Source: https://www.databricks.com/blog/llm-inference-performance-engineering-best-practices
Questions to think about…
- What are the key performance metrics to look out for in LLM inference?
- Time To First Token (TTFT): How quickly users start seeing the model’s output after entering their query.
- Time Per Output Token (TPOT): Time to generate an output token for each user that is querying out system. Corresponds to how each user will perceive the “speed” of the model
- Latency: Overall time it takes for the model to generate the full response for a user
- Throughput: The number of output tokens per second an inference server can generate across all users and requests
- What would be the important metrics to evaluate if you were to run a language model on your PC/tablet?
- Time To First Token: users should get some feedback that something is happening.
- Time Per Output Token: on an edge device, the available resources are significantly lower hence it’s important that the generation time is reasonable for the user.
- Latency: The sum total for above metrics given an input. It’s important because we need to verify if a complete answer can be generated within a reasonable timeframe.
Intro
Best practices for how to capitalize on open source LLMs for production usage.
Understanding LLM Text Generation
How do LLMs generate text:
- “prefill” where tokens in th einput prompt are processed in parallel
- “decoding” where text is generated one ‘token’ at a time in an auto regressive manner (predicts future tokens by using previously generated tokens) Generation stops when the LLM outputs a special stop token or when a user-defined condition is met
Important Metrics for LLM serving
How should we think about inference speed?
- Time To First Token (TTFT): How quickly users start seeing the model’s output after entering their query.
- Time Per Output Token (TPOT): Time to generate an output token for each user that is querying out system. Corresponds to how each user will perceive the “speed” of the model
- Latency: Overall time it takes for the model to generate the full response for a user
- Throughput: The number of output tokens per second an inference server can generate across all users and requests
Goal: Generate text as fast as possible for as many users as we can support
- Fastest TTFT
- Highest throughput
- quickest TPOT
Useful heuristics for evaluating models:
- Output length dominates overall response latency:
- majority of latency comes from generating tokens one by one then for average latency, typically →
- Input length is not significant for performance but important for hardware requirements
- additions of 512 input tokens increases latency less than the production of 8 additional output tokens in MPT (Mosaic Pretrained Transformer]) models.
- HW constraint: Takes more memory to retain context of input
- Overall latency scales sub-linearly with model size
- On the same hw, larger models are slower, but speed ratio won’t necessarily match the parameter count ratio
Challenges in LLM Inference
General techniques:
- Operator Fusion: Combining different adjacent operators together often results in better latency
- Quantization: use smaller number of bits to represent activation and weights
- Compression: sparsity or distillation
- Parallelization: tensor parallelism across multiple devices or pipeline parallelism for larger models
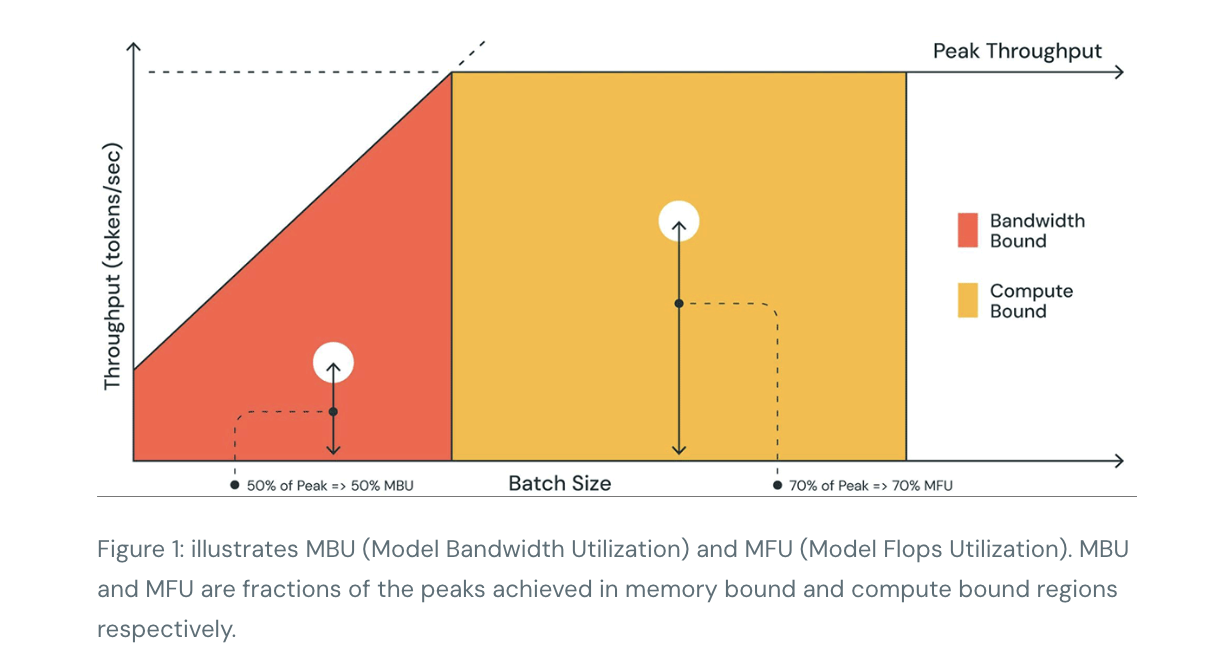
Memory Bandwidth is Key
Computations in LLMs are mainly dominated by matrix-matrix multiplication operations, these operations with small dimensions are typically memory-bandwidth-bound on most hardware.
