idea is to partition the big matrix into smaller blocks that can fit into cache to maintain
x[i][j]temporal locality
- Merging Arrays
Reduce the miss penalty
Read priority over write
- load > stores
- general principles, don’t stall for stores
- Compiler → register allocation → done with store
- Easiest method: to resolve RAW hazards is to send them in order
- Problem: loads get stuck behind stores
- Solution: prioritize loads, let loads pass stores in pipelines
- As long as write buffer not full (structural hazard)
- Let store buffer empty out as bandwidth allows
- Need to identify if load depends of store
- How write back caches handle this?
- Read miss may require write of dirty block
- Copy dirty block to a write buffer, read, then write
- Less CPU stalls, don’t need to wait for write to higher memory
Non-blocking Caches to reduce stalls on misses
- Non-blocking cache (or lockup-free cache) allows the data cache to continue to supply cache hits during a miss
- hit under miss reduces the effective miss penalty by being helpful during a miss instead of ignoring the requests of the CPU
- requires more metadata to know if the hit is determined by the missed data
- hit under multiple miss or miss under miss - further lower the effective miss penalty by overlapping multiple misses
Multi-level caches
Primary way to reduce miss penalty
- Second level cache

- Local vs Global cache miss rates
- Local miss-rate - misses in the cache / total number of mem accesses to this cache ()
- Global miss rate - misses in this cache / total number of memory accesses generated by CPU ()
- Why is 10% miss rate for L1 cache and 40% L2 cache is reasonable?
- L1 gets the “easy” locality hits, if L1 gets updated with local hits. If L1 misses, it means it’s a harder locality hit, one that is not explained by L1 to L2. Which means the miss chance would be higher.
- L1’s highest priority is fast hit time
- L2’s highest priority is low miss rate
- L1 caches low associativity → fast hit rate
- L2 caches high associativity → lower miss rate
- Block size? L1 L2? → same, easier to reason
- nobody changes block size
Policies
- Inclusion policy
- Inclusive
- Everything in L1 is also in L2
- not the other way around
- Better for read heavy?
- Everything in L1 is also in L2
- Exclusive
- Nothing in L1 is also in L2
- effective utilization, performance
- Performance overhead in communication, every cache line in L1 is considered dirty
- Better for write heavy?
- Non-inclusive
- Some (likely most, but not all) lines in L1 are in L2
- Let caches do whatever they want
- Common case now
- cache coherency issues
- Dynamic scheduling??
- Inclusive
Reducing Miss Penalty Summary
- Three techniques
- Read priority over write on miss
- Non-blocking Caches (Hit Under Miss)
- Multi-level Caches
Reduce the time to hit in the cache
Simple L1 caches, small
- I and D used to be Direct Mapped, on chip for speed
- out-of-order execution reduce latency which made a huge difference here
- load → add in inorder machine makes load speed important, but with OOO, not so much anymore since add can be ran prior to load
Way Prediction
In direct mapped cache you don’t have to do a tag lookup
- done in parallel N-way cache makes set lookup and tag look up now a serialized processes.
