LLM Inference
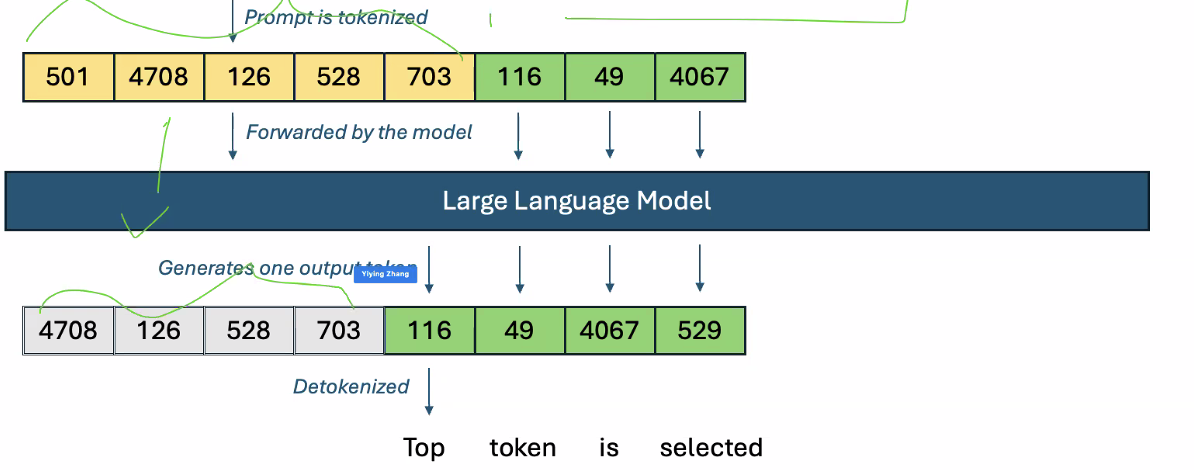 LLMs generate the best next token
LLMs generate the best next token
Prefill vs Decode
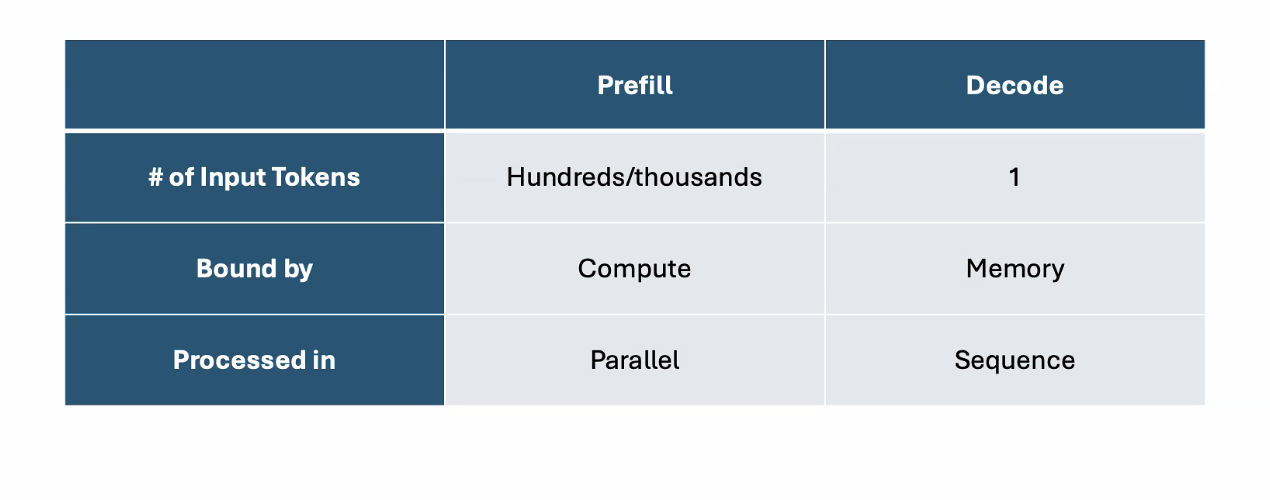 Decode is autoregressive
Decode is autoregressive
Compute vs Memory Bound
