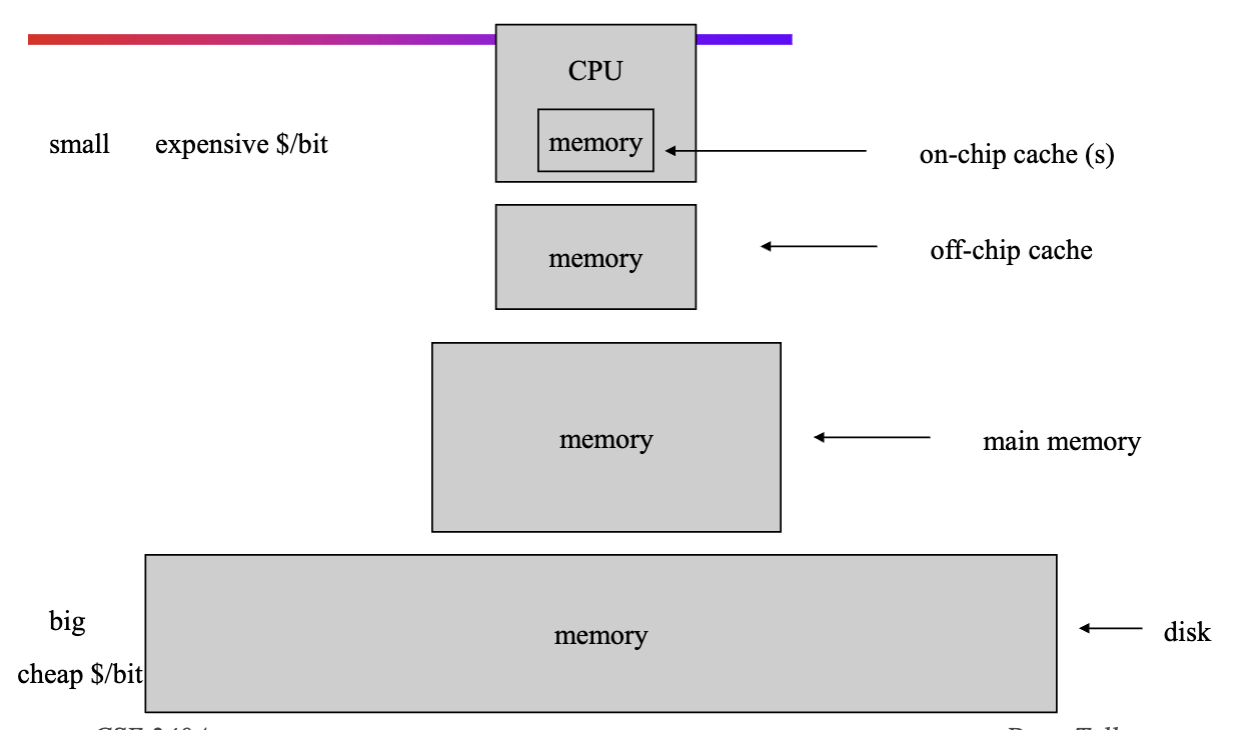
Who Cares about Memory Hierarchy?
