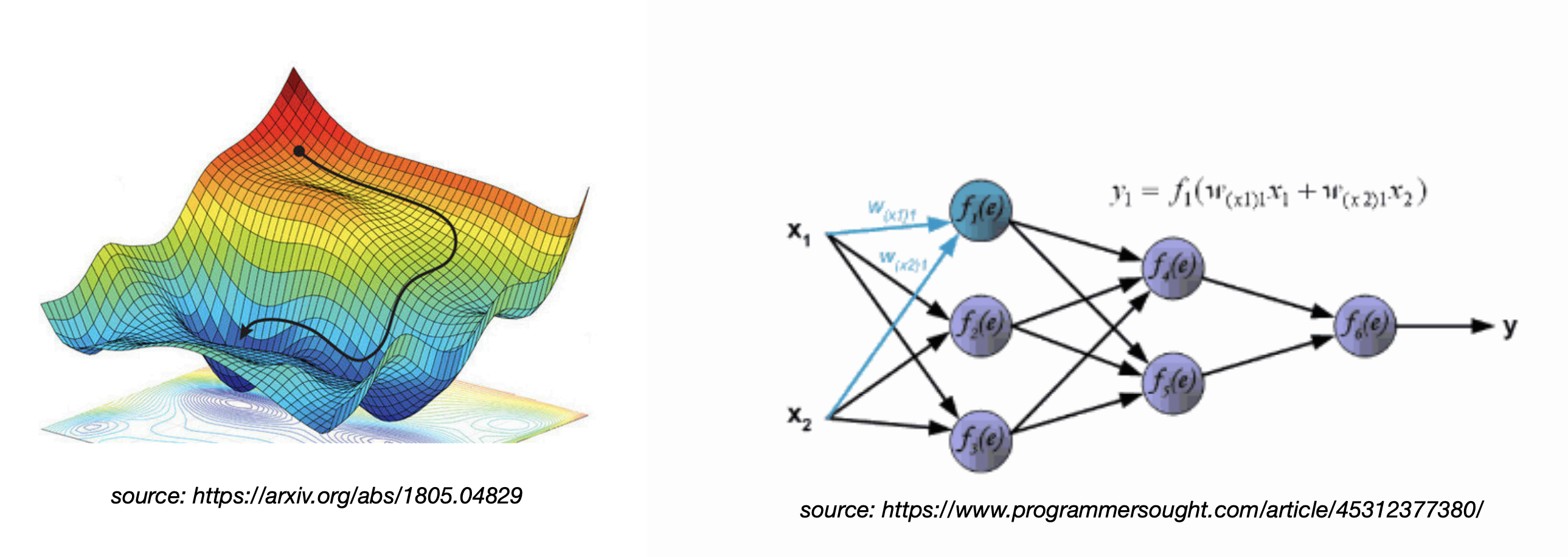
Neural Network Training
- Feedforward and back propagation gradient descent
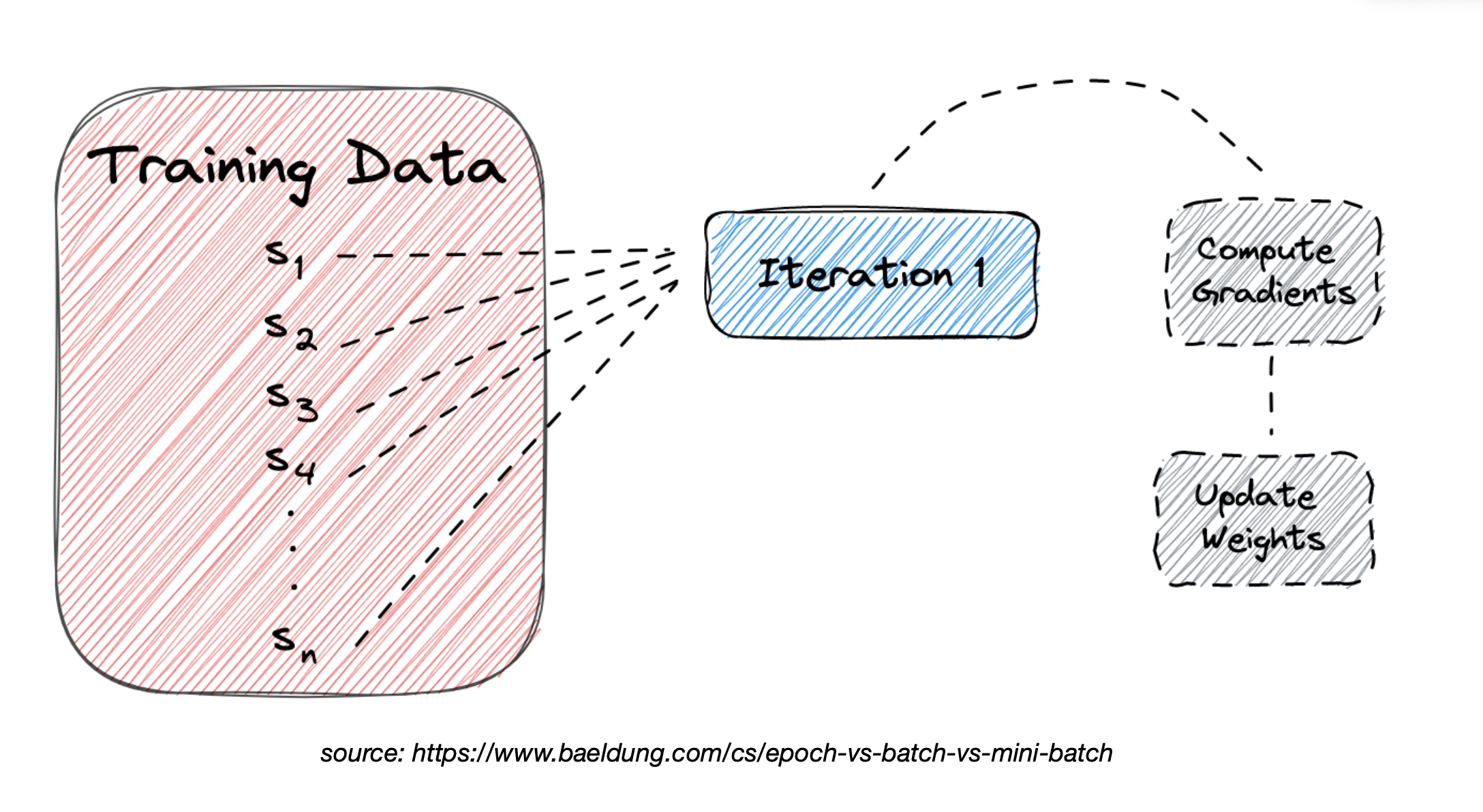
Batch Gradient Descent
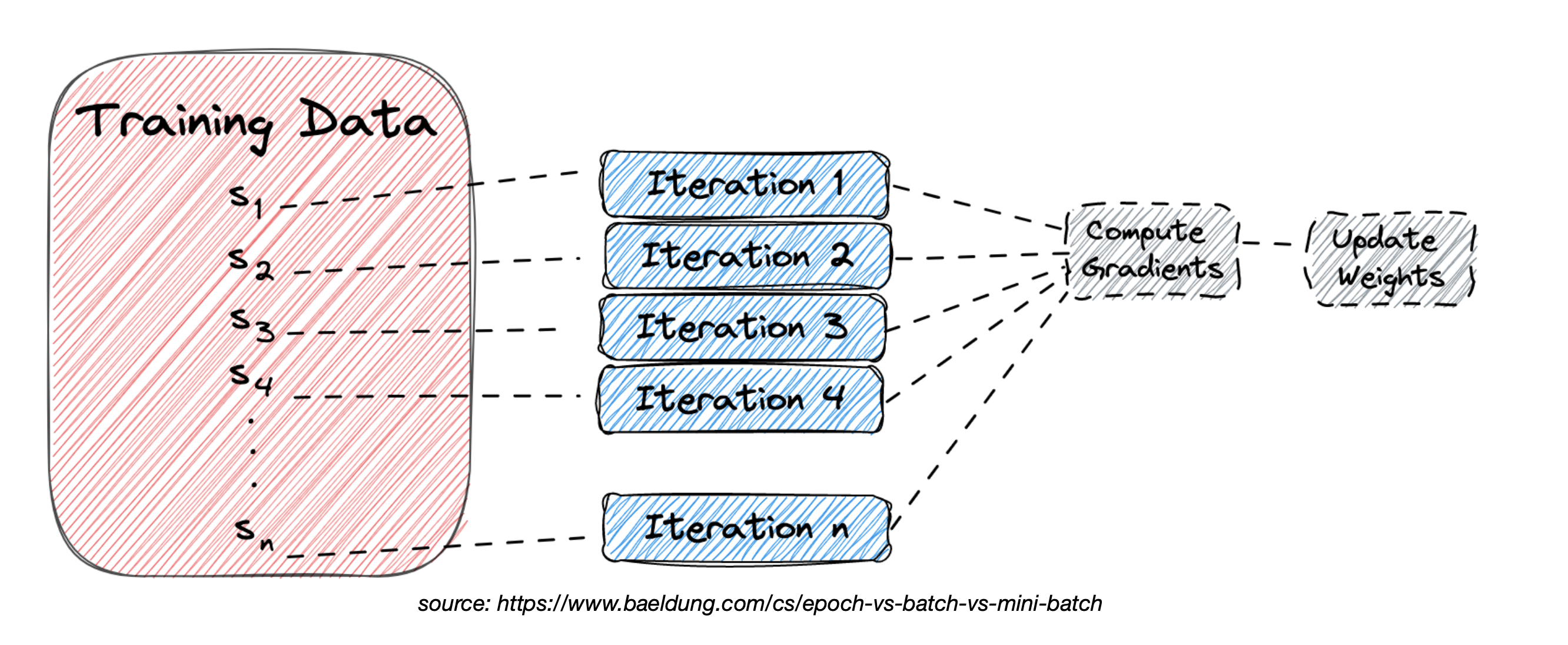