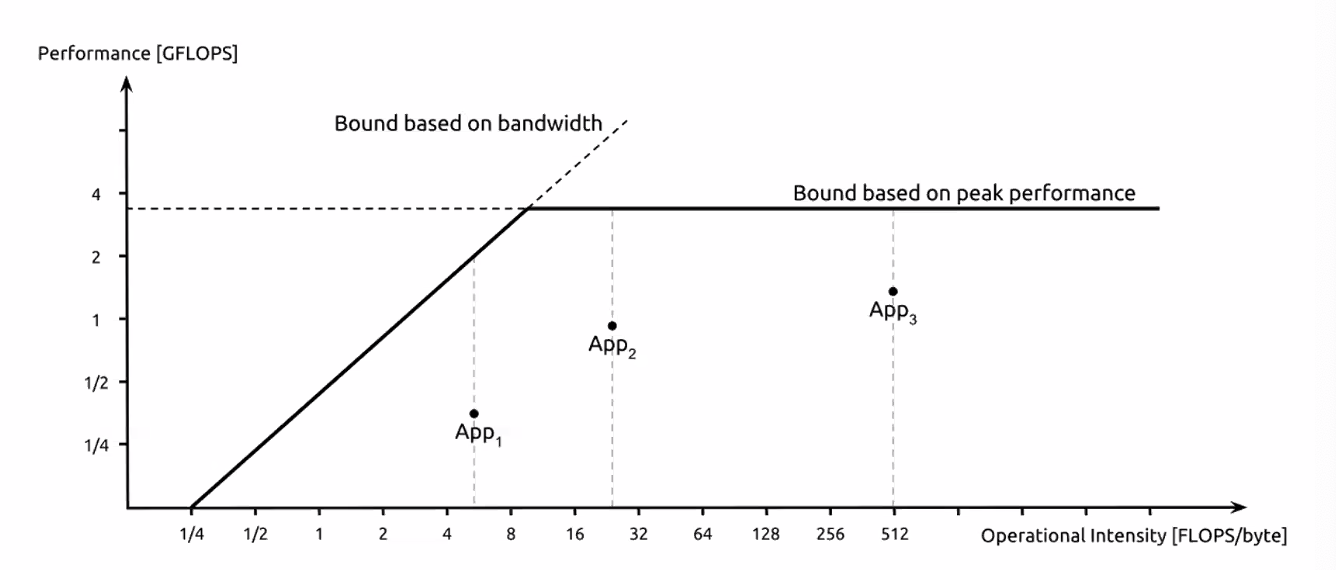 Roofline graph
Roofline graph
Approximation Model
- model should be order(s) of magnitude smaller
- E.g. 7B and 68M
- Either fewer layer, smaller hidden dimension size, fewer attention heads
- Also called “small specialized model (SSM)” or “draft model”