- Mimic directed mapped hit performance Find set, match tag
Virtual Caches
TLB is the bottleneck on the critical path of virtual → physical
- TLB - fast cache of page table, HW
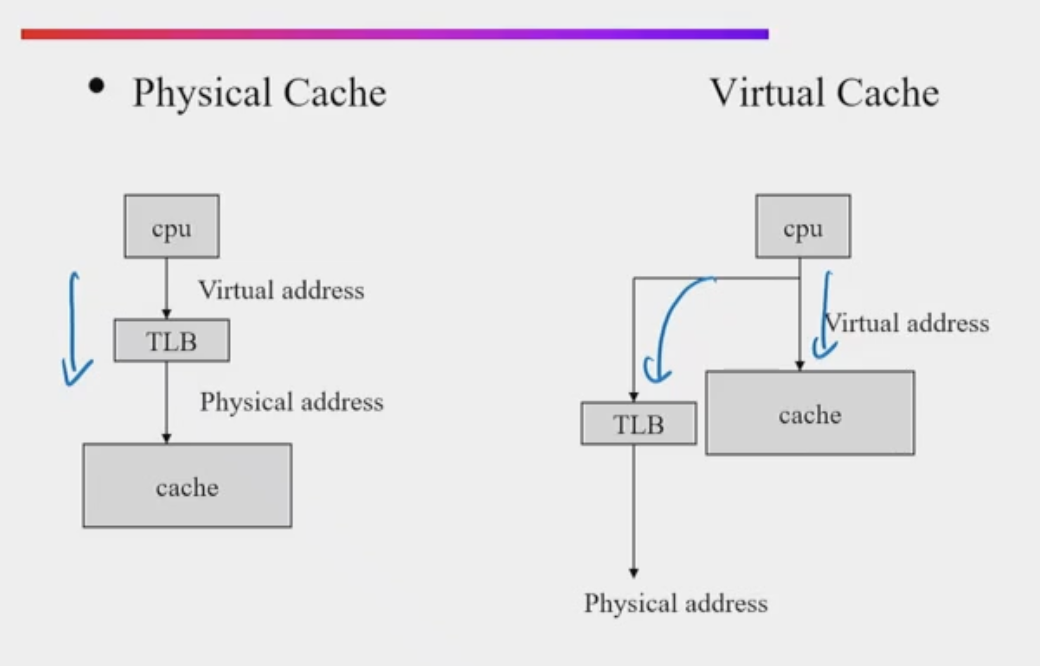
Why don’t we just send virtual address to cache?
Also called virtually addressed cache or virtual cache
Issues:
- Every time process is switched logically, must flush the cache (invalidate)
cost = time to flush + "compulsory" misses from empty cache
- Aliasing problem with virtual addresses, say 2 diff processes
- two different virtual addresses map to same physical address
- Conflicting blocks in caches are knocked out
- I/O must interact with cache…
- Solutions to aliases
- HW that guarantees that every cache block has unique physical addresss
- SW guarantee: lower n bits must have same address; as long as covers index field and direct mapped, they must be unique; called page coloring
- not used anymore, due to direct mapped constraint
- Solution to cache flush
- Add process identifier tag that identified processes as well as address within process; can’t get a hit if wrong process
Current Implementation - Virtually indexed physically tagged!
