source: Orca: A Distributed Serving System for Transformer-Based Generative Models (OSDI’22)
Summary
This paper introduces Orca, a distributed serving system for transformer based generative models. Orca contains two key new features: iteration-level scheduling and selective batching. Previous systems had request-level scheduling which meant that whole batches needed to be ran through execution engine before the inference receives a response. With iteration-level scheduling, after each iteration a response is passed back. Selective batching helps keep batches as filled as possible by batching operations that can handle mismatched tensors and split up the batch during the attention op, allowing for more flexibility in batch selection.
Questions: **
-
List one benefit and one drawback of iterative scheduling (as compared to request-level scheduling). Iterative scheduling helps mitigate longer queries in a batch from blocking shorter ones communicating with the inference server after every iteration. This is in relation to request-level scheduling which communicates to the inference server only after the batch is complete. The drawback of iterative scheduling is the overhead of additional communications. If the sent queries were closer to the same size then the benefit would be more negligible.
-
How would you decide the batch size (number of request) for an LLM inference system you are building? List all the factors you would consider.
Background
Inference
- Multi-iteration characteristic
- generate one token at a time
- Initiation phase (1st iteration)
- process all input tokens at once
- Increment phase (2nd-last iterations)
- process a single token generated from the previous iteration
- use attention keys and values of all previous tokens
- Save attention keys and values for following iterations to avoid recomputation
