source: https://cseweb.ucsd.edu//~tullsen/isca96.pdf
Abstract
Simultaneous multithreading (SMT) is a technique that permits multiple independent threads to issue multiple instructions each cycle.
The paper presents throughput gains from SMT without extensive changes to a conventional wide-issue superscalar, in hardware structures or sizes.
Goals:
- Minimizes architectural impact on conventional superscalar design
- Minimal performance impact on a single thread executing along
- Achieves significant throughput gains when running multiple threads
Introduction
Extends SMT’s prior work:
- Throughput gains of SMT are possible without extensive changes to conventional wide-issue superscalar processor
- SMT does not compromise single-thread performance
- Use detailed architectural model to analyze and relieve bottlenecks that did not exist in the more idealized model
- SMT creates an advantage that didn’t exist in prior architectures: namely the ability to choose the “best” instructions, from all threads for both fetch and issue each cycle
- By favoring the threads most efficiently using the processor, boost throughput
SMT Architecture
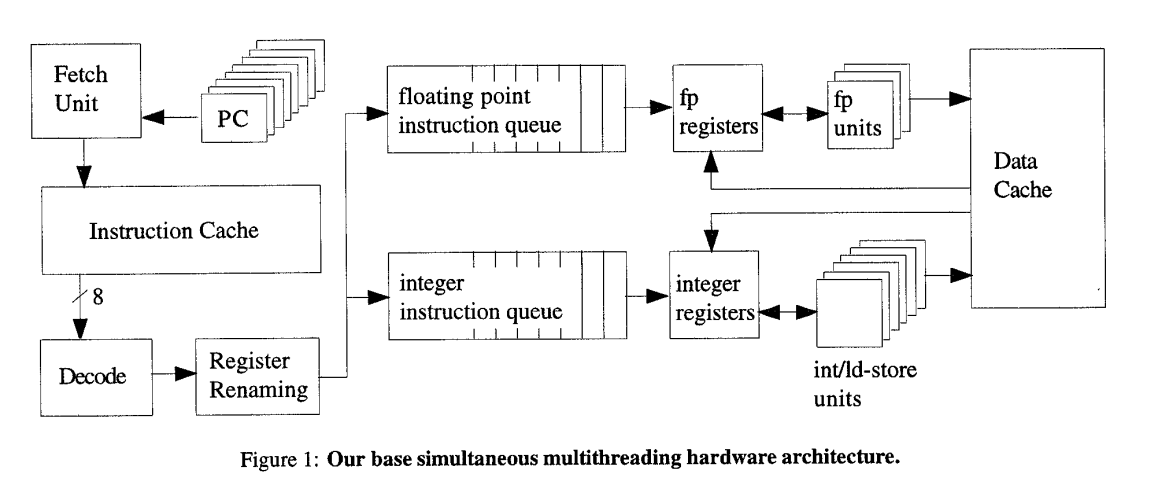 SMT architecture is derived from a high-performance, out-of-order, superscalar architecture
SMT architecture is derived from a high-performance, out-of-order, superscalar architecture
Changes from superscalar
- Multiple program counters and some mechanism by which the fetch unit selects one each cycle
- A separate return stack for each thread for predicting subroutine return destinations
- Per-thread instruction retirement, instruction queue flush, and trap mechanisms
- A thread id with each branch target buffer entry to avoid predicting phantom branches
- A larger register file to support logical registers for all threads and additional registers for register renaming
- With a large register file and to prevent it from being slow due to its size, take two cycles to read registers
- First cycle to read values and instruction into a buffers closer to functional units
- Second cycle the data is sent to functional unit for execution
- With a large register file and to prevent it from being slow due to its size, take two cycles to read registers
Note: Simultaneous multithreading scheduling of instructions is already supported. With a conventional instruction queue, dependencies between instructions are removed by the register renaming phase.