Stochastic Gradient Descent
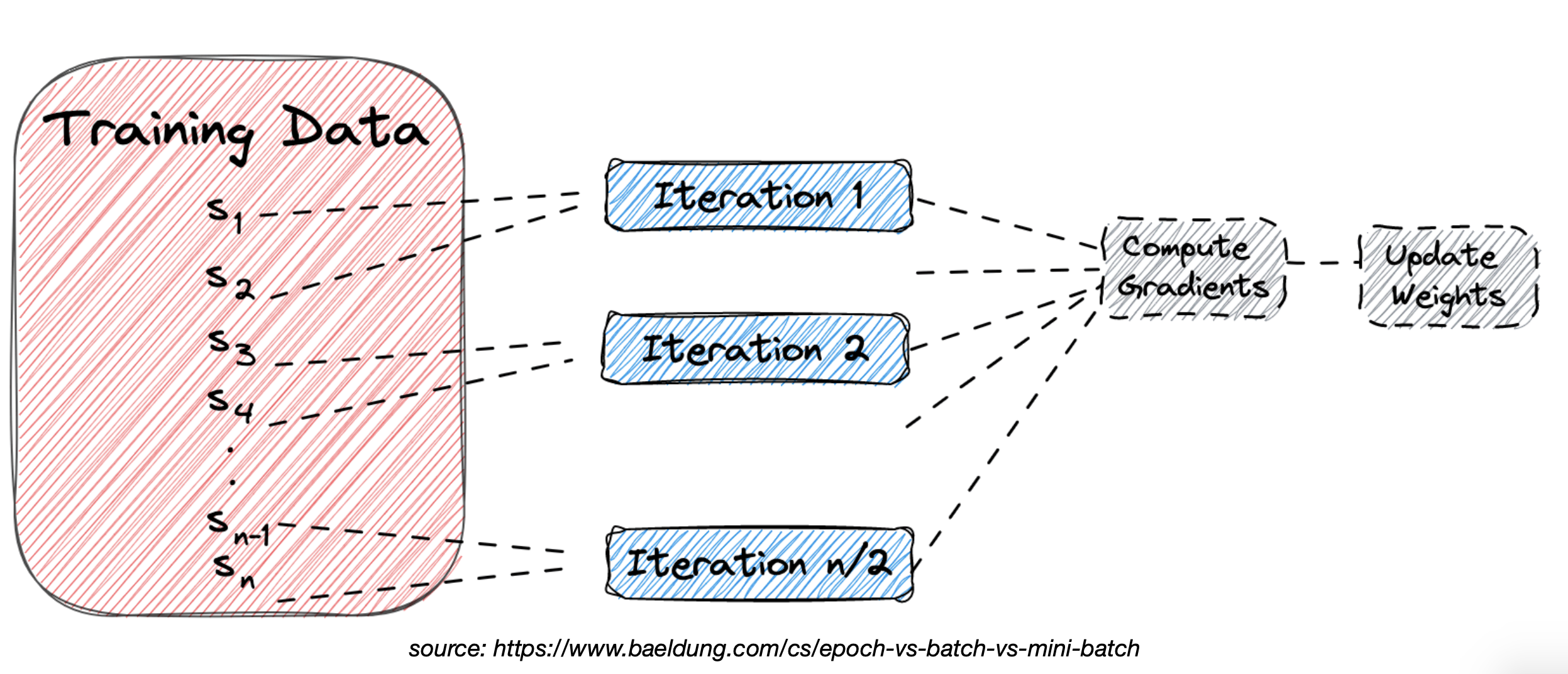
Minibatch-Based SGD
Model Training Cost
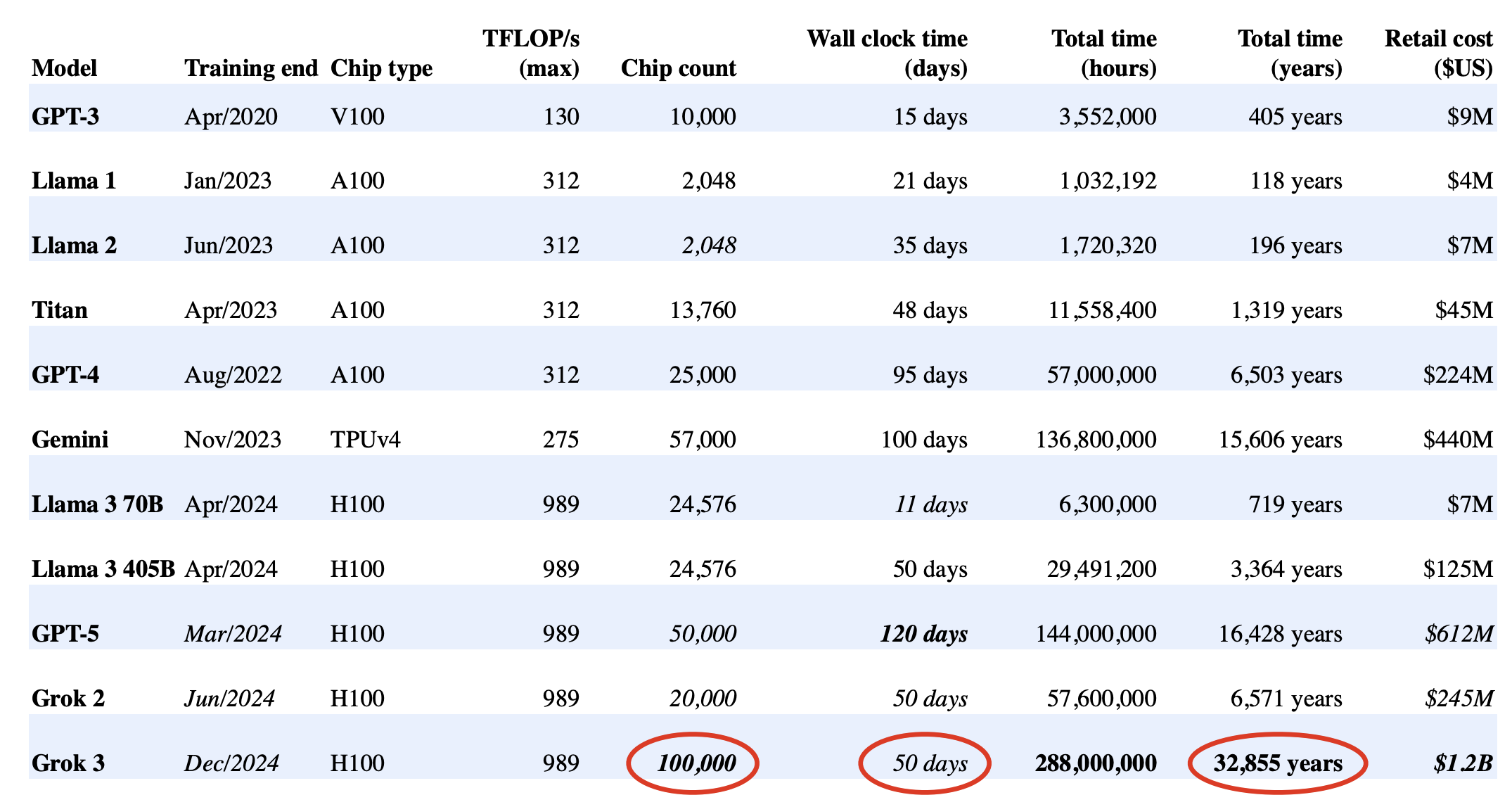
Distributed Training is Necessary