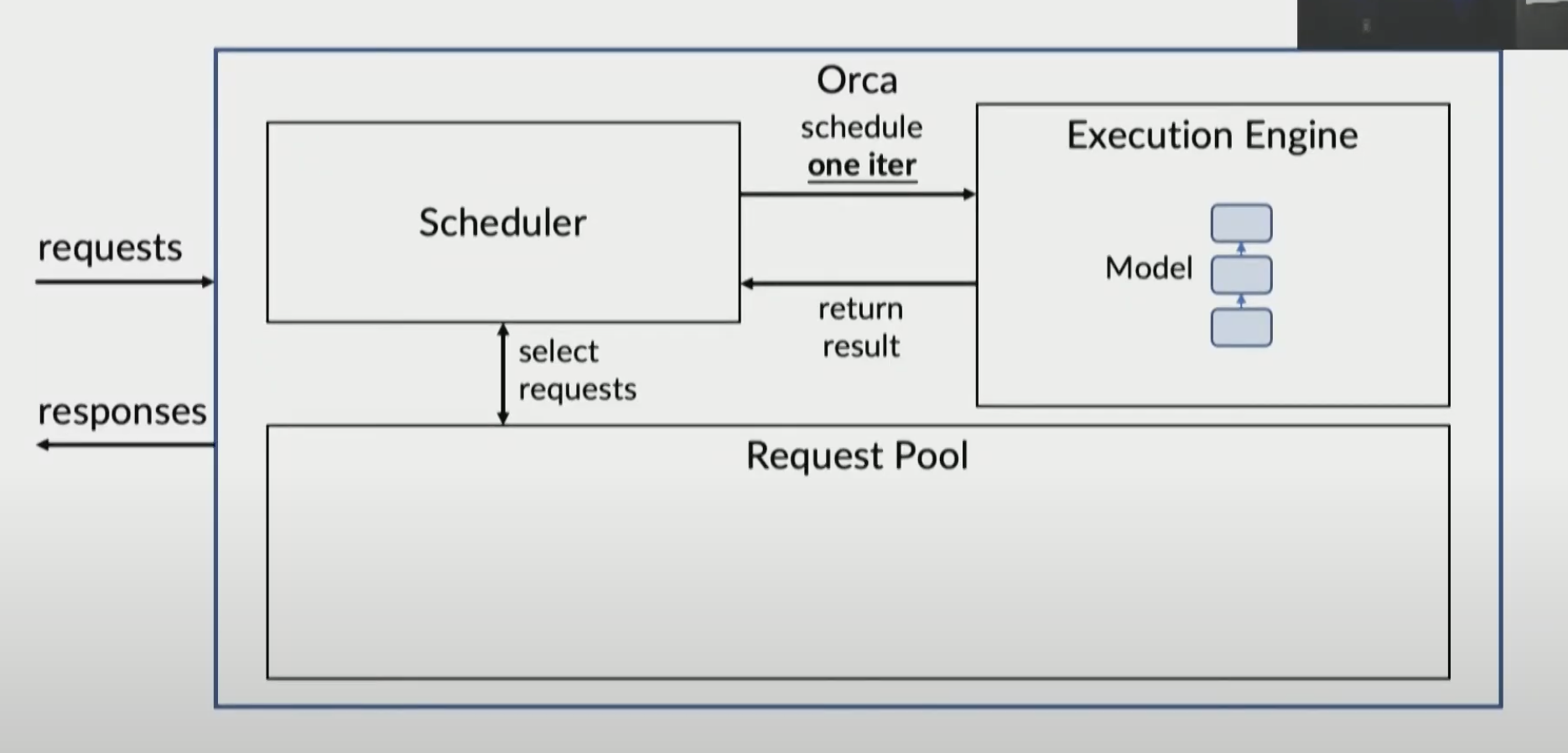
System Components for Inference
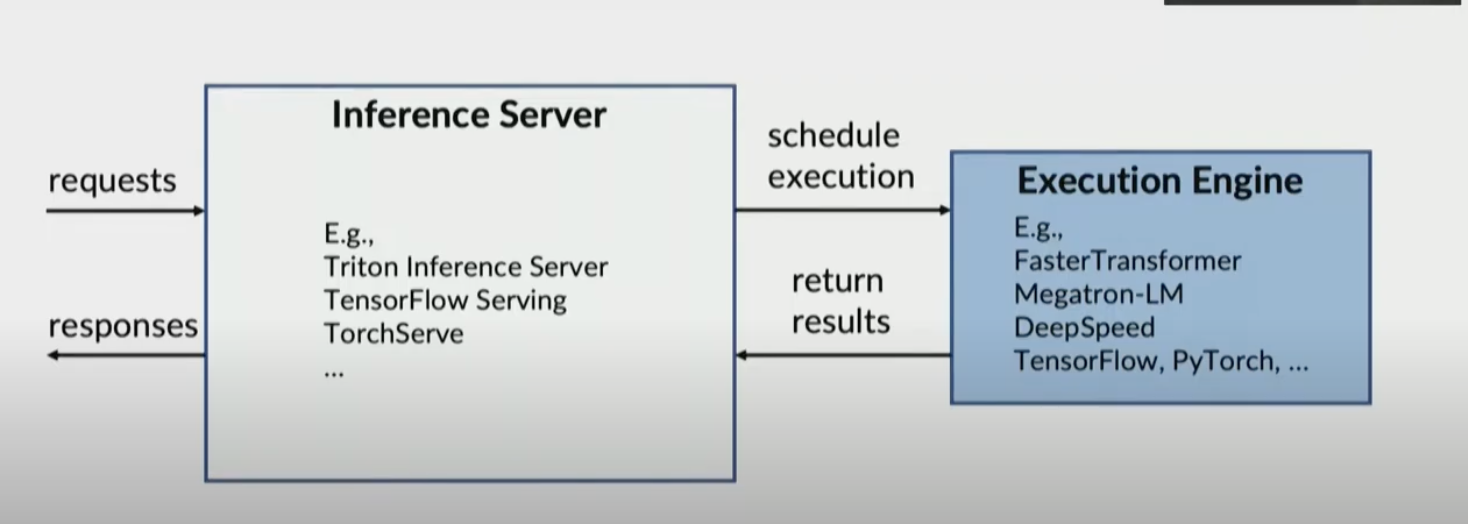 Inference server schedules request
Inference server schedules request
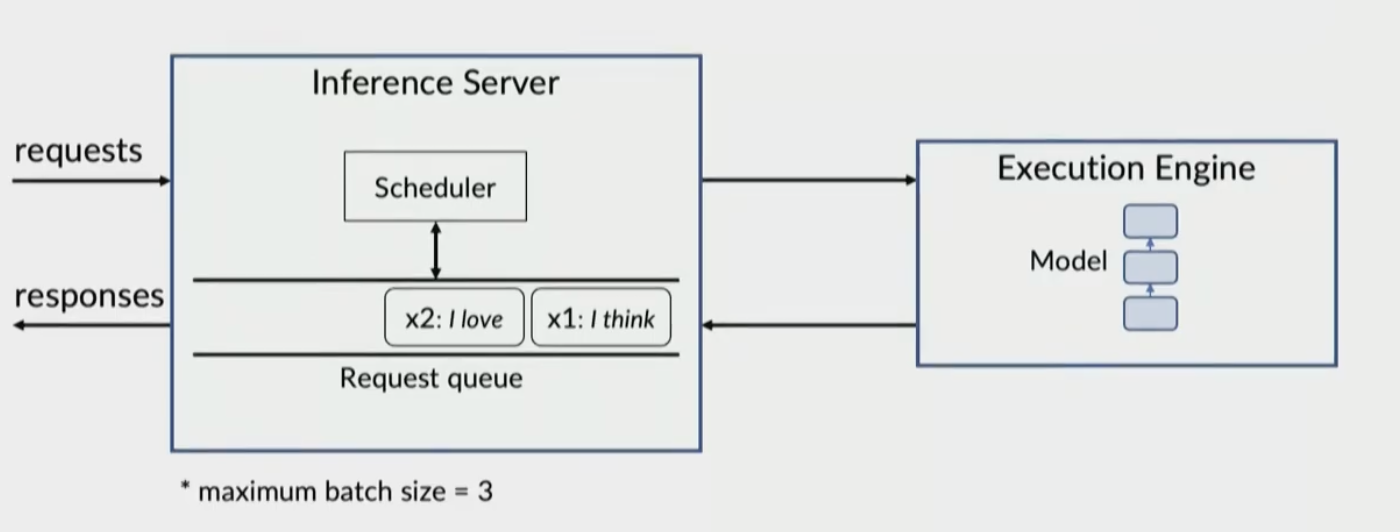 Request is passed to execution engine
Request is passed to execution engine
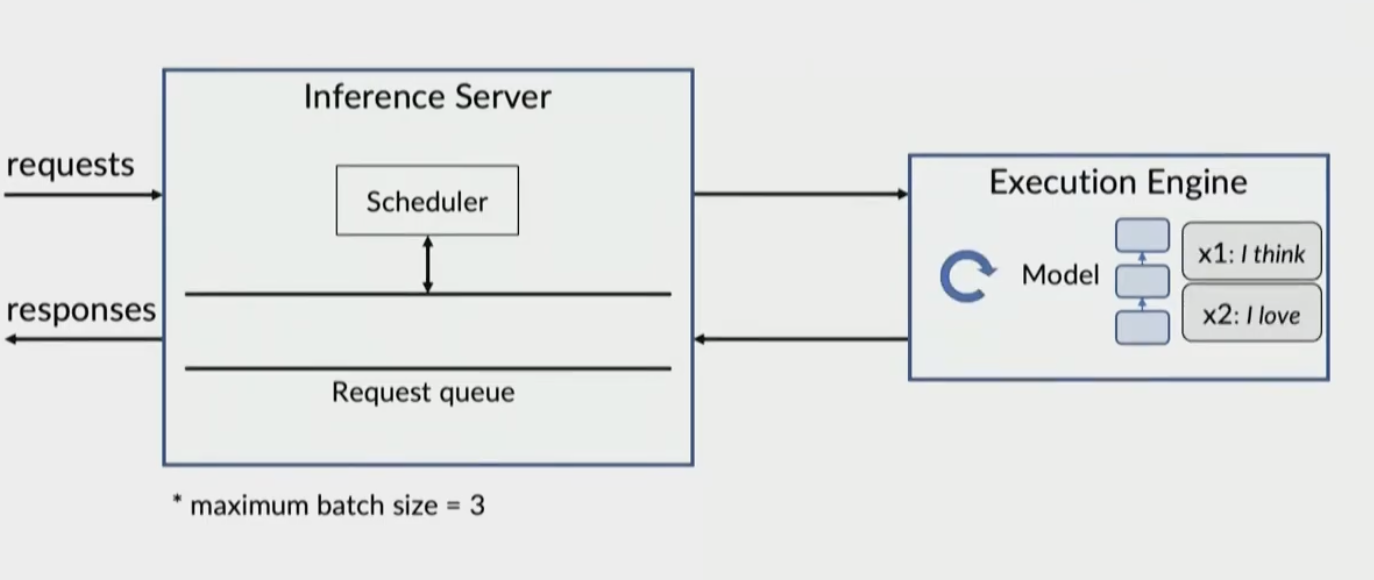 Engine output is passed to server
Engine output is passed to server
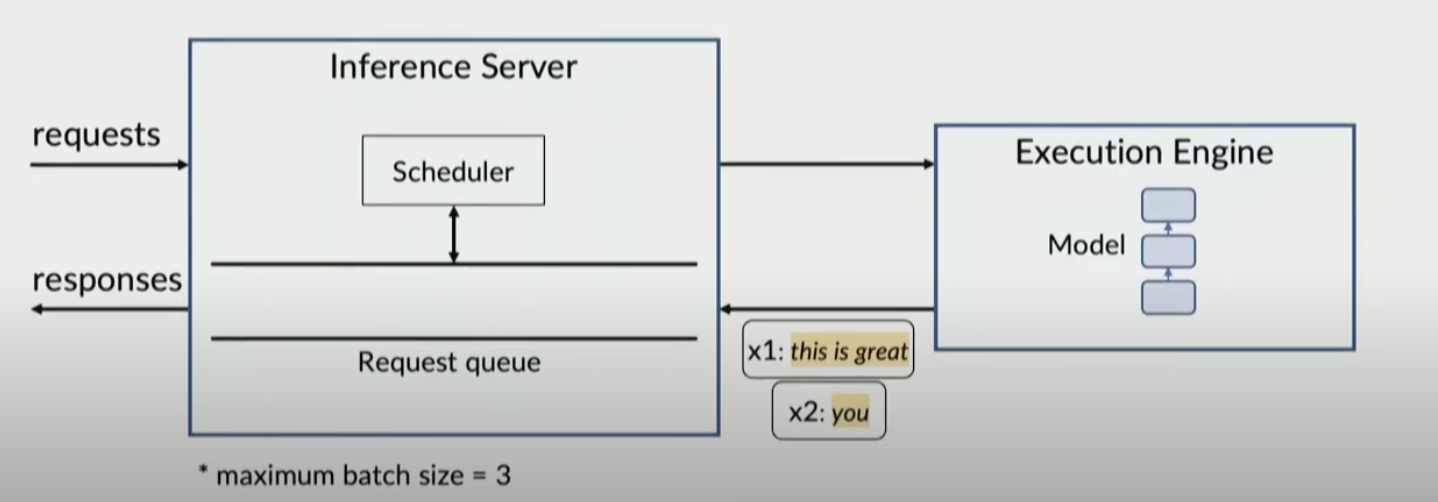
Problems 1: Request-level scheduling
Execution Engine only sends response to inference server when batch is completed