- Same vocabulary as the LLM (also called “target model”)
- Ideally trained on the same data
Speculative Decoding
- Drafting
- The overhead is magnitudes smaller in draft model that system can tolerate performance wise
- Verification
- Decide how many accept and reject
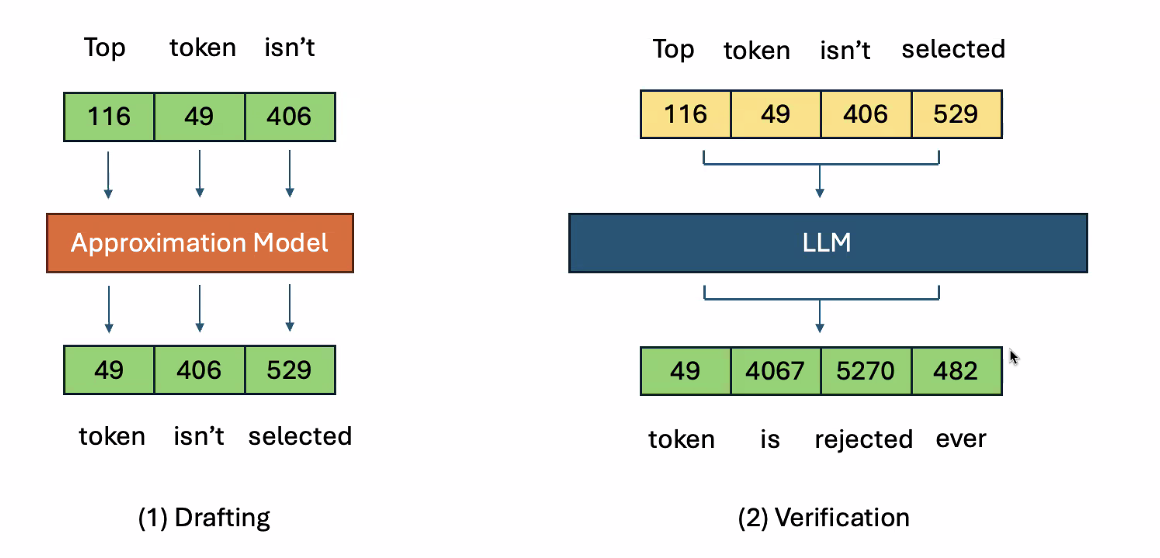