Memory Cache
- Can put small, fast memory close to processor
Memory Locality
- Memory hierarchies take advantage of memory locality
- Memory locality is the principle that future memory accesses are near past accesses
- Memory hierarchies take advantage of two types of locality
- Temporal locality - near in time ⇒ we will often access the same data again soon
- Spacial locality - near in space/distance ⇒ our next access is often very close to our last access
- Memory hierarchies exploit locality by caching data likely to be used again
- We can build large, slow memories and small fast memories, but we can’t build large, fast memories
Typical Memory Hierarchy
Cache Fundamentals
- Cache hit - an access where the data is found in the cache
- Cache miss - an access which isn’t in cache
- Hit time - time to access the higher cache
- Miss penalty - time to move data from lower level to upper, then to cpu
- Hit ratio - percentage of access the data is found in the higher cache
- Miss ratio - (1 - hit ratio)
- Cache block size or cache line size - the amount of data that gets transferred on a cache miss, smallest granularity in cache
- Instruction cache - cache that only holds instructions
- Data cache - cache that only caches data
- Unified cache - cache that holds both
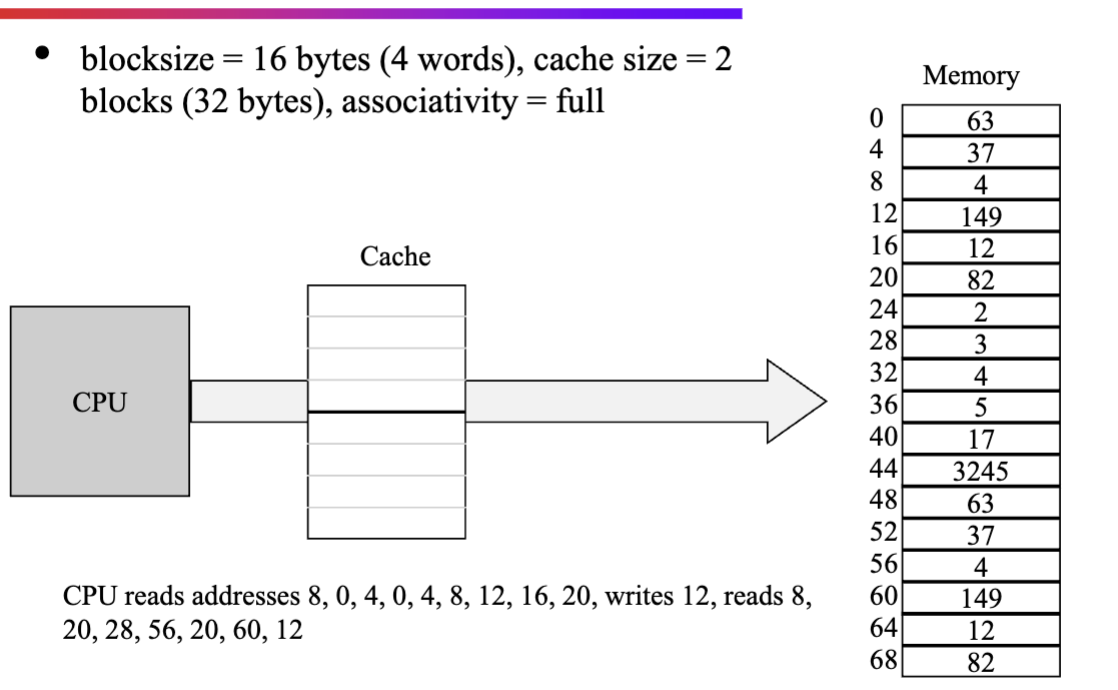
Accessing a simple cache
- Accessing a cache always has to be aligned and by cache line
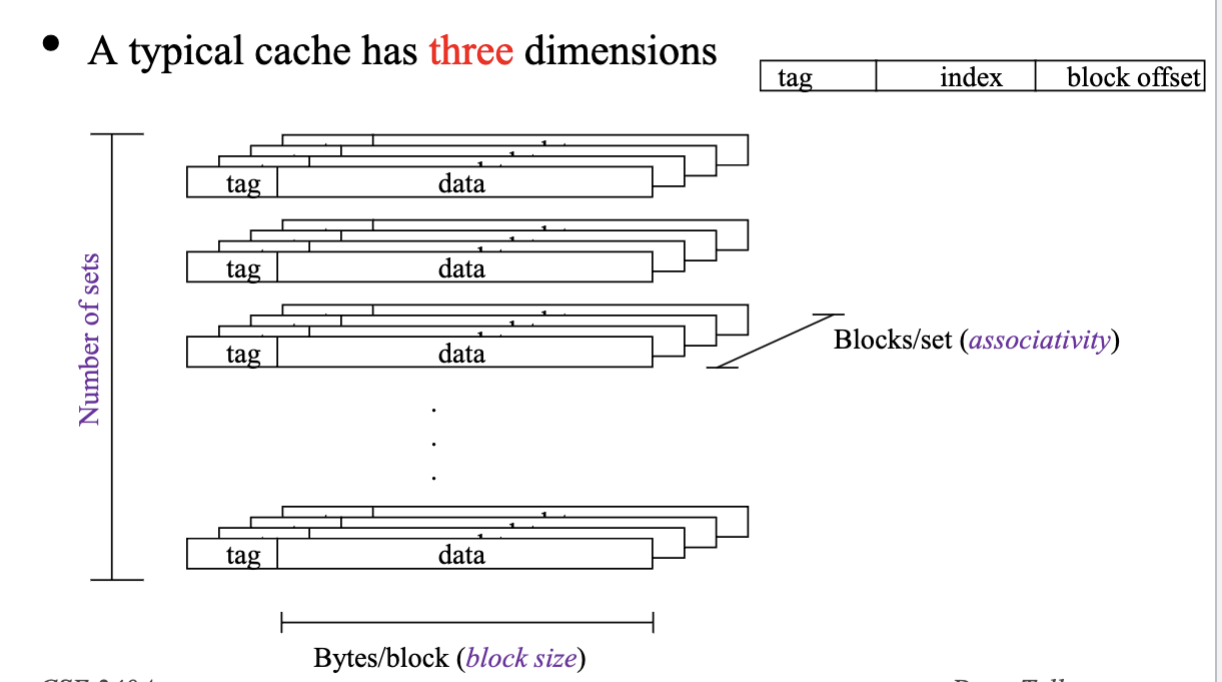
Cache Organization
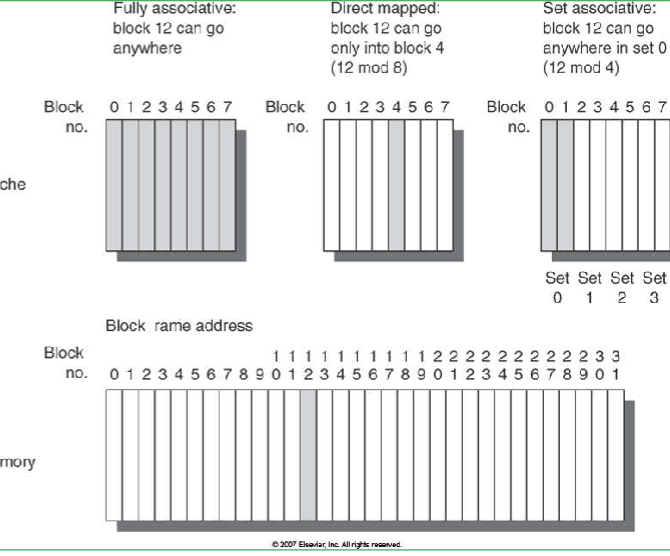
Associativity
- Fully associative, direct mapped, n-way set associative
- index = pointer to set in the cache where a memory location might be cached
- Associativity = degree of freedom in placing a particular block of memory
- Set = a collection of cache blocks with the same cache index
Cache size
-
- total number of blocks =
- Quoted cache size always ignore storage for tags, lru, valid, etc. It only accounts for data storage
- Always the product of above
Cache Access
How is a block found in Cache?
- Tag on each block (metadata for what is in block)
- no need to store index or block offset
- Increasing associativity shrinks index, expands tag
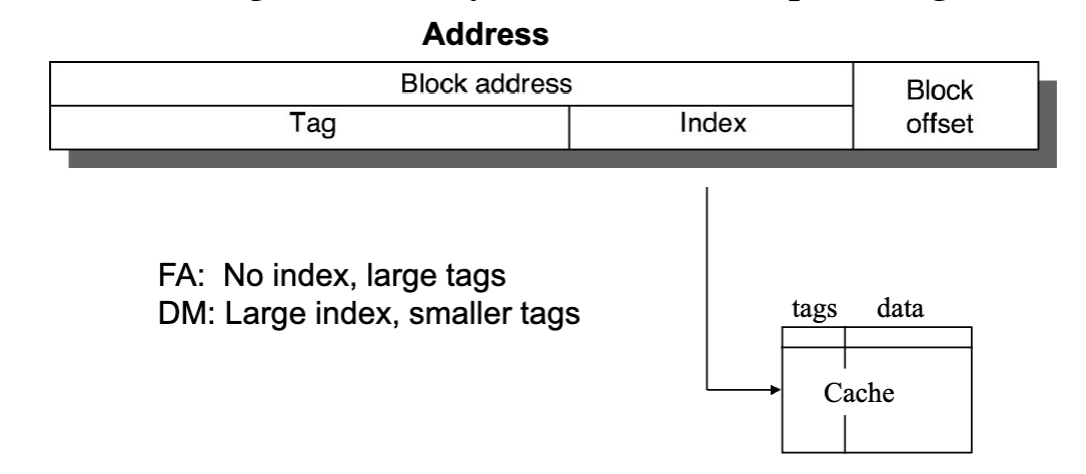
- Every cache block has tags + data
- block offset - what is the data that you actually have to deliever
- index - points to a set in a cache, need enough to point to every unique set in cache
- Uses low bits because addresses conflicts that happen close to each other in memory can cause more damage than farther away.