x2 is stalled until batch is done, waiting on x1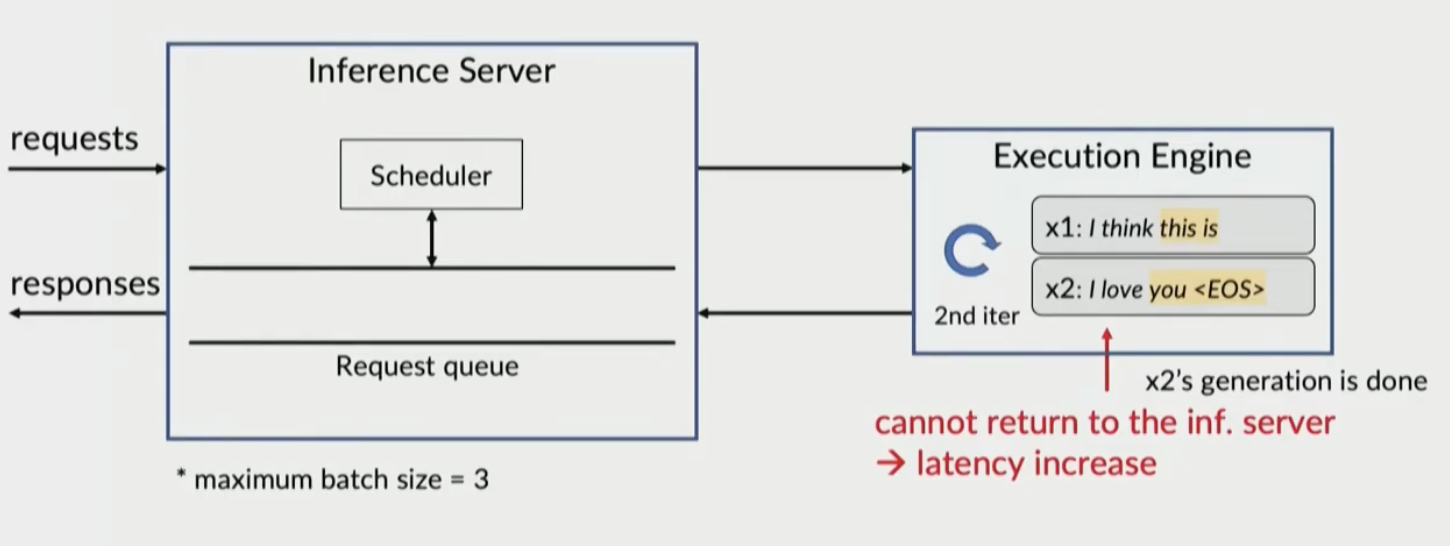 x3 is blocked until batch is done
x3 is blocked until batch is done
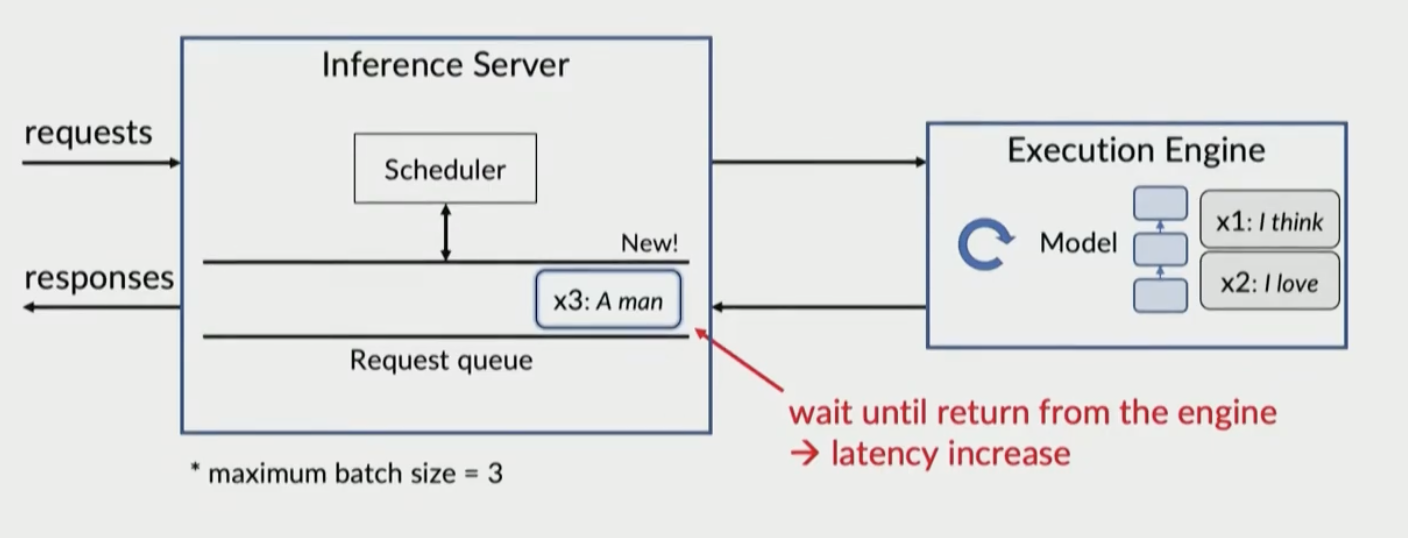 Problem inference server and execution engine only interact once a batch is done
Problem inference server and execution engine only interact once a batch is done
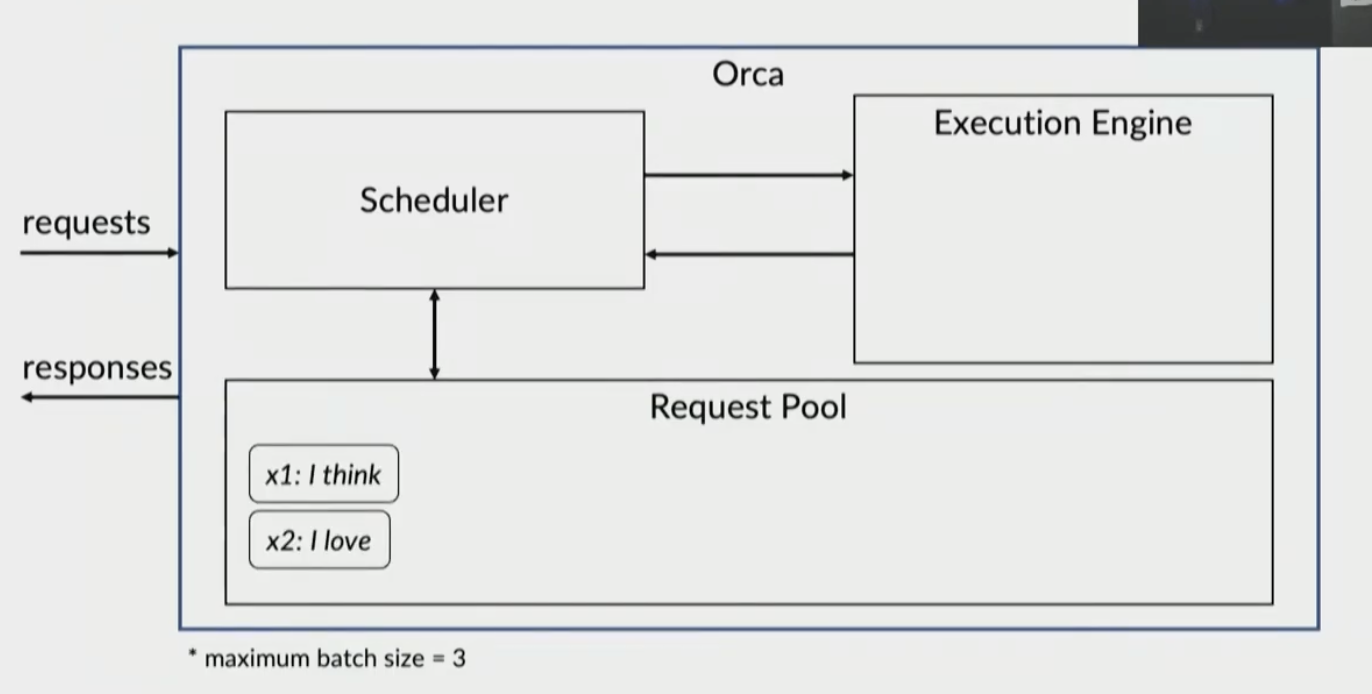
Their solution is iteration-level scheduling
x1 and x2 queued in pool
 new request x3
new request x3
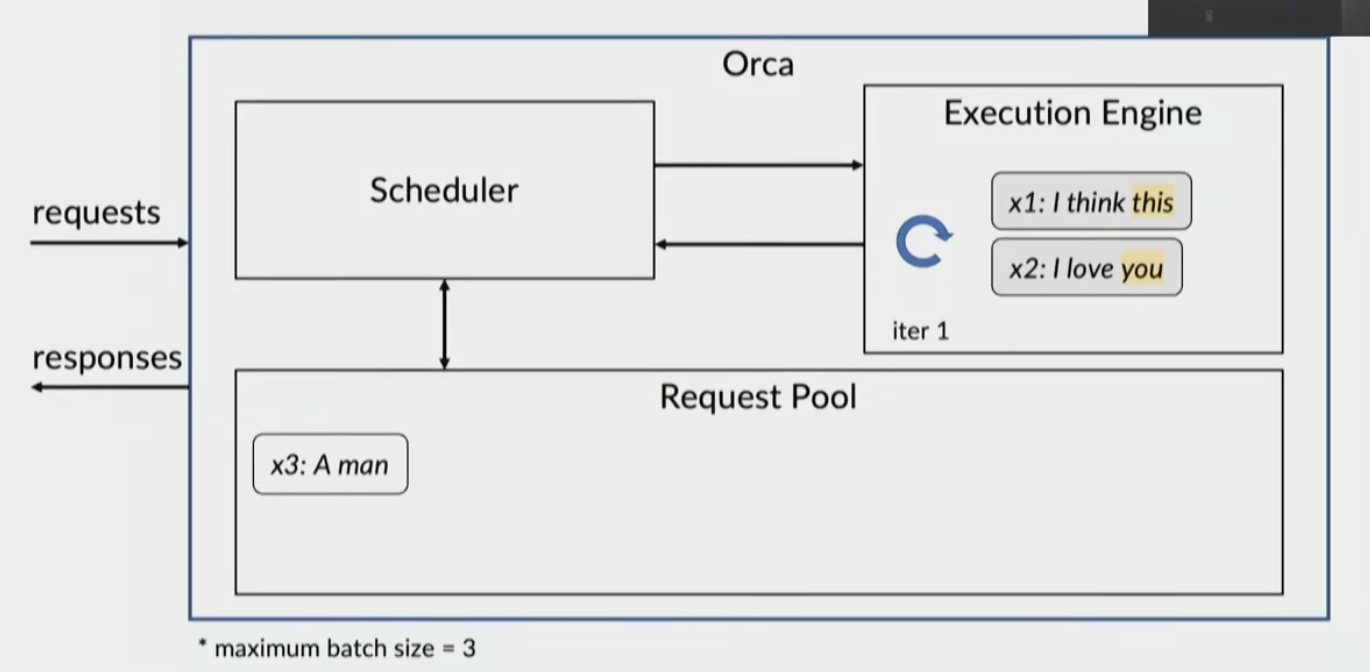 x1 and x2 return to pool and x3 is added
x1 and x2 return to pool and x3 is added