- Decide how many accept and reject
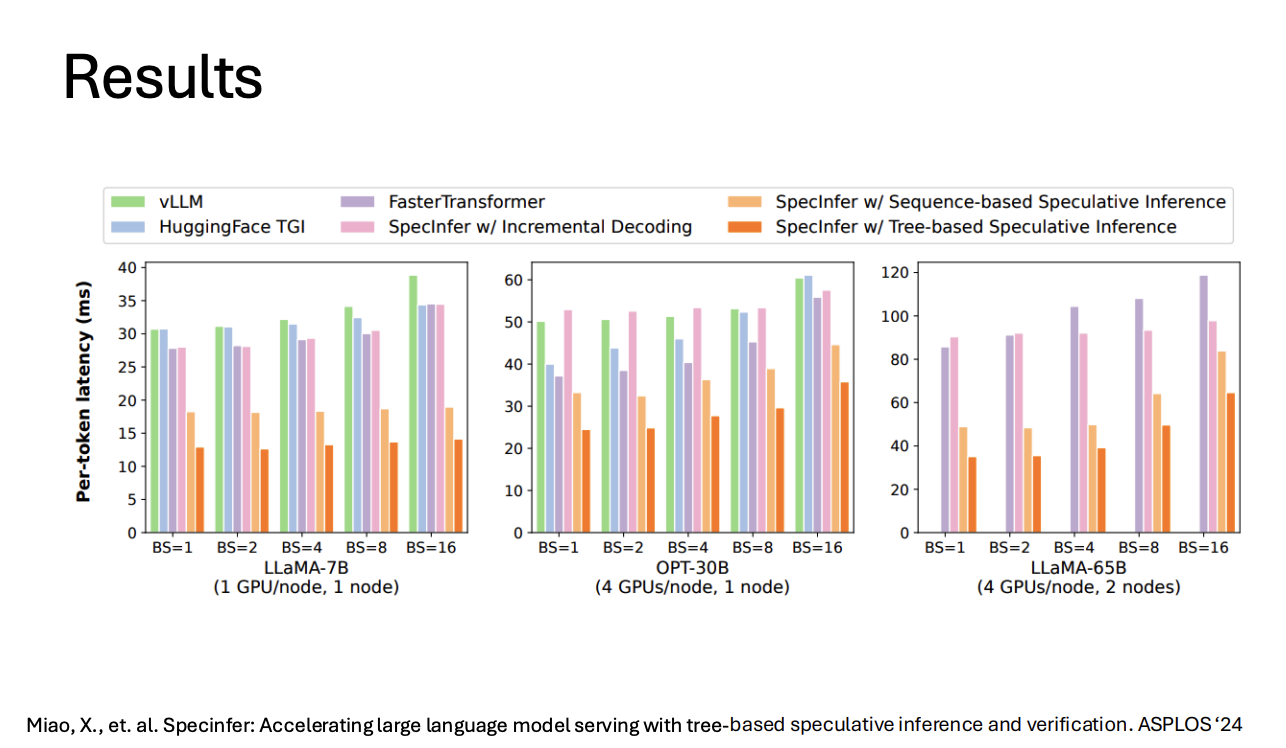
Results
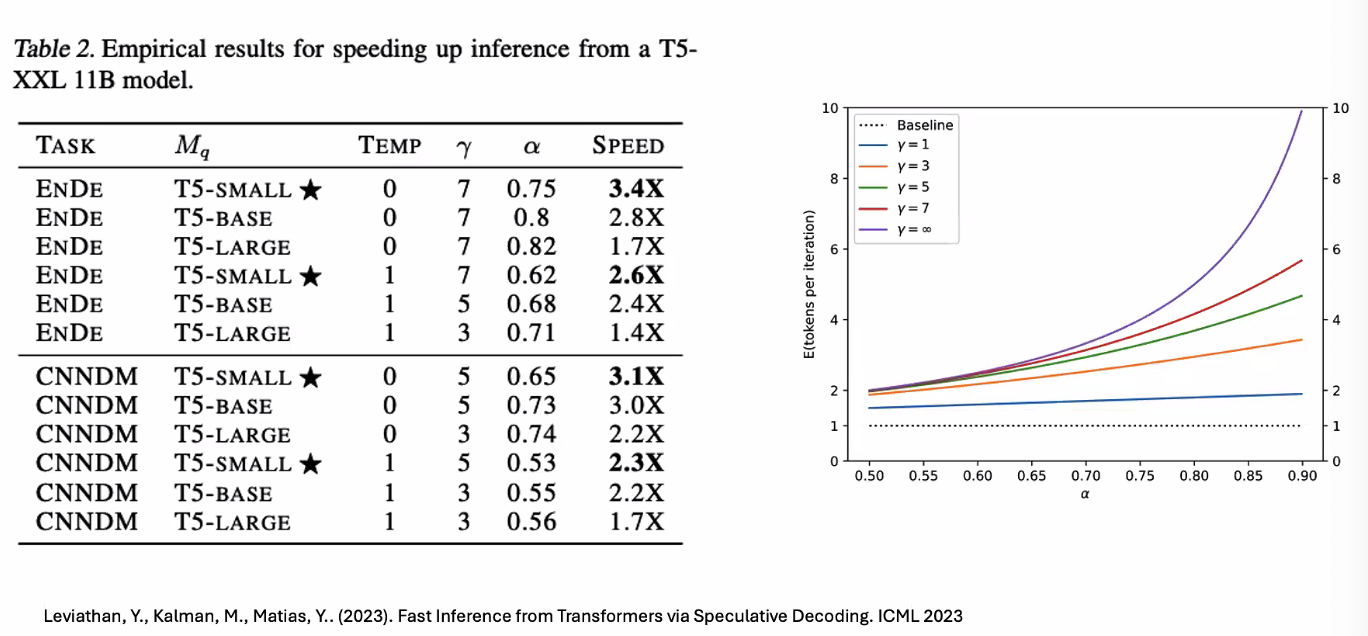
Cost of Speculation
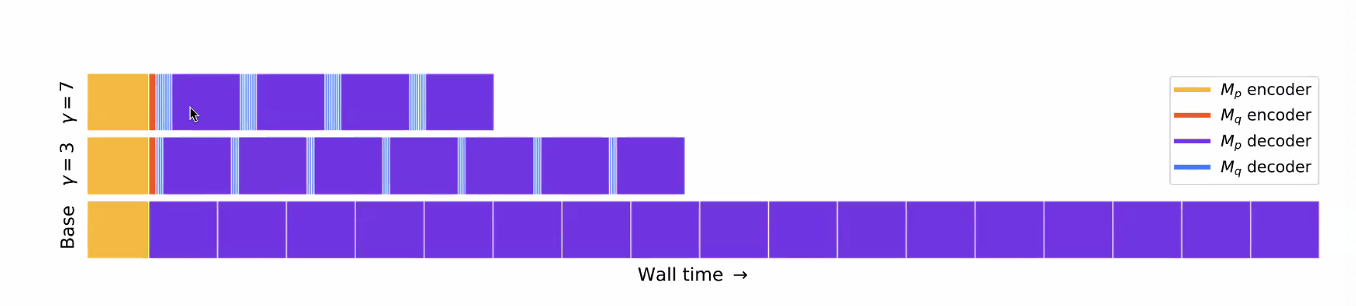 is target, is draft
is target, is draft
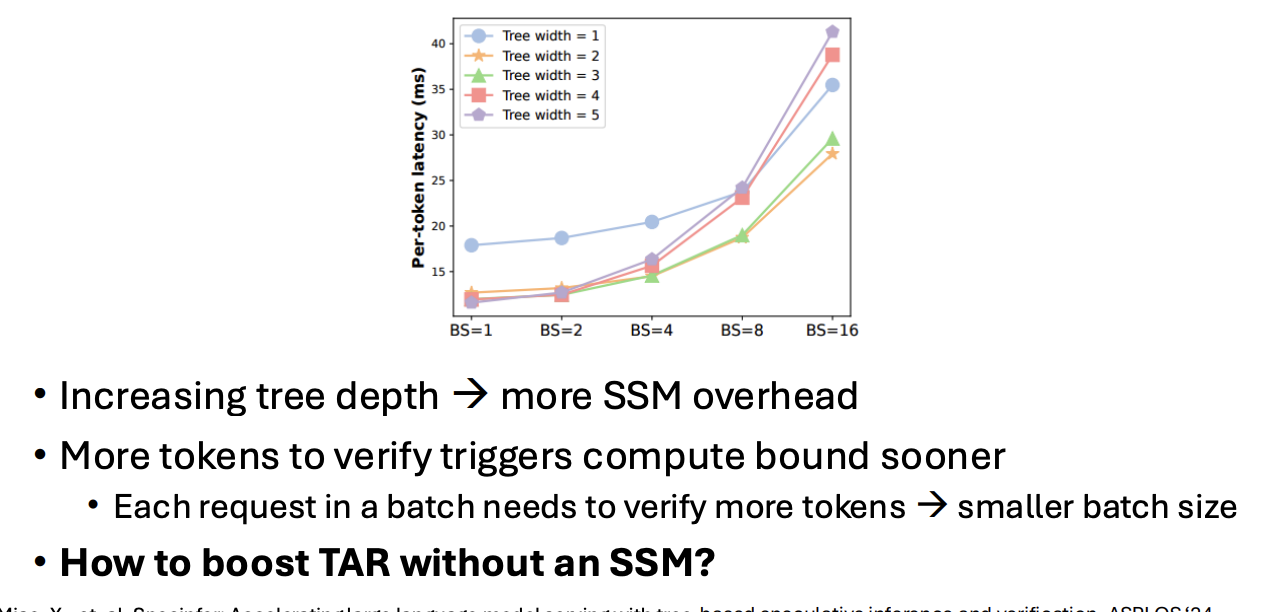