 Note: If index and block are within page offset, TLB translation can be done in parallel because it only affects the high bits of virtual page number. Cache can still check for set hit or miss. Although still need to wait for TLB for tag hit or miss
Note: If index and block are within page offset, TLB translation can be done in parallel because it only affects the high bits of virtual page number. Cache can still check for set hit or miss. Although still need to wait for TLB for tag hit or miss
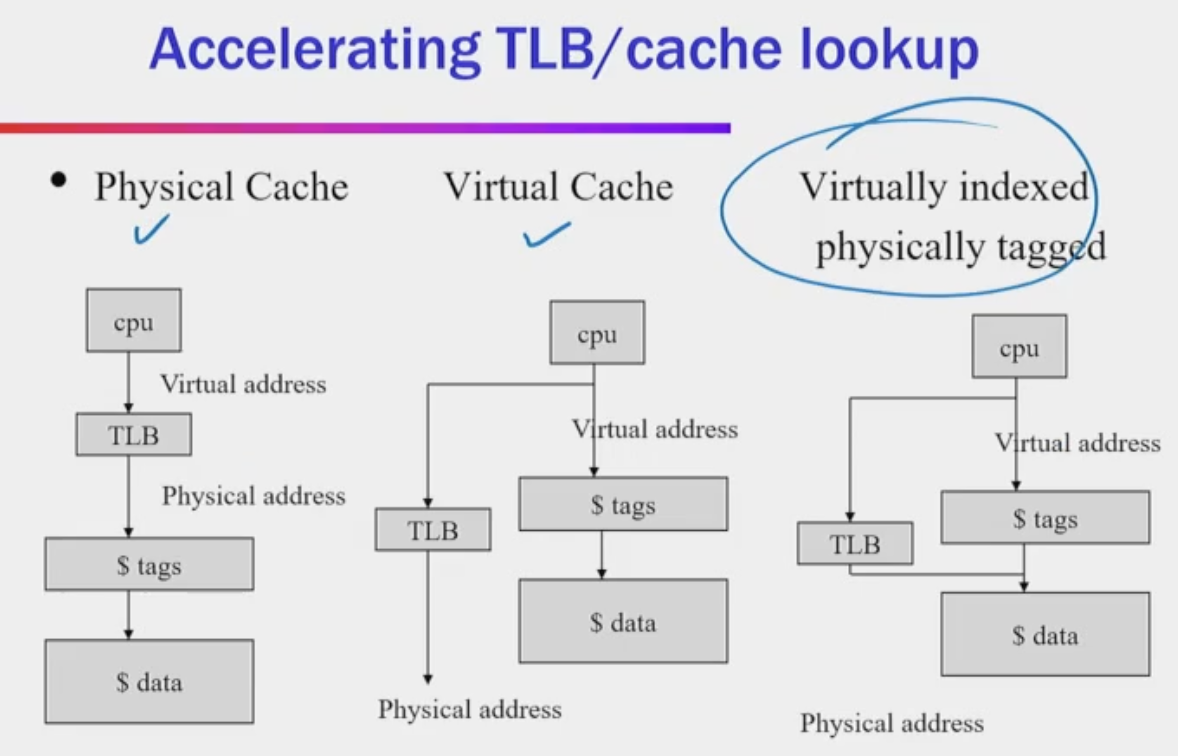
- Tag check based off of physical address
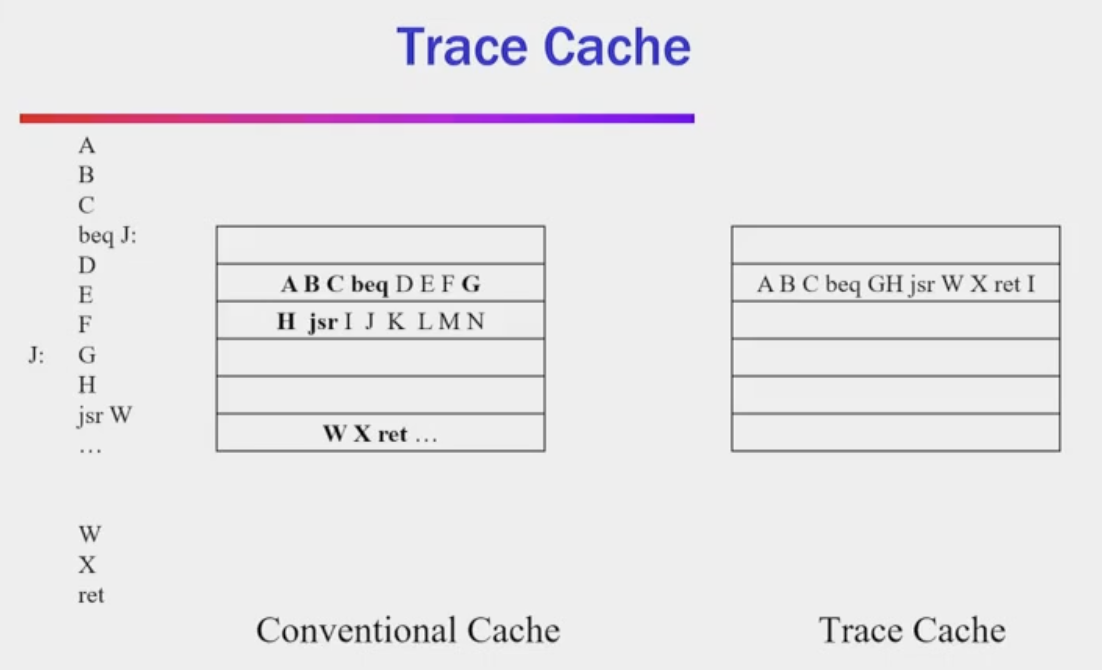
Trace Caches
- Handles fetch bottleneck - cannot execute instructions faster than you can fetch them into the processor
- For wide superscalars this can be a challenge keeping the CPU fed
- too many branches
- Cannot typically fetch more than about one taken branch per cycle
- For wide superscalars this can be a challenge keeping the CPU fed
- Trace cache is an instruction cache that stores instructions in dynamic execution order rather than program/address order
- Executes in an order than is variable