Cache Updates
Writes updates
- Write through: The information is written to both the block in the cache and to the block in the lower-level memory.
- Write back: The information is written only to the block in the cache. The modified cache block is written to main memory only when it is replaced.
- Just record the fact that this is block is dirty and need to update other caches
Write misses
- write-allocate - make room for the cache line in the cache, fetch rest of line from memory. Then perform write into block
- no-write-allocate (write-around) - write to lower levels of memory hierarchy, ignoring this cache
- Decision is ultimately based on locality, is there locality between writes and loads
- are you reading the data you’re writing
- much more sensitive to latency of loads than stores, typically don’t need to wait for stores to finish
- loads = reads
- stores = writes
Separate Caches for Instructions and Data
Unified cache vs separate instruction and data caches?
This is the norm:
- separated instruction and data cache
- L2 unified
- L3 unified
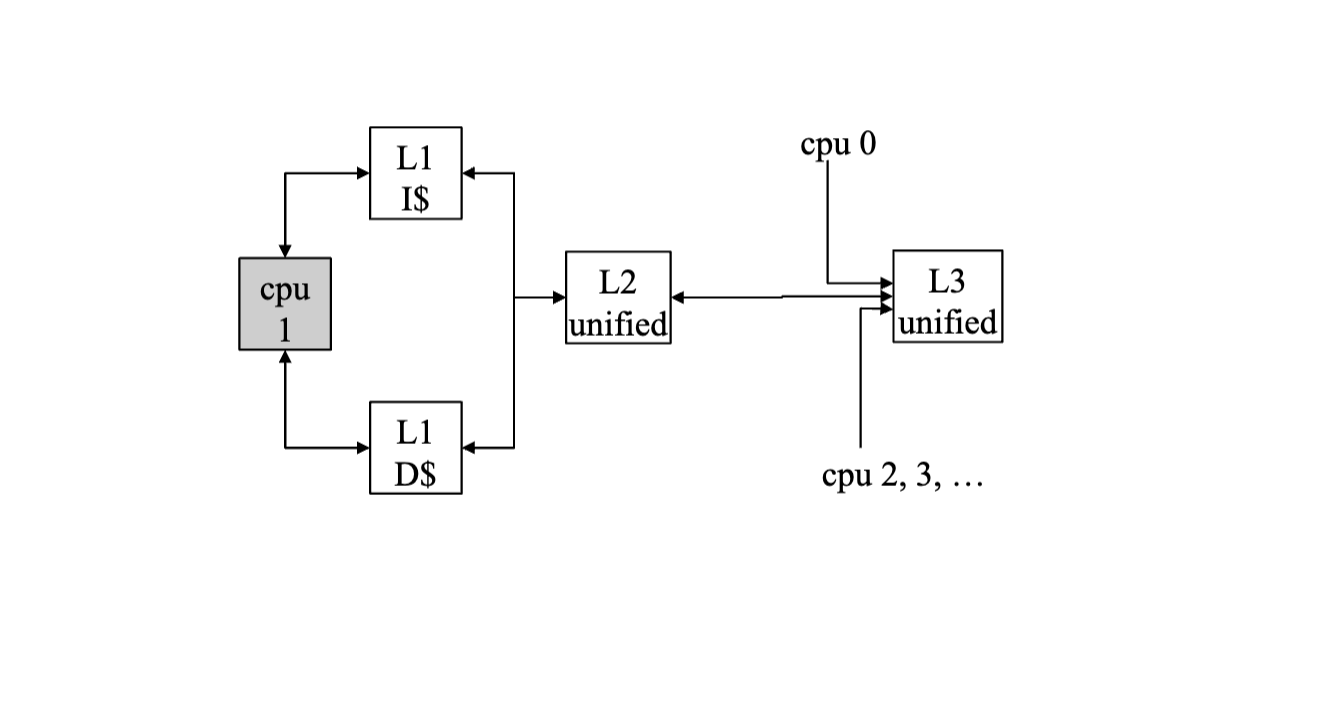 Why this design is performant
Why this design is performant - Instruction fetch is in a different place in the processor than the load store unit
- Place I cache by the instruction fetch
- Place data cache by the load store unit
- Smaller caches are faster! (make each cache half the size by separating them)
- less physical distance
- Multiported caches are inefficient compared to single ported cache
- A port is a hardware access path (separate address lines)
- A cache is multiported when it can service more than one independent read/write request per cycle
Cache Performance
-
- includes Hit Time as part of CPI
- typically will be called “Memory stalls (cycles) per instruction”, MCPI
- or
- or
-
- considering both instruction cache and data cache
Ex
- Instruction Cache miss rate 4%
- Data cache miss rate 9%
- Base CPI 1.1
- 20% of instructions are loads and stores
- Miss penalty = 12 cycles
- CPI?
