Sources:
- METIS: Fast Quality-Aware RAG Systems with Configuration Adaptation
- A Comprehensive Survey on Vector Database: Storage and Retrieval Technique, Challenge
- Seven Failure Points When Engineering a Retrieval Augmented Generation System
- HedraRAG: Coordinating LLM Generation and Database Retrieval in Heterogeneous RAG Serving
METIS
Background
- RAG allows LLMs to generate better responses with external knowledge, but external knowledge causes higher response delay
- No systematical way to balance the tradeoff between both quality and response delay
- METIS tackles above by jointly schedules queries and adapts the key RAG configurations of each query
- RAG query steps:
- Retrieval - RAG sys retrieves one or more relevant context chunks
- Synthesis - combines these chunks and the RAG query to form a single/multiple LLM calls to generate the response
Goals
- Optimize queries based on resources while maintaining high quality
How
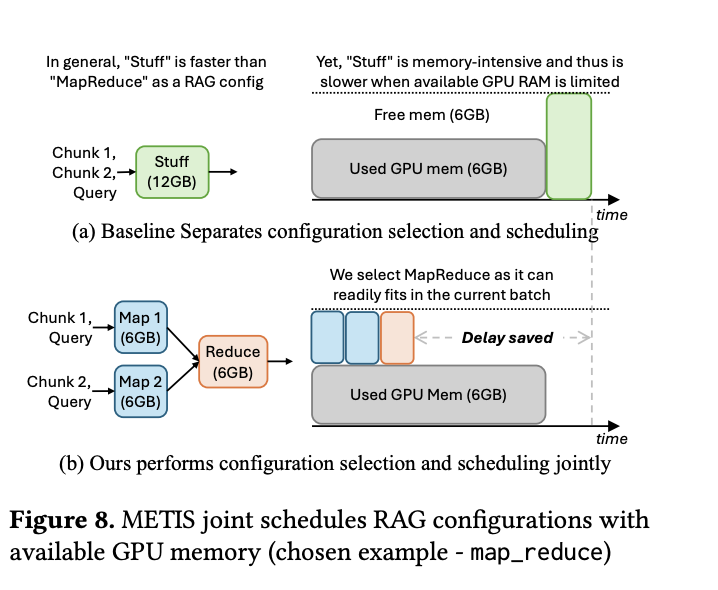
- METIS reduces the RAG response delays by jointly deciding the per-query configuration and query scheduling based on available resources
- Two-level design
- Pruning configuration space:
- pruning configuration space into smaller configurations that focus on keeping accuracy high
- RAG Scheduler
- jointly optimizing configuration and scheduling to optimize response delay by choosing configuration which best-fit into GPU memory
- Pruning configuration space:
- Basically estimate query’s performance, reduce configuration space. Then scheduler chooses best configuration to send to execution engine
- Metric considerations:
- resource cost (GPU requirement)
- latency
- memory consumption (KV Cache size)
RAG System and Configuration
- Abstract model for adjusting RAG context
- their configuration knobs:
Num_chunks- how many chunks to receivesynthesis_method- how to synthesizeintermediate_length- how long is each summary