- Developers / Researchers’ time are more valuable than hardware .
- If a training takes 10 GPU days • Parallelize with distributed training
- 1024 GPUs can finish in 14 minutes (ideally)!
- The develop and research cycle will be greatly boosted
Introduction to Distributed Training
Data Parallelism
- Train by splitting the training data over a bunch of GPUs
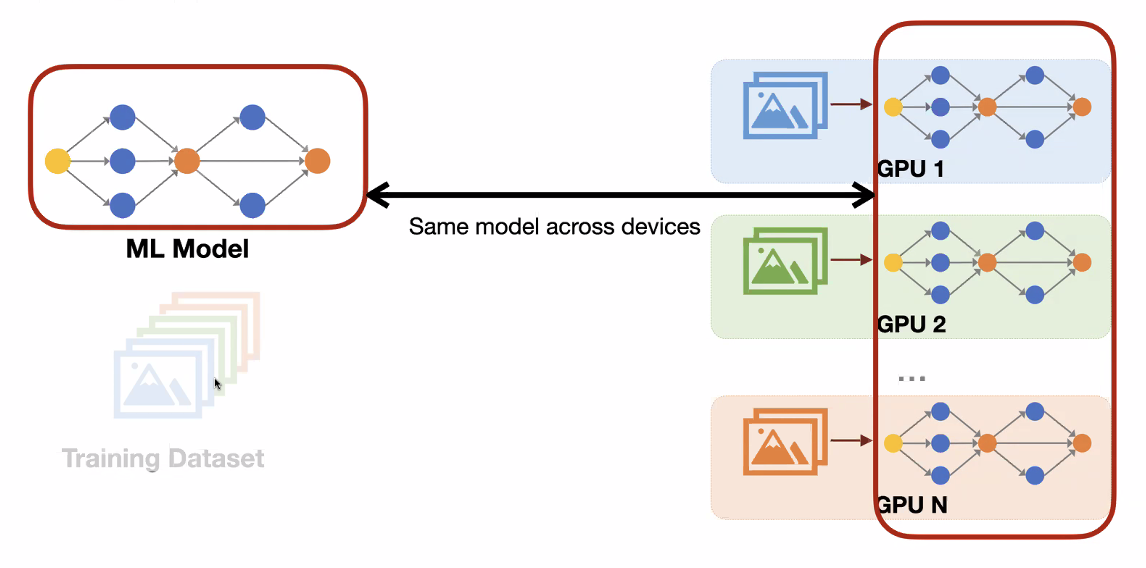