- IQ is shared by all threads
Two-stage register access
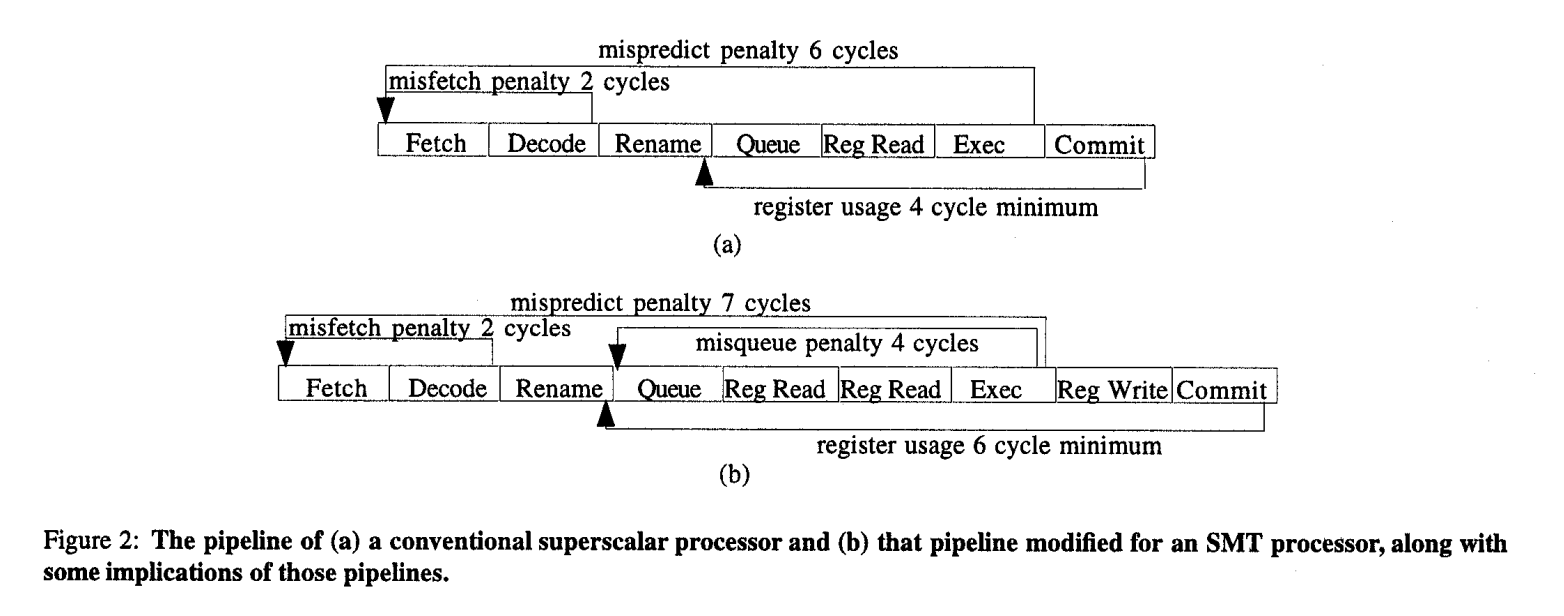
- 2 stage reg access causes several issues:
- Increase pipeline distance between fetch and exec, increasing branch misprediction penalty by 1 cycle
- Takes an extra cycle to write back results
- Increased distance between queue and exec increases the period during which wrong-path instructions remain in the pipeline after a misprediction is discovered
- Two more stages between rename and commit which increases the minimum time that a physical register is held by an in-flight instruction
Summary
- Instruction scheduling is no more complex than on a dynamically scheduled superscalar
- Uses instruction queue, isn’t there now contention?
- Register file data paths are no more complex than in the superscalar, and performance implication of the register file and its extended pipeline are small
- What is a register file data path?
- The required instruction fetch throughput is attainable, even without any increase in fetch bandwidth
- What is the required instruction fetch throughput?
- Unmodified (for an SMT workload) cache and branch prediction instructions do not thrash on that workload
- Even aggressive superscalar technologies, such as dynamic scheduling and speculative execution, are not sufficient to take full advantage of a wide-issue processor without simultaneous multithreading