- As speculative depth increases, so does overhead
- if TAR is too low, this overhead can dominate
- instead, we can sample a tree from the draft model
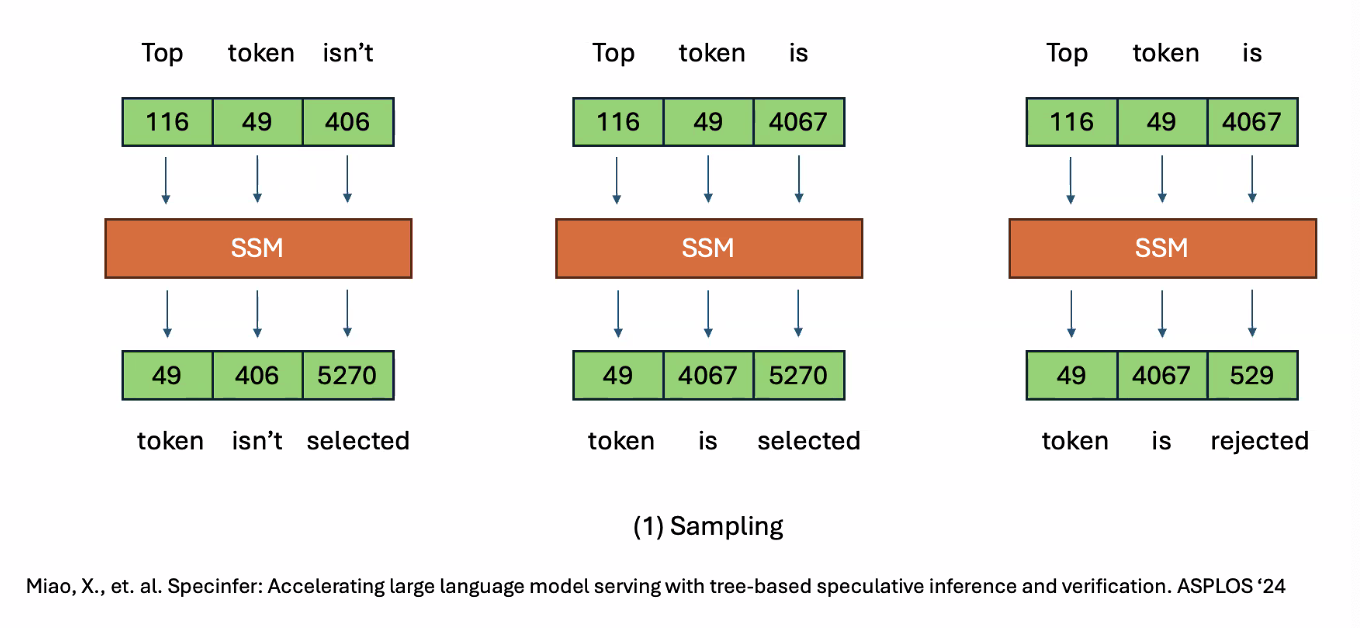
Sampling
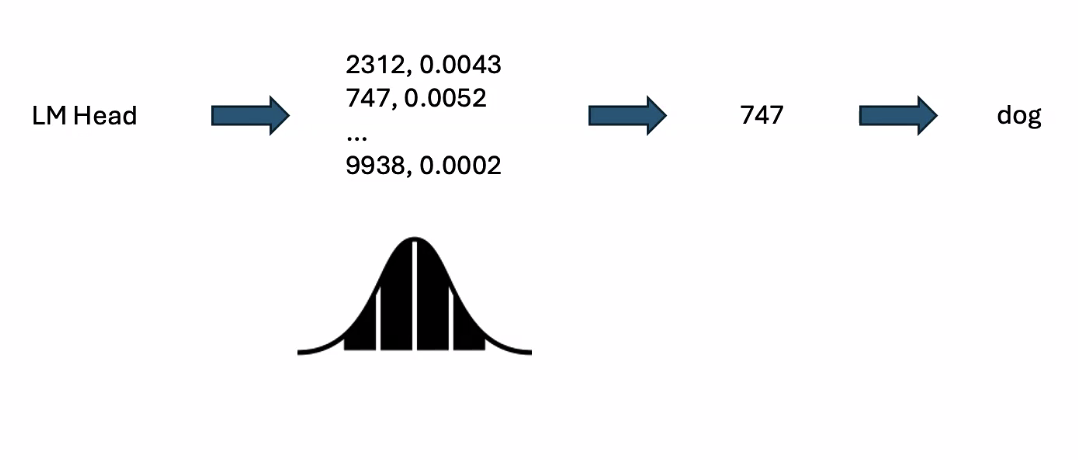 Greedy decoding would select the token with the highest probability
