Pipeline Perf.
 Where:
Where:
- BSPI - branch stalls per instruction
- FPSPI - floating point stalls per instruction
- LdSPI - load stalls per instruction When BSPI, FPSPI, LdSPI approach 0, we’re bounded by the base CPI 1 for scalar
Multiple Instruction Issue
Getting CPI < 1
Issuing multiple instructions
- Superscalar
- Variable number of instructions issued each cycle
- Parallelism detected in hardware
- Very Long Instruction Words (VLIW)
- Fixed number of instructions issued each cycle
- Parallelism scheduled by the compiler
- Intel IA-64 (Itanium)
- Popular for embedded processors, DSPs (digital signal processors)
Early Superscalar
- Early attempt - Superscalar MIPS: Fetch 2 instructions, 1 FP and 1 anything else in-order
- Fetch 64-bits/clock cycle; Int on left, FP on right
- Can only issue 2nd instruction if 1st instruction issues
- If the inst mix wasn’t just right, then you issue one at a time
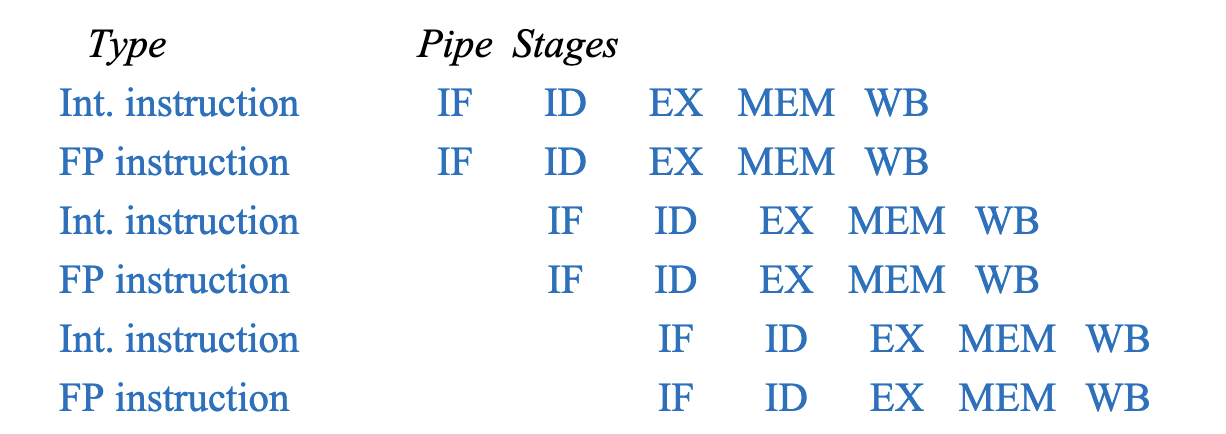 implications:
implications:
- More ports for FP registers to do FP load and FP op in a pair
- 1 cycle load delay expands to 3 instructions in SS
- instruction in right half can’t use it, nor instructions in next slot
- amplifying data hazards, check above can’t forward I0 mem until I4
- Branch hazard also expands to 3 instructions
Superscalar Flexibility
- Quickly frustrated with superscalar machines that limited what instruction could be scheduled together
- Thus, modern 4-wide superscalar → more flexibility
- OOO execution makes this much easier, because the instruction grouping (each cycle) is determined by the hw scheduler, not the fetch unit (compiler)
Dynamic Scheduling and Superscalar
- Dependencies stop instruction dispatch in In-order SS
- Code compiled for scalar pipeline will run poorly on SS
- may want code to vary depending on how superscalar (i.e., recompile for each target pipeline)
- Simple approach: combine dynamic scheduling (such as tomasulo) with the ability to fetch and issue multiple instructions simultaneously
Limits of Superscalar
- While integer/FP split is simple for HW, we only get CPI of 0.5 only for programs with:
- Exactly 50% FP operations
- No hazards
- If more instructions issue at same time, greater difficulty of decode and issue
- in modern superscalar processor, register renaming logic, forwarding logic is quadratic in issue width
- Register file is complex (4 issue requires 8 read ports and 4 write ports)
- Out-of-order instruction wakeup and scheduling also very complex
- These are the reasons superscalar essentially stopped at 4 a couple decades ago. but now up to 6ish to 8ish recently
Superscalar Key Points
- Only way to get CPI < 1 is multiple instruction issue
- SS requires duplicated hardware, more dependence checking
- Without duplication of functional units, will see limited improvement
- SS combined with dynamic scheduling can be powerful
Very Long Instruction Words (VLIW)
- fixed number of instructions issued each cycle
- parallelism scheduled by the compiler What is it?
- Very Long Instruction Word, attempt at a high performance ISA
- n-wide VLIW processor issues a packet of N instructions simultaneously
- compiler guarantees independence of those N instructions
- Try to fill 5 instruction format, lots of nops as a result, but requires compiler techniques to fill, like loop unrolling
 Need lots of registers because of loop unrolling, multiplying the number of registers needed per iterations and need to isolate them
Need lots of registers because of loop unrolling, multiplying the number of registers needed per iterations and need to isolate them
Traditional VLIW vs Intel IA64
- Traditional VLIW (multiflow, transmeta)
- Hard to fill large VLIW
- Lack of ILP
- Poor match of instruction stream vs VLIW slots.
- Lots of NOPs
- Hard to fill large VLIW
- Intel IA64 (Itanium)
- More flexible groupings of instructions
- Only 3-wide (but multiple-issue)
- so up to 6 ops per cycle for initial Itanium
- Can collapse multiple groups into 1 3-op (not parallel) instruction, so fewer NOPs
Superscalar vs VLIW
- Superscalar Positive
- Less stress on compilers
- VLIW Positives
Pipeline case study
- Intel pentium 4
- (at one point) apex of ooo processors, subsequent processors back…
- …