- Performance Metrics eval
- Response quality - calculates the F1 score of the generated response against the ground truth
- F1 score is the harmonic mean of percision
- precision (# of correctly generated words)
- recall (# of correct words successfully generated against ground truth)
- Intuition:
- F1 = 1 (perfect precision and recall)
- F1 = 0 (completely wrong)
- F1 score is the harmonic mean of percision
- Response delay - measure time elapsed from when the RAG system receives a RAG request to when it completes generating the response
- Response quality - calculates the F1 score of the generated response against the ground truth
Pruning configuration space
- Estimating query profile:
- query complexity - intricacy of the query, like “why?” questions relative to “yes/no” questions
- in paper, dimension output is binary (High/low)
- joint reasoning requirement - whether multiple pieces of information are needed to answer the query
- in paper, dimension output is binary (Yes/No)
- Pieces of information required - distinct, standalone pieces of information required to fully answer the query
- in paper, dimension output is a number (1-10)
- Length of the summarization - if query is complex and needs a lot of different information, it is often necessary to first summarize the relevant information chunks first
- in paper, dimension output is a number (30-200)
- query complexity - intricacy of the query, like “why?” questions relative to “yes/no” questions
METIS SYS DESIGN
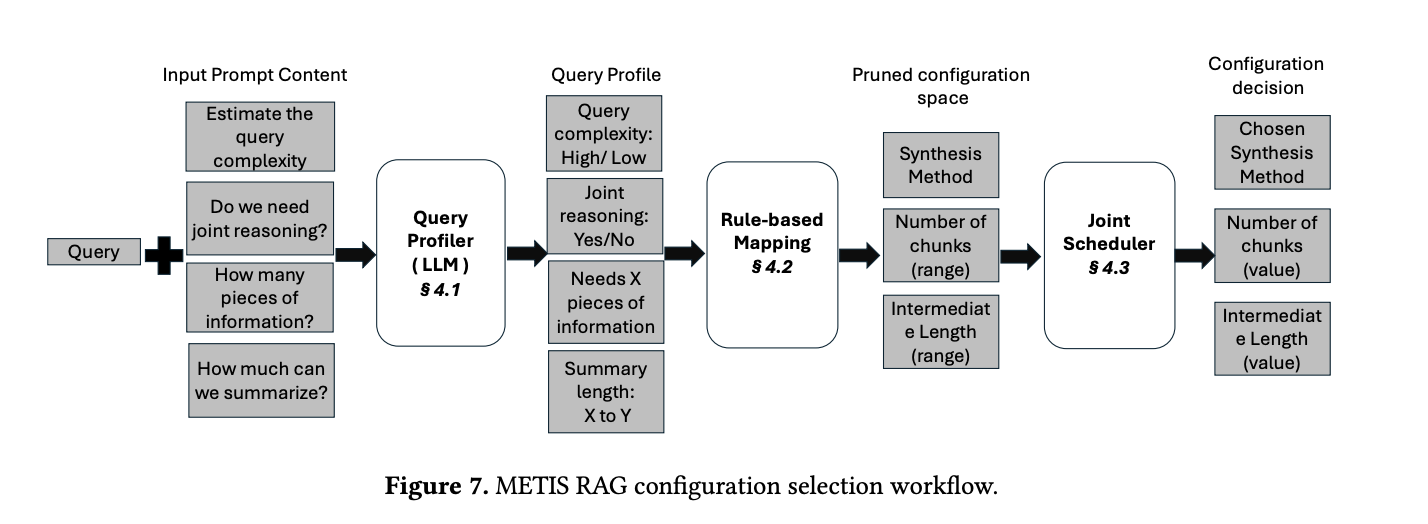
Rule-based mapping

Joint Configuration-Scheduling
A Comprehensive Survey on Vector Database: Storage and Retrieval Technique, Challenge
Abstract
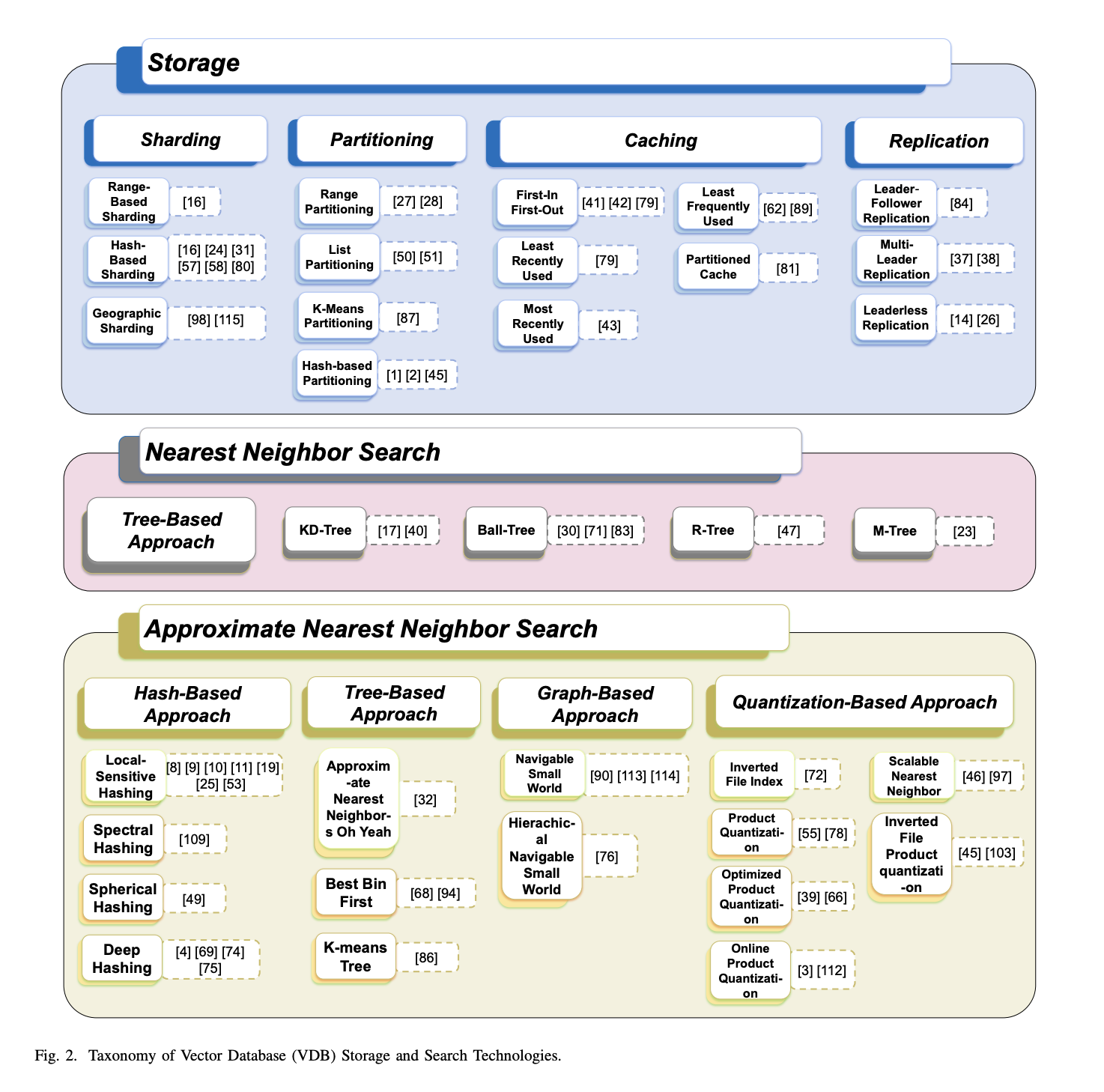
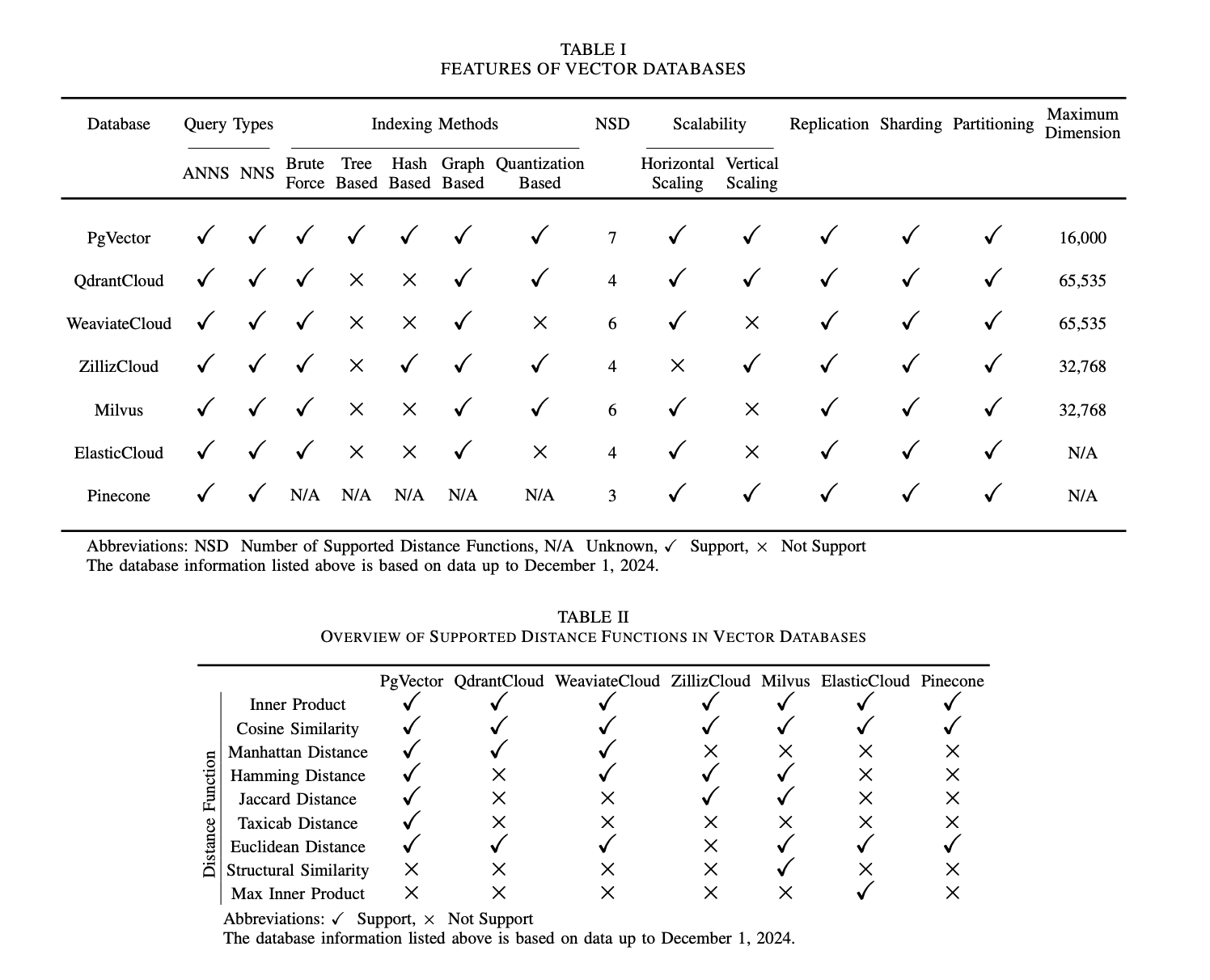
- Review of relevant algos:
- review of storage and retrieval technologies
- comparison of several advanced VDB solutions