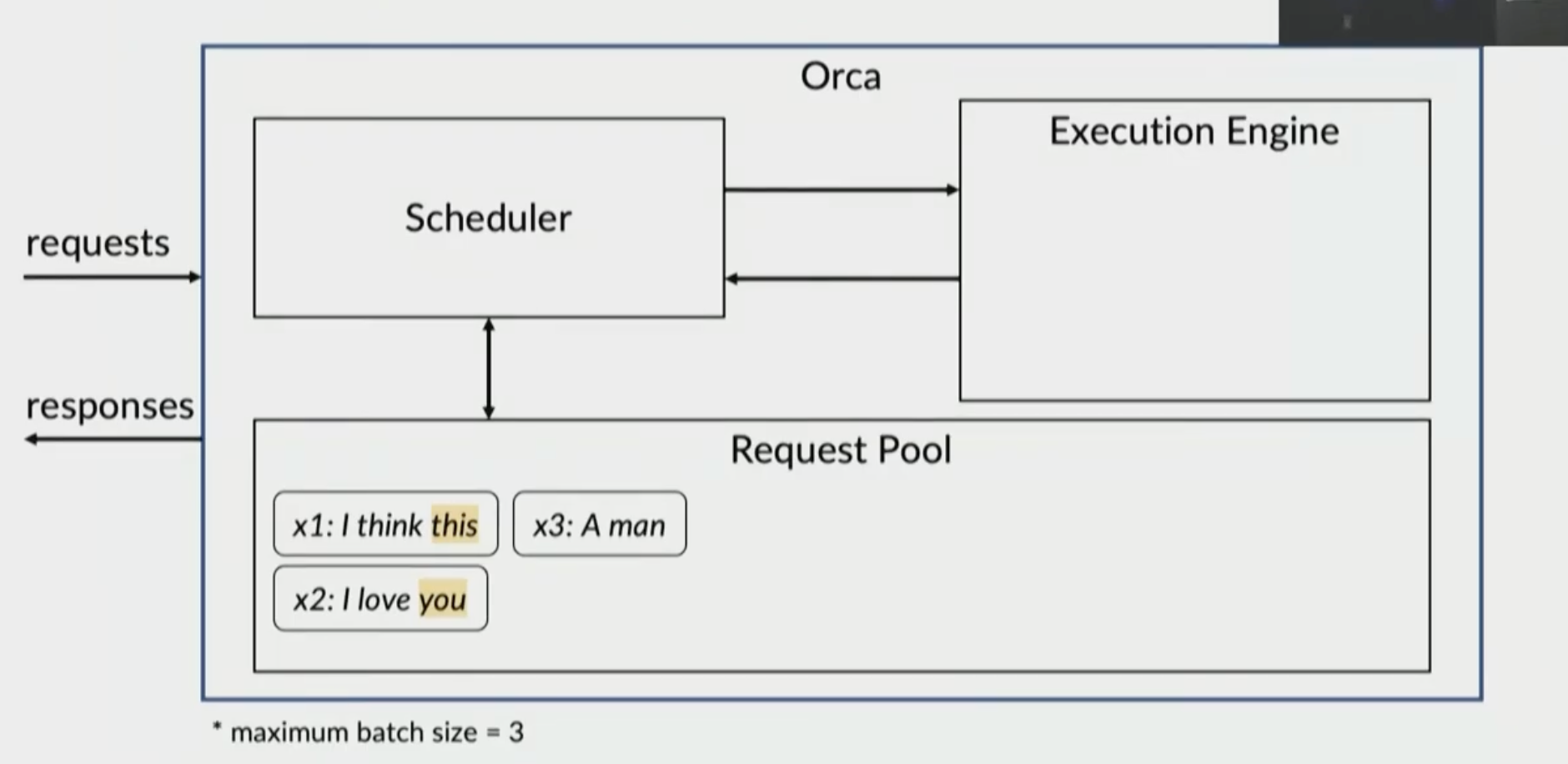 x1, x2, x3 are all sent to execution engine
x1, x2, x3 are all sent to execution engine
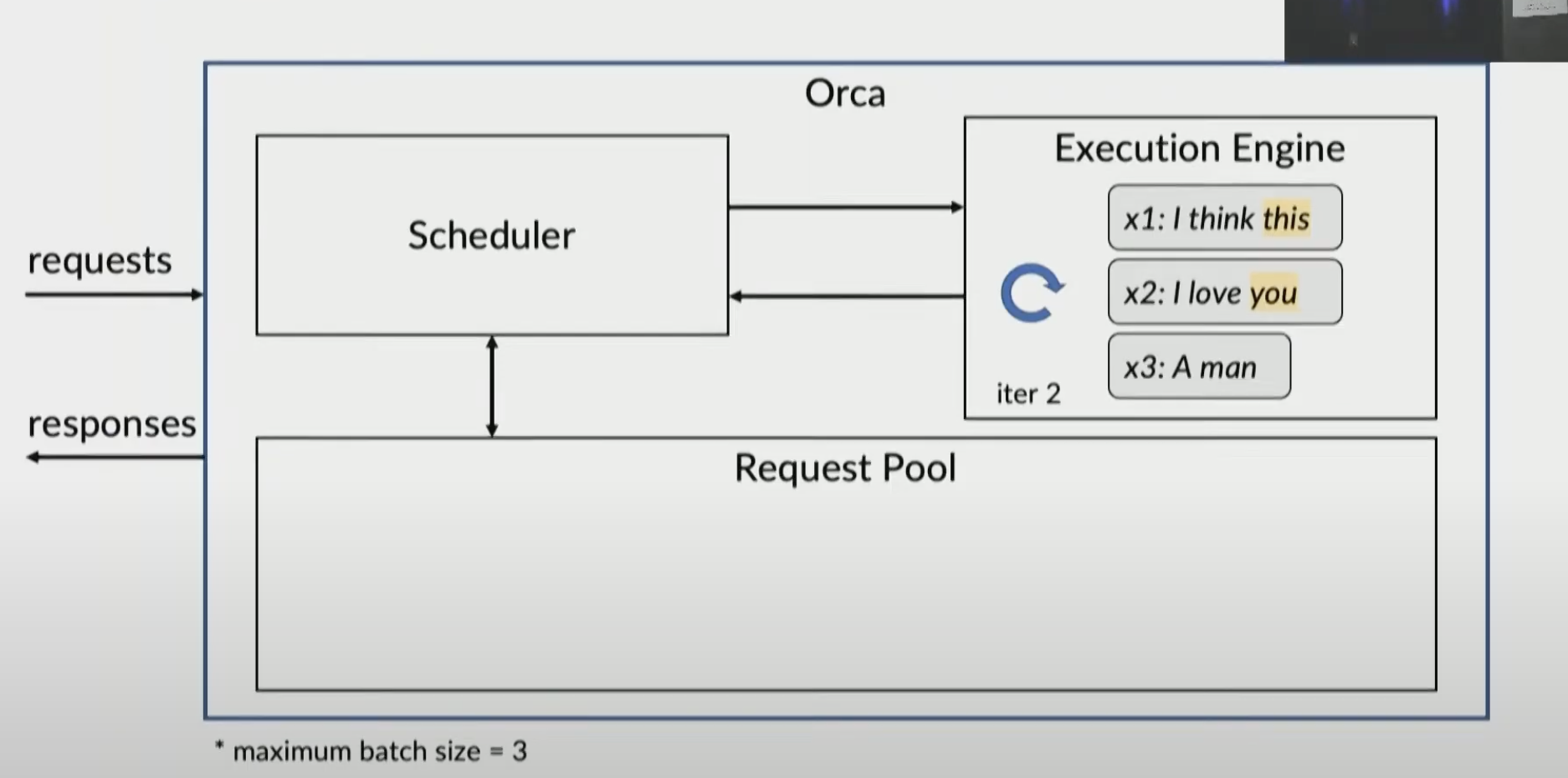 suppose new request x4, x5
suppose new request x4, x5
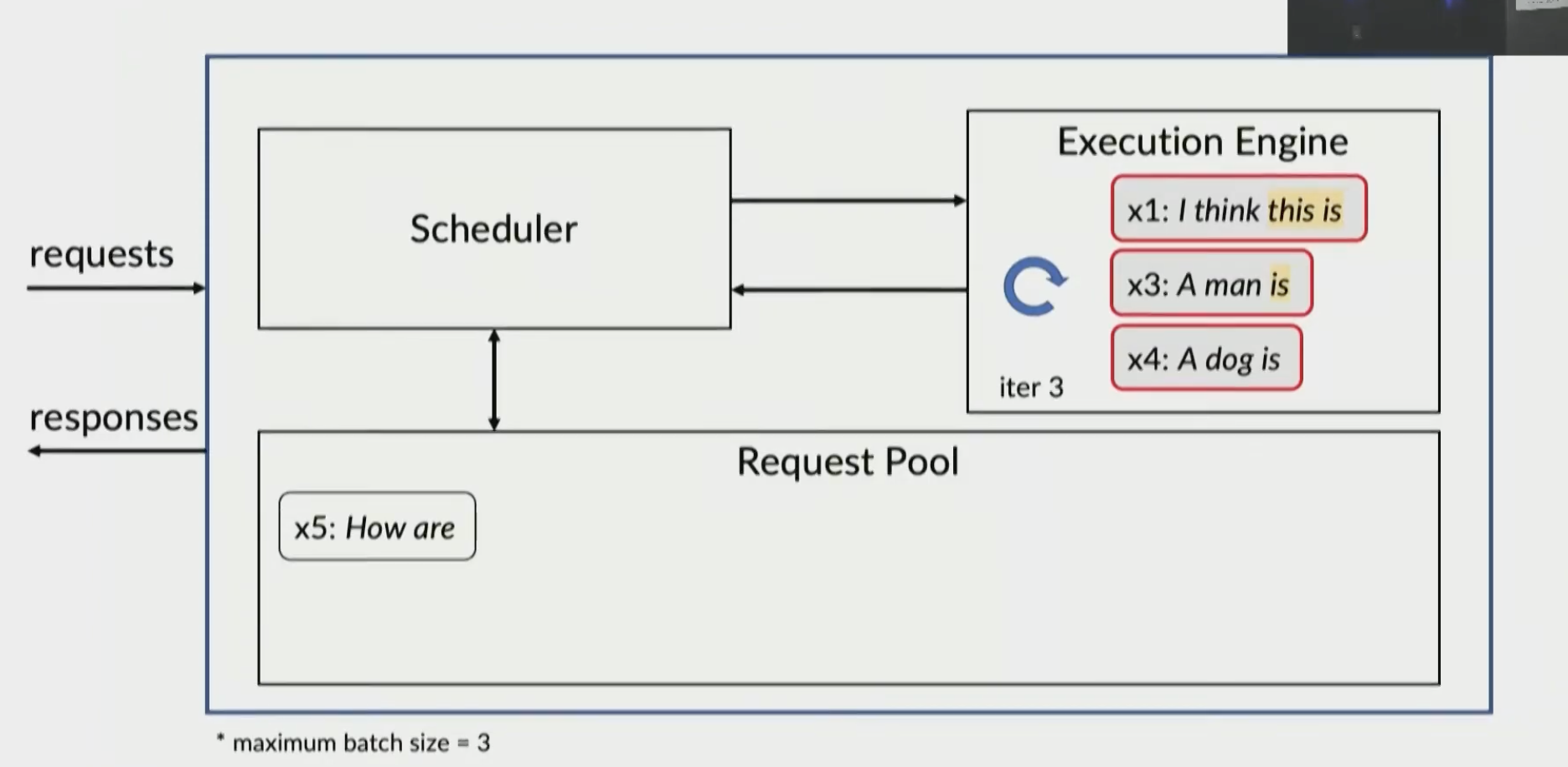
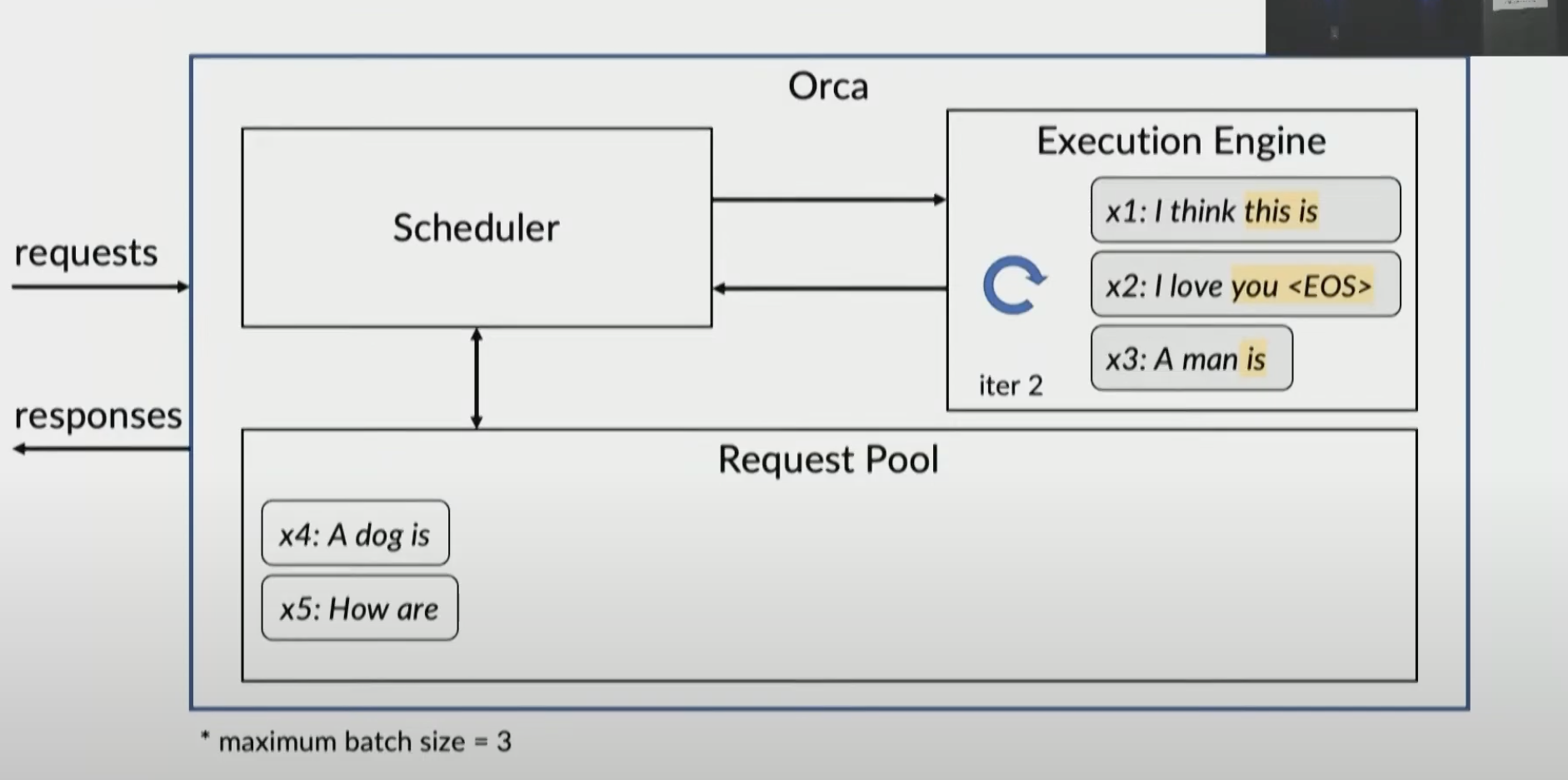 x2 is done and sent to client
x2 is done and sent to client
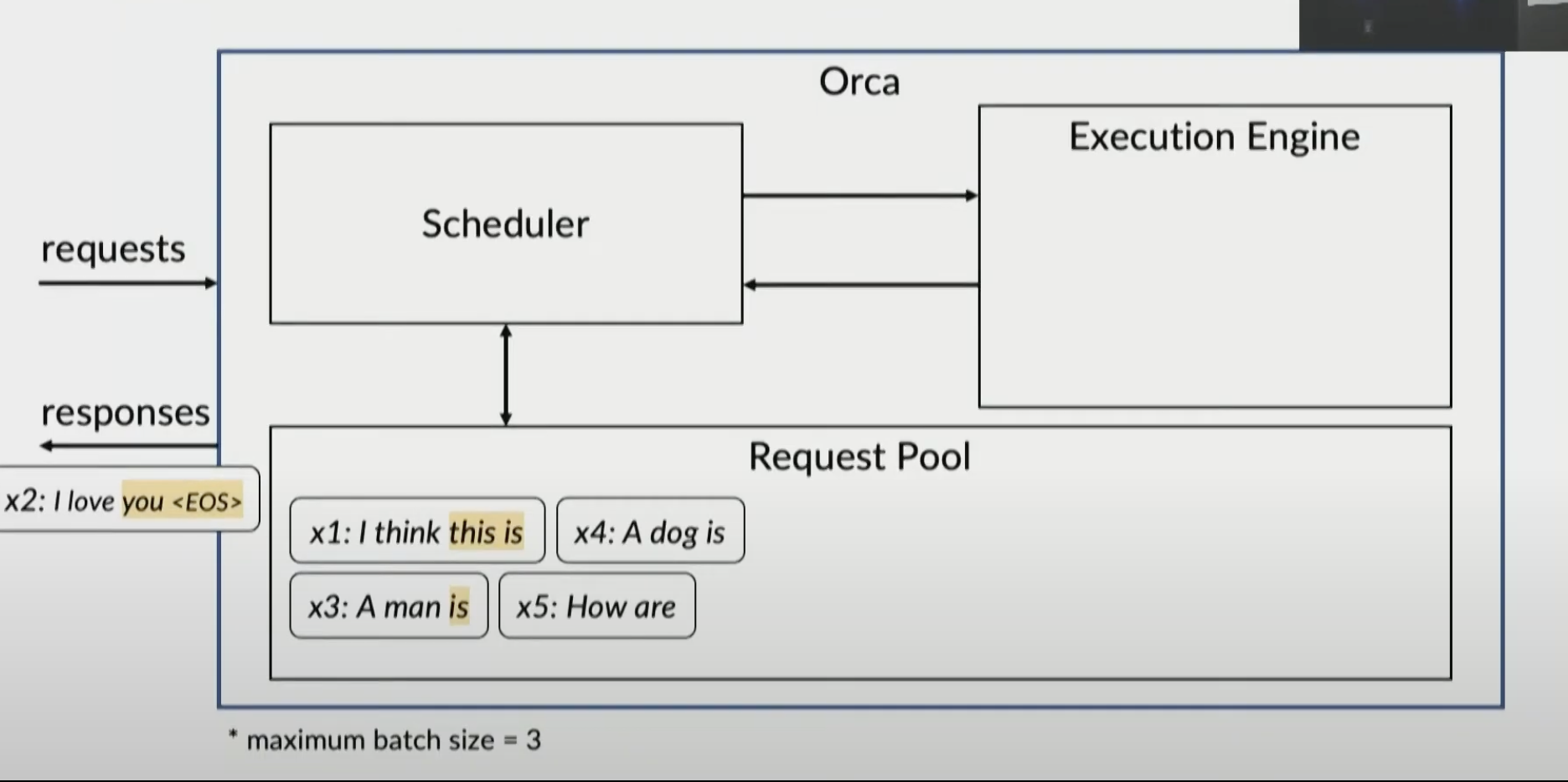 now process x4
now process x4
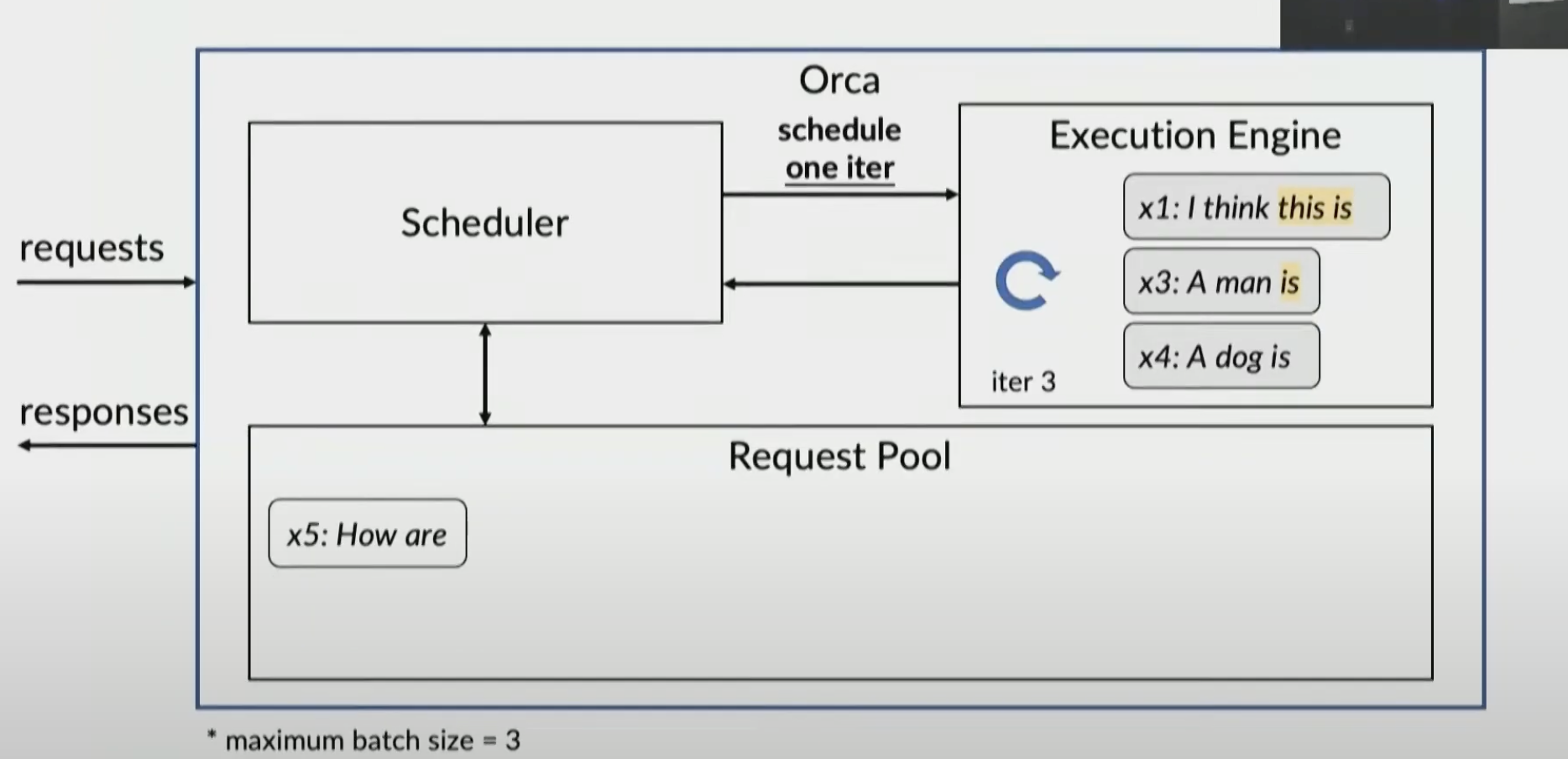
With iteration-level scheduling, we can handle early-finished or late-arrived requests much more efficiently.