When we generate text token by token, some of the matrices are small, especially with one prompt or a small batch. When matrices are small, the slow part is moving the model’s parameters from GPU memory into the processor’s registers and caches or the bottleneck is memory bandwidth(how fast can data move), not the compute of the matrices
Then the best predictor of how fast a model can run Inference (token generation) is the memory bandwidth rather than peak compute performance.
Model Bandwidth Utilization (MBU)
How optimized is an LLM inference server?
- LLMs at smaller batch size is bottlenecked on how quickly we can load model parameters from device memory to compute units (see Memory Bandwidth)
- To measure hardware’s utilization, use a new metric called Model Bandwidth Utilization (MBU)
- (achieved memory bandwidth) / (peak memory bandwidth)
- where achieved memory bandwidth is:
- ((total model parameter size + KV cache size) / TPOT)
- ((total model parameter size + KV cache size) / TPOT)
Benchmarking Results
Latency
As input prompts lengthen, time to generate the first token starts to consume a substantial portion of total latency. Tensor parallelizing across multiple GPUs helps reduce this latency.
- At larger batch sizes, higher tensor parallelism leads to a more significant relative decrease in token latency.
Throughput
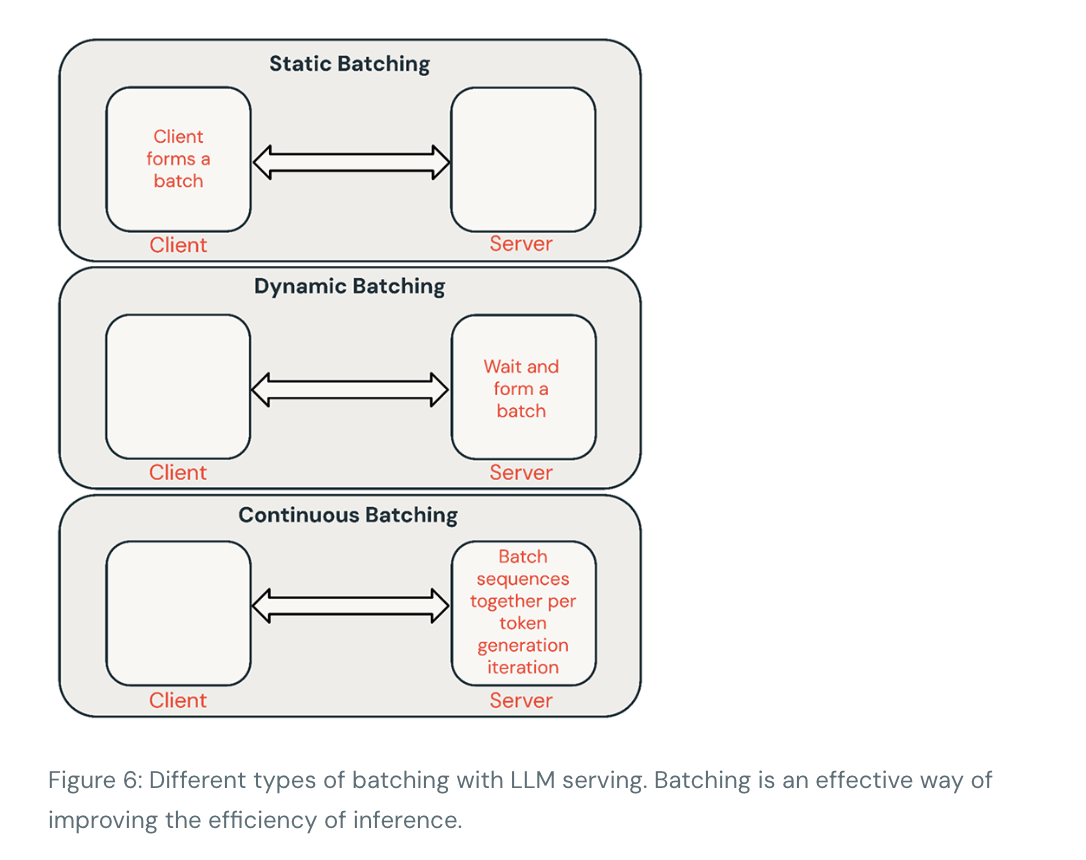
We can trade off throughput and time per token by batching requests together. Grouping queries during GPU evaluation increases throughput compared to processing queries sequentially, but each query will take longer to complete (ignoring queueing effects).
- Static batching: Client packs multiple prompts into requests and a response is returned after all sequences in the batch have been completed. Our inference servers support this but do not require it.
- Dynamic batching: Prompts are batched together on the fly inside the server. Typically, this method performs worse than static batching but can get close to optimal if responses are short or of uniform length. Does not work well when requests have different parameters.
- Continuous batching (Best Approach for shared services): The idea of batching requests together as they arrive was introduced in this excellent paper and is currently the SOTA method. Instead of waiting for all sequences in a batch to finish, it groups sequences together at the iteration level. It can achieve 10x-20x better throughput than dynamic batching.
Latency Trade-Off
Request latency increases with batch size.
Optimization Case Study: Quantization
Naive quantization techniques can lead to substantial degradation in model quality
Still in works on evaluation…
Conclusions and Key Results
- Identify optimization target
- Pay attention to the components of latency
- Memory bandwidth is key
- Batching is critical
- Explore In depth optimizations
- Hardware Configurations
- Data Driven Decisions: measure end-to-end perf