- outline emerging opportunities for coupling VDBs with LLMs
Background on Vector DB
- Stores data in vectors
- All searches are fuzzy, similarity based on algo form query to db embeddings
- Vector Databases (VDBs) are tools designed to efficient store and manage high-dimensional vectors
- Two core functions:
- vector storage
- quantization
- compression
- distributed storage mechanisms
- vector retrieval
- indexing techniques (Tree-based, hashing, graph-based, quantization-based techniques)
- vector storage
- Two core functions:
- Compared to traditional database, VDBs have three significant advantages
- VDBs possess efficient and accurate vector retrieval capabilities
- Vector databases support the storage and query of complex and unstructured data
- Vector databases have high scalability and real-time processing capabilities
High level overview
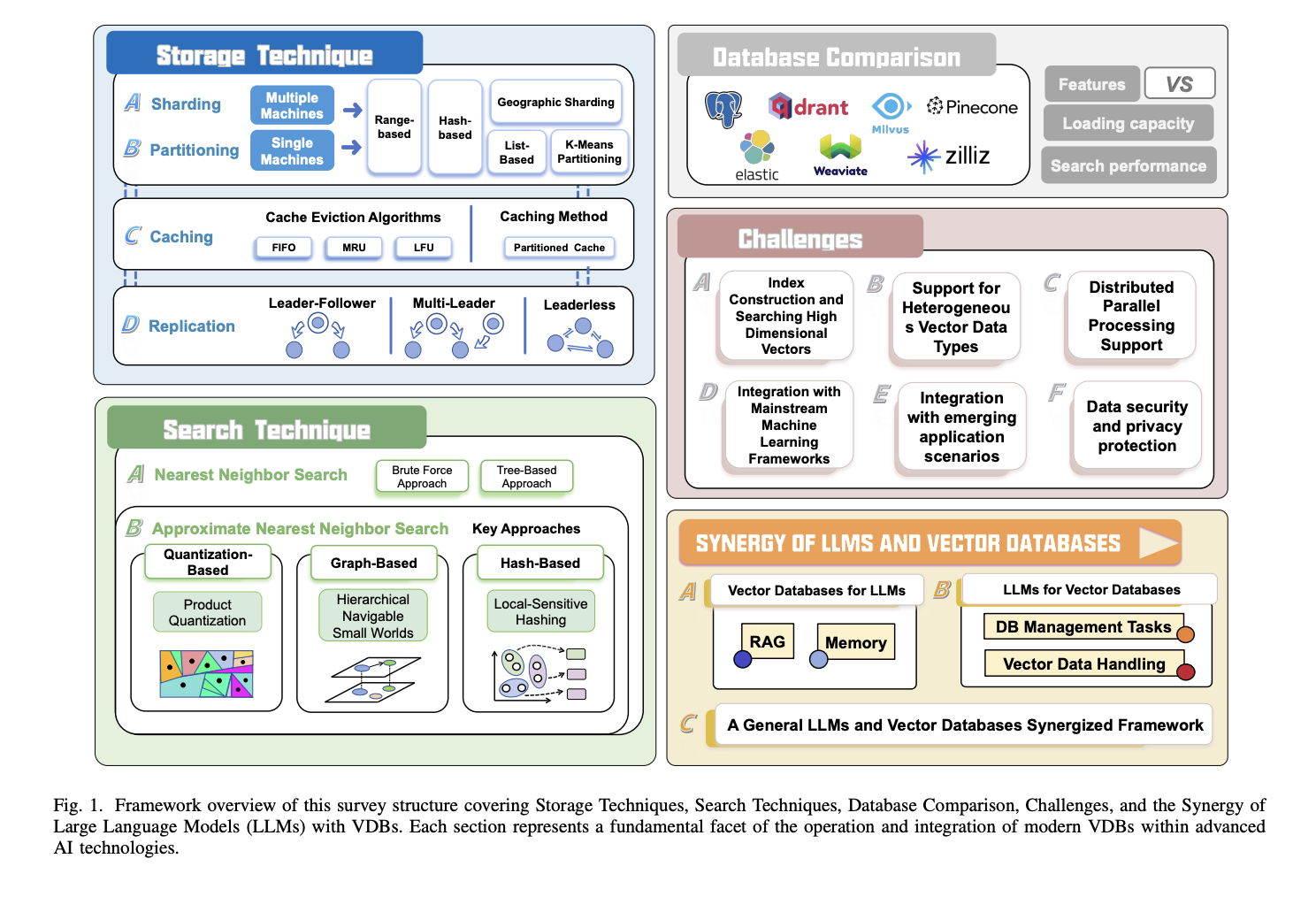 Algorithms for each component
Algorithms for each component