Stochastic decoding would be random selection
Greedy decoding would select the token with the highest probability
Stochastic decoding would be random selection
Tree Attention
- sampling
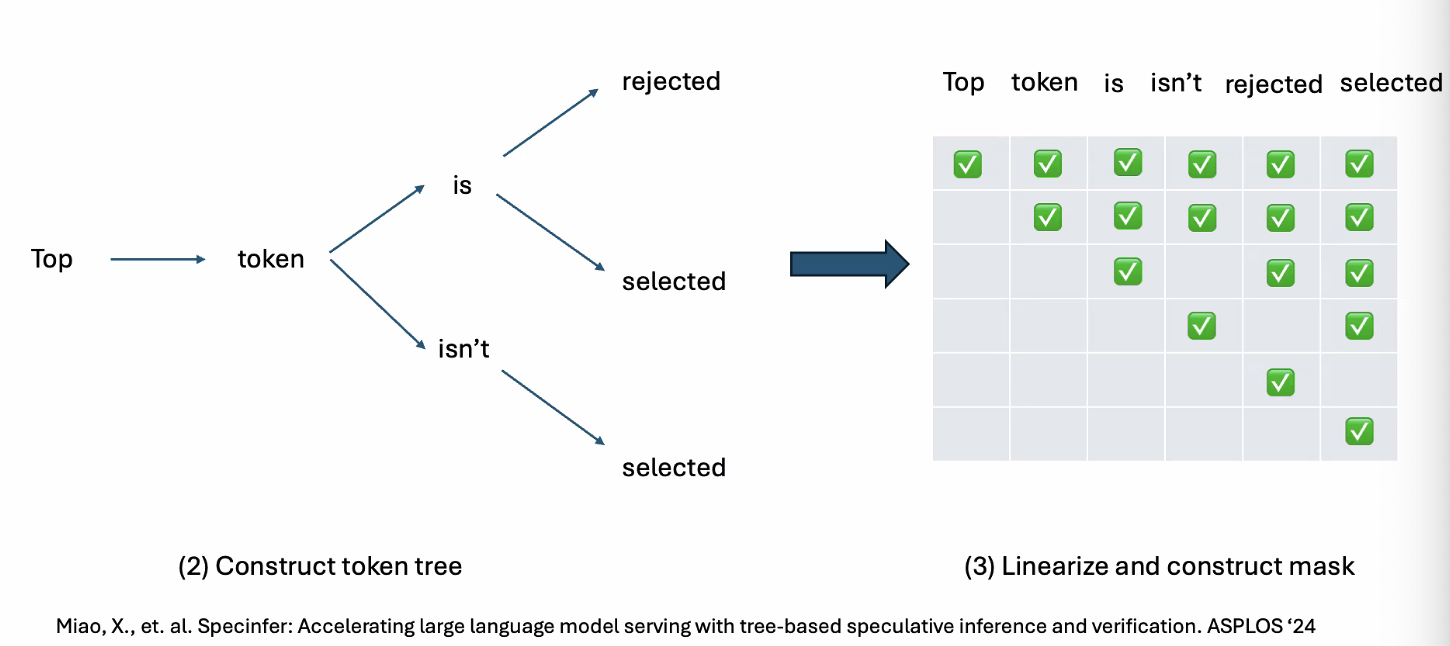
- Construct token tree