1.1 + .48 + .216 = 1.796
- Assuming scalar machine, 1 access per instruction
- Superscale, 1 access per x instructions
Improving Cache Performance
AMAT = How are we going to improve cache performance:
- Reduce hit time
- Reduce miss rate
- Reduce miss penalty
Classifying Misses
- Compulsory - first access to a block not in cache
- also called cold start misses or first reference misses
- Capacity - If C is the size of cache (in blocks) and there have been more than C unique cache blocks accessed since this cache was last accessed
- Conflict - Any miss that is not a compulsory miss or capacity miss must be a byproduct of the cache mapping algorithm. A conflict miss occurs because too many active blocks are mapped to the same cache set
- eg. Accesses are targeted on one set leading to misses and other sets are not fully utilized which makes this not a conflict or compulsory miss
Reducing Misses?
- Reducing compulsory misses?
- Increasing cache line → other addresses local within cache line will get loaded in → more hits
- Reducing capacity misses?
- increasing cache size
- Reducing conflict misses?
- increasing associativity
- increasing cache size, spreads out cache blocks
- if 2x cache sets, then now blocks to one set now maps to two sets
- What can the compiler do?
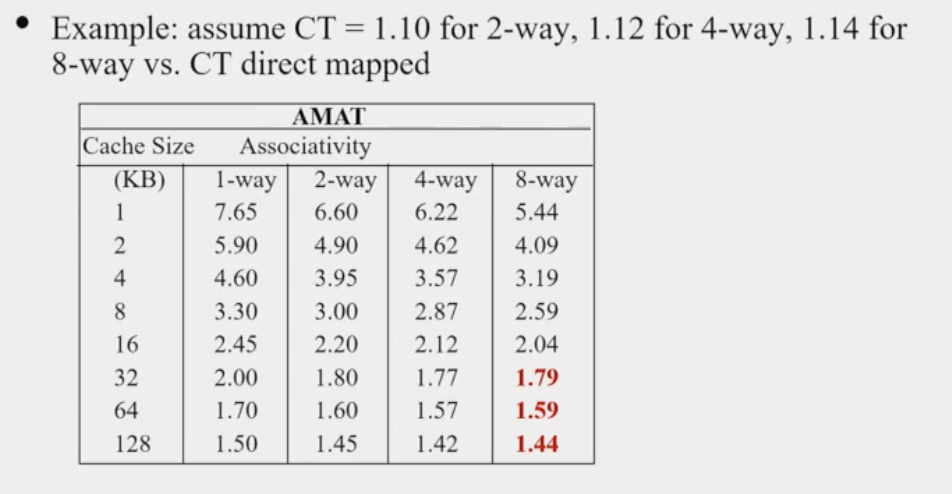
- Avg. Memory access time vs Miss rate
- Increasing Associativity and Cache sizes decreases miss rate
- But there are limits to Associativity (adds latency to cache) and cache sizes
Hardware Prefetching
-
Instruction Prefetching
- Alpha 21064 fetches 2 blocks on a miss
- Extra block placed in stream buffer
- placed in stream buffer rather instead of cache, is when you get a hit in stream buffer and put it into cache, you know to put the next sequential blocks in stream buffer
- On miss check stream buffer
-
Works with data blocks too
-
Prefetching relies on extra memory bandwidth that can be used without penalty
-
Strategies:
- Next line prefetching
- Prefetch the next line on each access
- “Miss on A bring in A + 1”
- Next N lines
- Tagged next line (in cache)
- tag prefetched lines, so that you do a next-line prefetch when you access a prefetched line
- If hit on a prefetch line (A+1), you can prefetch A+2
- tag : usefulness bit - “Last time we missed on line x, prefetchig X + 1 helped”
- Stream Buffers
- offset to next line to access
- Stride-based stream buffers
- mostly modern prefetchers
- offset to any line to access, learn at runtime dynamic
- Pointer based prefetchers
- load this thing into memory and if it is a pointer, load value into cache
- can tell a pointer, if the high bits of the address and high bits of the data are the same it’s probably a pointer
- regions of a process are partitioned by ranges in high bits of address space
- Heap region has distinct high bits, if a value lands in that range and is aligned, probably a pointer
- High bits of pointer address ~= high bits of value (data address), probably a pointer
- Markov prefetchers
- create graphs of typical address
- Fetch-directed instruction prefetchers
- instead of stalling the pipeline, decouple branch predictor and let it run by itself
- creates queue of addresses to prefetch
- dominate prefetcher in Intel
- Next line prefetching
Software Prefetching
Different from HW where the prefetch is embedded into the code
- instruction in ISA that tells HW to prefetch
- System needs to know the difference between loads and prefetches Examples:
- Data Prefetch
- Cache Prefetch: (usually) load into cache
- Special prefetching instructions cannot cause faults; a form of speculative execution
- Issuing Prefetch Instructions (including address calculation) takes time
- Is cost of prefetch issues < savings in reduced misses?
- Helper thread prefetching (speculative precomputation)
- Another thread that runs ahead of main thread to do speculative precomputation