- Parallels to multi-cycle processors in comp arch where instructions are broken down into stages to lower cycle time (here it’s by iterations to lower batch latency)
Problem 2: Batching
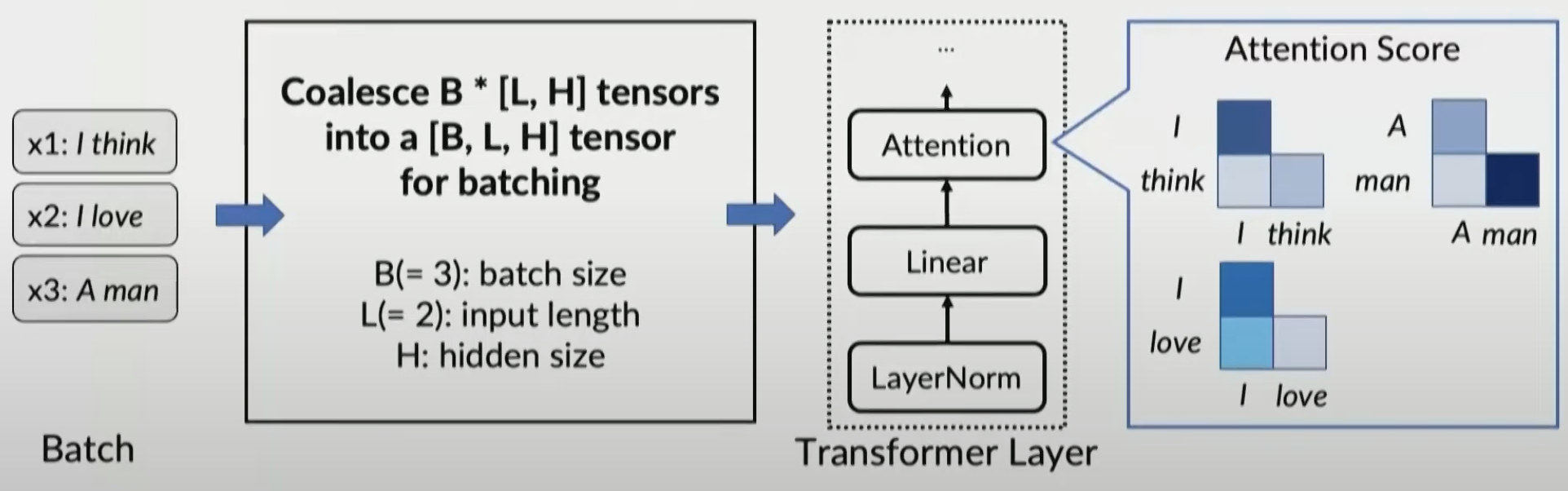
Batching is only applicable when
- requests are in the same phase (they are all in the initiation phase or all in the increment phase)
- requests have the same length
Different phases
 CANNOT COALESCE TENSORS OF DIFFERENT SHAPES
CANNOT COALESCE TENSORS OF DIFFERENT SHAPES
Different lengths
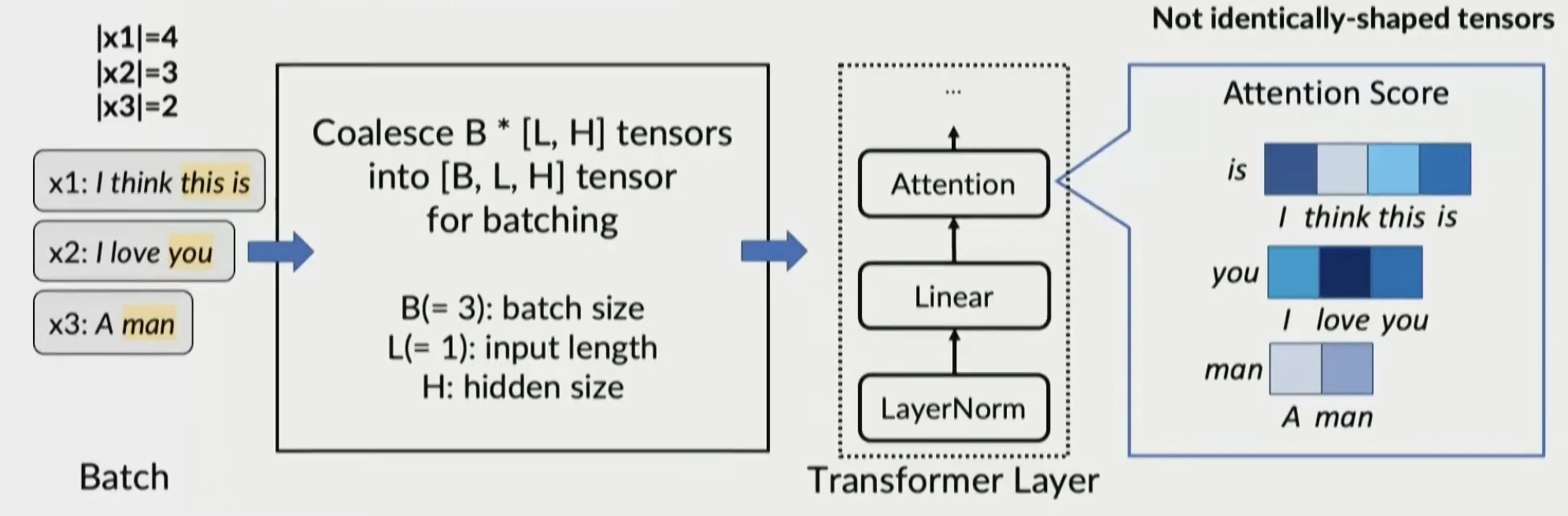 Attention op doesn’t have identically-shaped tensors, no batching
Attention op doesn’t have identically-shaped tensors, no batching
Solution: Selective batching
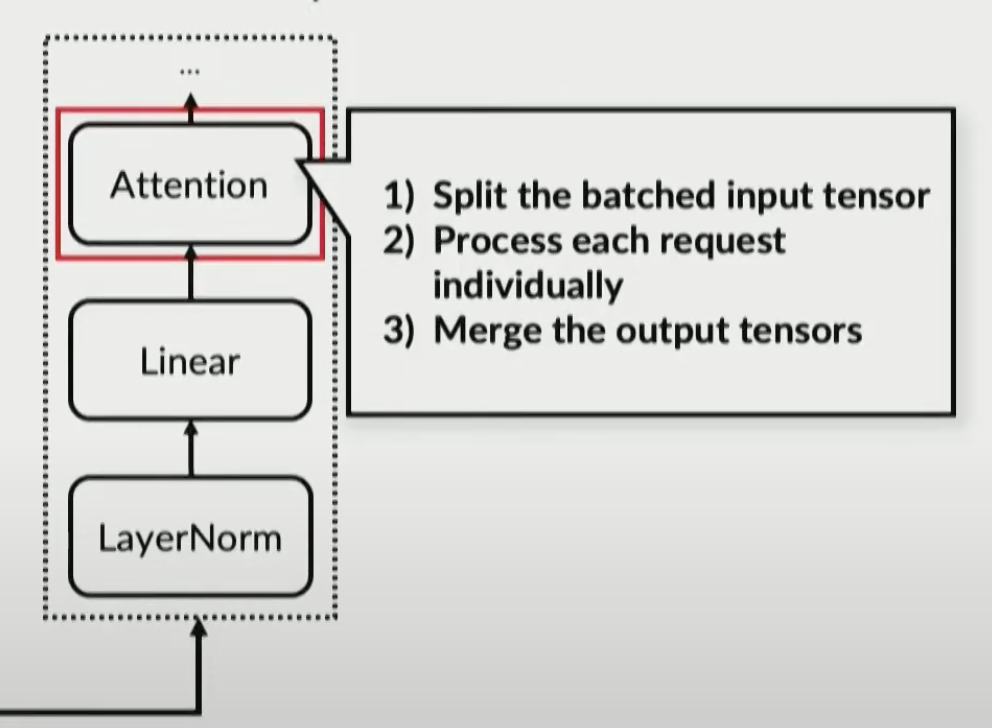
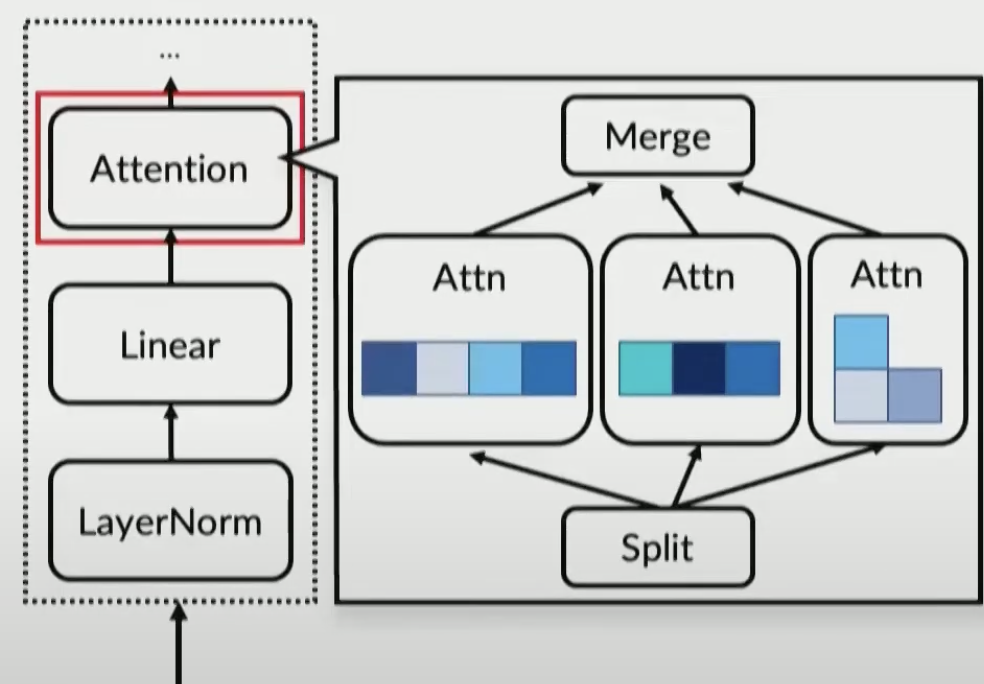
Orca
Distributing serving system
Architecture
Execution Engine
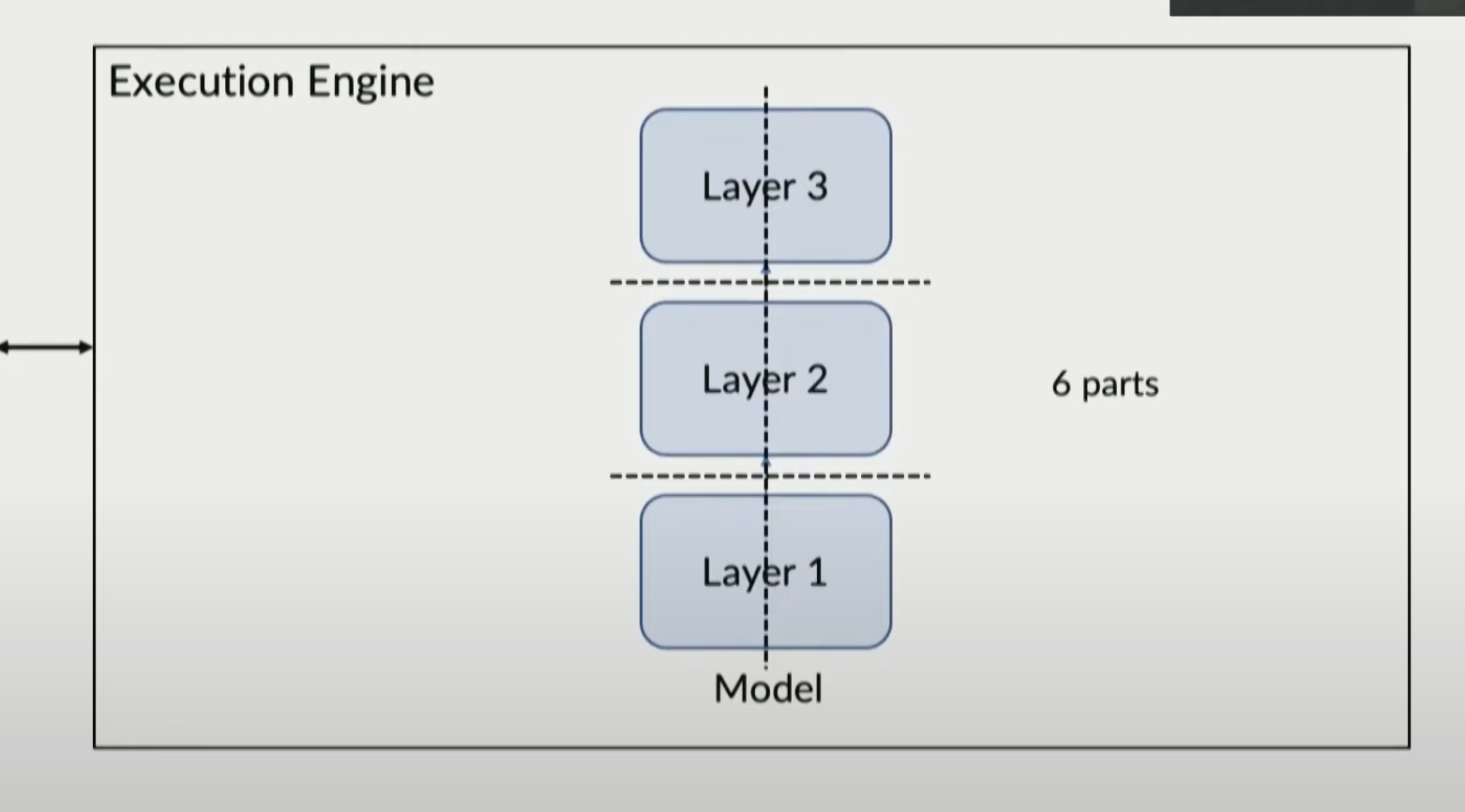 Can horizontally or vertically partition and distribute across gpus
Example partitioned system:
Can horizontally or vertically partition and distribute across gpus
Example partitioned system: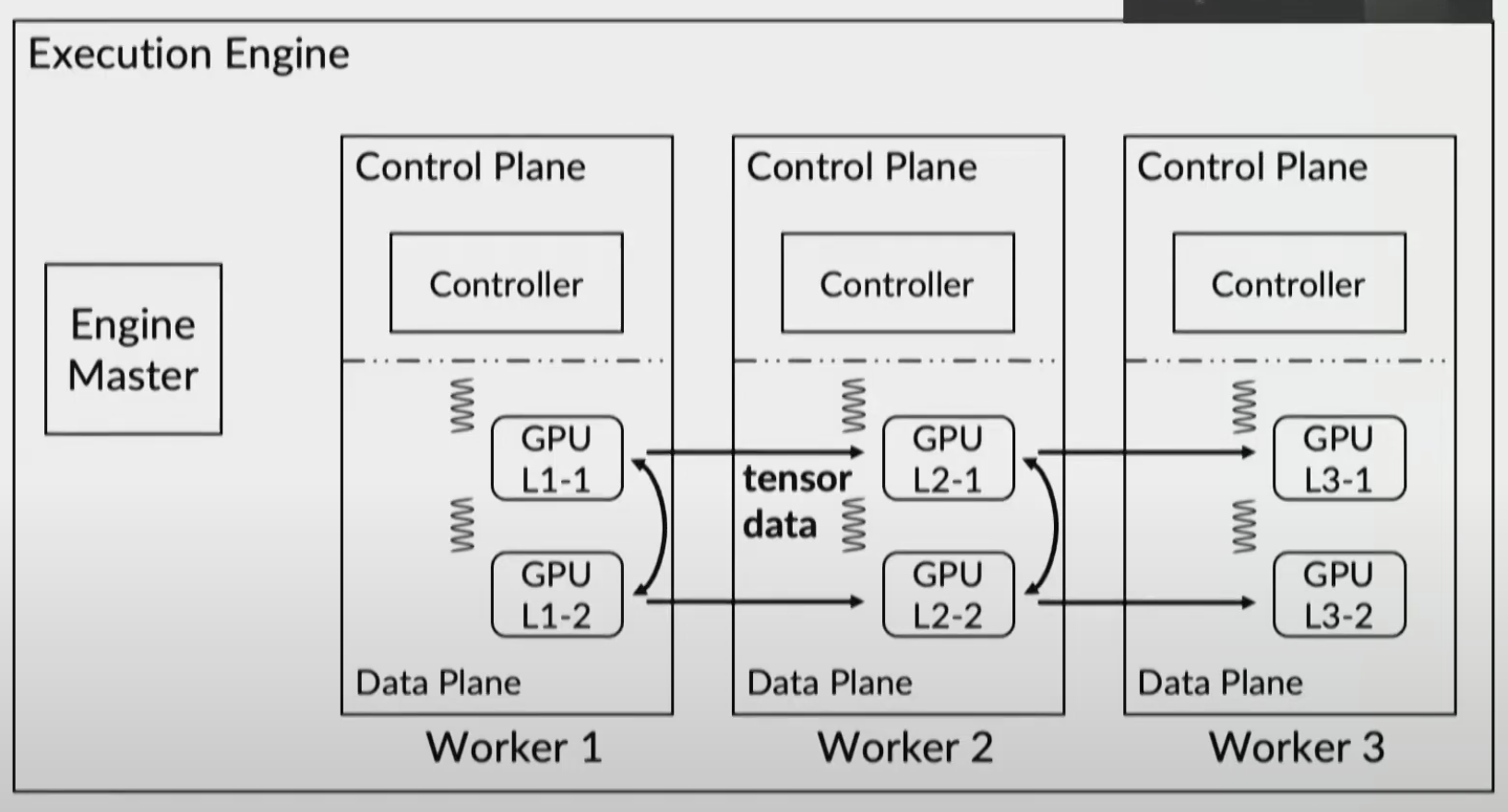
Scheduling
- FCFS
what might be important?
- what did the authors think that was important?
- new scheduling mechanism called iteration-level scheduling that schedules execution at the granularity of iteration (instead of request) where the scheduler invokes the execution engine to run only a single iteration of the model on the batch
- In addition, to apply batching and iteration-level scheduling to a Transformer model at the same time, we suggest selective batching, which applies batching only to a selected set of operations.
- what is different and new from prior work?
- generating next token in an autoregressive manner is difficult for existing system for inference due to their inflexible scheduling mechanism that cannot change the current batch of requests being proccesed
- cost of 400 GPT3 175 B instances = $190.6M/year
- down with Orca to $5.7M / year
- do i see these concepts in use today? or why weren’t these ideas adopted?
- is there anything generalizable?
- ideas that you can apply in a different domain
- applicable to any transformer based model
- protection paper example is very generalizable
- ideas that you can apply in a different domain
- new abstraction, algorithms, techniques, frameworks?
- generalizable typically
- identify a new problem space
- what is unlikely to be important?
- specific example
- specific s in evaluation
- implementation
- proofs
- discussion section