- Linearize and construct mask
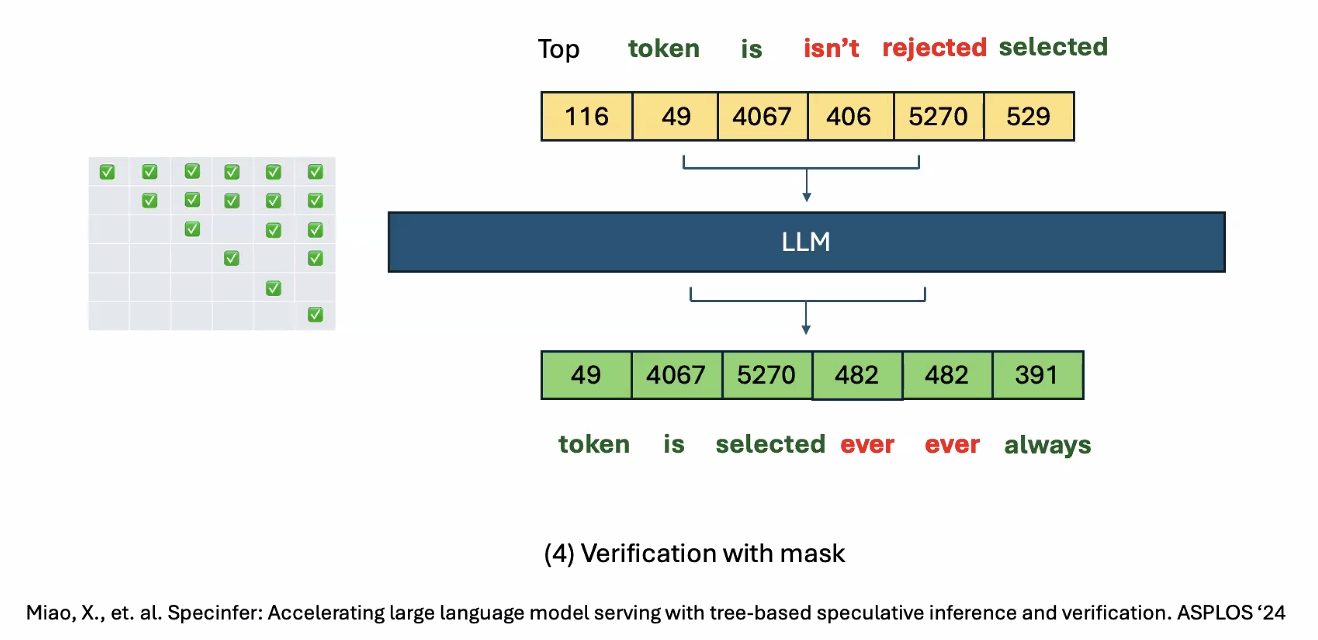
- Verification with mask
Stems beam search (TODO lookup)
Stochastic Decoding
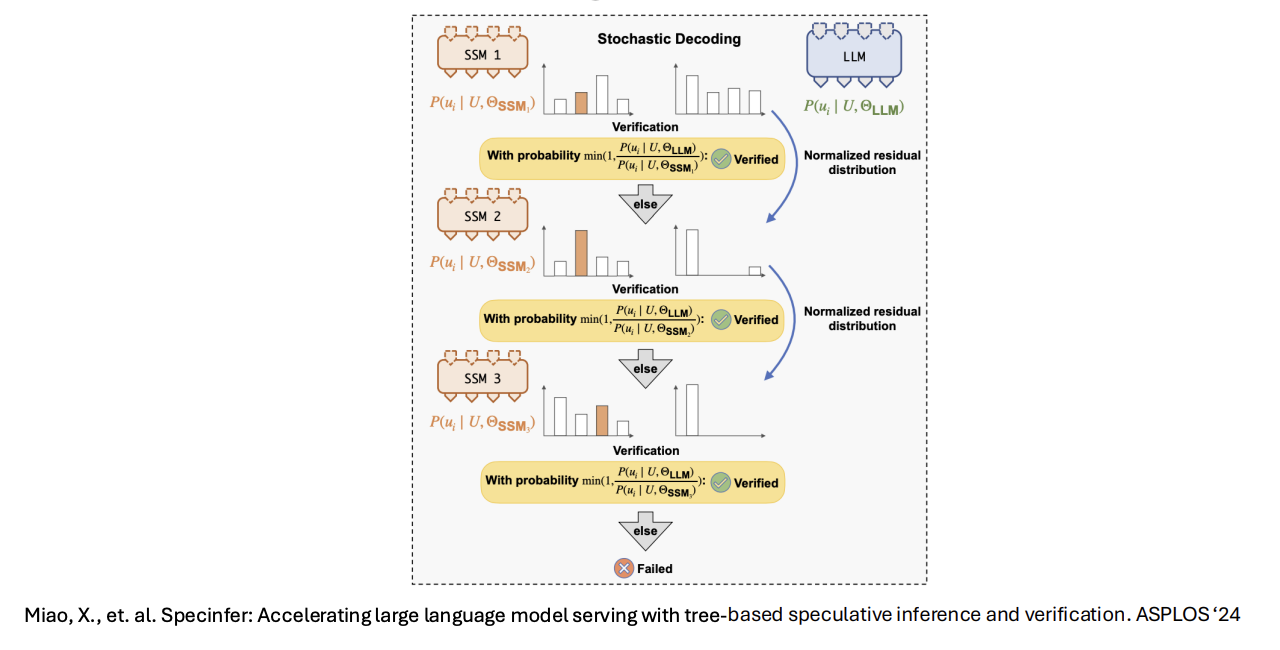
Results
Tradeoffs
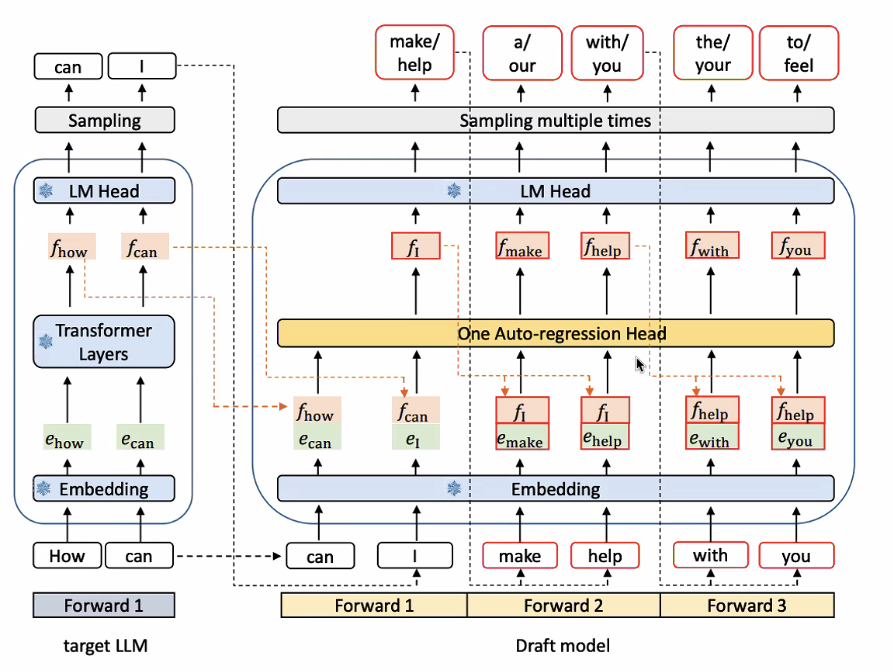
EAGLE
- used currently
- Data at the token/LM head level is very uncertain and not as rich
- Instead, train an auto-regressive head right before the LM head
- 1 fully-connected linear layer
- 1 transformer decoder layer
- Drafting overhead is negligible
- Reduced kernel launch overhead
- Autoregressive head << draft model size