Cache Access
Ex1 : Given:
- 16 KB, 4-way set-associative cache, 32-bit address, byte-addressable memory, 32-byte cache blocks/lines
- How many tag bits?
address = tag + index + block offset- How big is the block offset?
- 32-byte cache blocks,
- 5 bits for block
- How big is the index?
- `16 KB cache = 16384 Bytes
16384 / 32 blocks = 512 Blocks512 blocks / 4 blocks per set = 128 sets
- Tag is therefore is 32 - 7 - 5 = 20 bits
- Where would you find the word at address 0x200356A4?
- Need 20 bits which is a multiple of 4 (), so 5 hexadecimal digits ()
- maps to 20035
- Now find index and block offset
- 6A4 → 0110, 1010, 0100
- 5 bits is block offset → 00100
- index is 0110 101 or 53 (32 + 16 + 4 + 1)
- Now check 4 different data blocks, specifically their tags
- If one matches 20035 = hit
- Else miss
- if multiple match… something is broken, has to maintain invariant of no dups tags Ex2: Given
- Need 20 bits which is a multiple of 4 (), so 5 hexadecimal digits ()
- 64-bit address, and 32 KB cache with 32-byte blocks, 512 sets
- What is n in n-way SA?
- Cache size =
- 32 KB =
- 1024 blocks =
- 2 blocks / set = n, 2-way associative
Cache Replacement Policies
- Direct Mapped is Easy
- You have to replace the block where the address is going to be indexed at
- Easy decision but might be throwing out something that might be useful
- Set associative or fully associative (exploiting locality)
- longest until next use (ideal, impossible)
- least recently used (a practical approximation)
- requires total ordering within a set! (not enough to just mark the last recently used)
- have to store bits for every entry and shift as evictions happen
- requires total ordering within a set! (not enough to just mark the last recently used)
- pesudo-LRU (NMRU - Not most recently used, NRU - not recently used)
- NMRU - mark one that was not most recently used, randomly choose others
- NRU - each line has a ref bit and hardware sets it on access, on eviction pick any line whose reference bit is zero
- sloppy because once many lines have be accessed, all bits become 1 then it becomes random
- random (easy)
- More associativity = better performance
 Note: old results, doesn’t hold up anymore, percentages are miss rates
Note: old results, doesn’t hold up anymore, percentages are miss rates
LRU - how many bits?
- Assume 8-way SA cache
- How many bits per block?
- 3 bits (0,1,2,3,4,5,6,7) track order of each block,
- How many bits per set?
- 24 bits per set (3 bits * 8 way)
- So how many for n-way SA, per set?
- How many bits per block?
Tree pseudo-LRU
Binary tree, pseudo LRU
- Uses ~n bits per block of n
- recall LRU uses
n log (n)
- recall LRU uses
- Arrange those bits in a binary tree
- Think of each bit saying “The last access was not to this half of my domain”
- Follow the binary tree to find the eviction candidate, on a miss
- On a hit, set all the bits on the path to the block so that they point away from this block
Updating Cache
Loads are easy
- Same value - update on every level
- Generally, end up in all the caches → consistent values Stores (writes) are hard
- Policies:
- Write through - information is written to both the block in the cache and to the block in the lower-level memory
- Pros:
- cache coherency
- Cons
- Memory traffic is high, processor can’t handle that much traffic
- Pros:
- Write back - information is written only to the block in the cache. The modified cache block is written to main memory only when it is replaced
- Pros:
- Shorter latency, assuming simple case
- Lazy updates, not having duplicate works
- Cons:
- Coherence is a bit more difficult
- Pros:
- Write through - information is written to both the block in the cache and to the block in the lower-level memory
- Pros and Cons of each:
- WT: read misses cannot result in writes (because of replacements)
- WB: not writes of repeated writes (lazy updates)
- Write Through always combined with write buffers so that don’t wait for lower level memory