Scaling Distributed Machine Learning with the Parameter Server
- All worker nodes synchronize to a single point
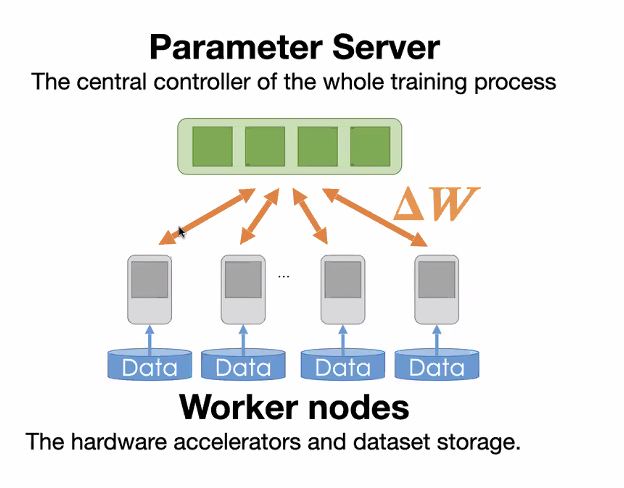
- Two different roles in framework:
- Parameter Server: receive gradients from workers and send back the aggregated results
- Workers: compute gradients using splitted dataset and send to parameter server
- Problems
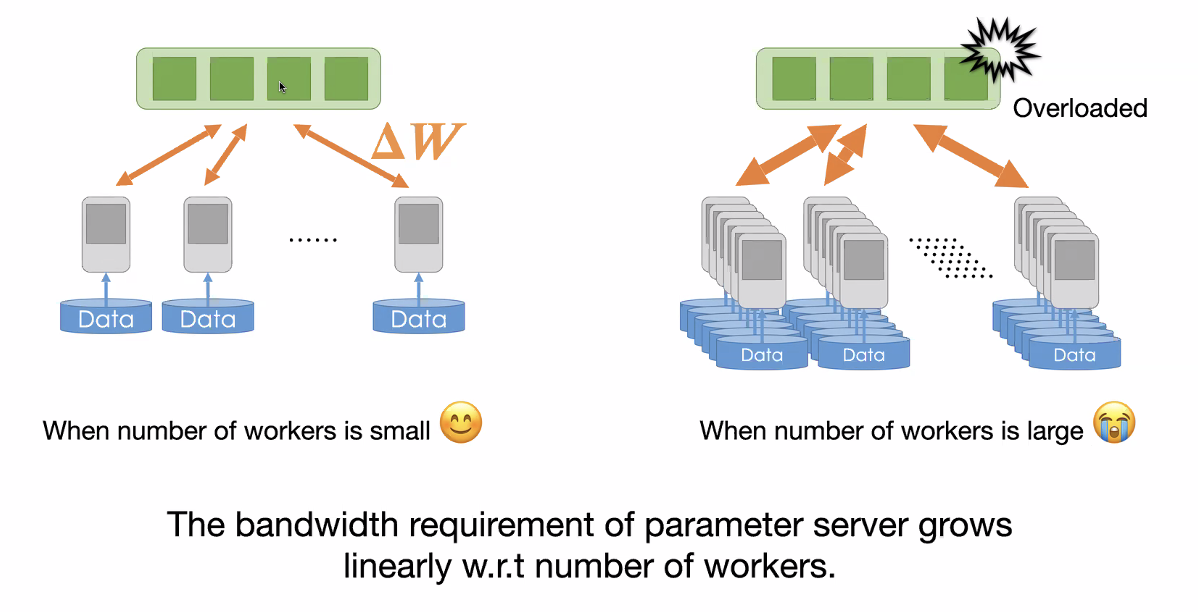
Distributed Communication
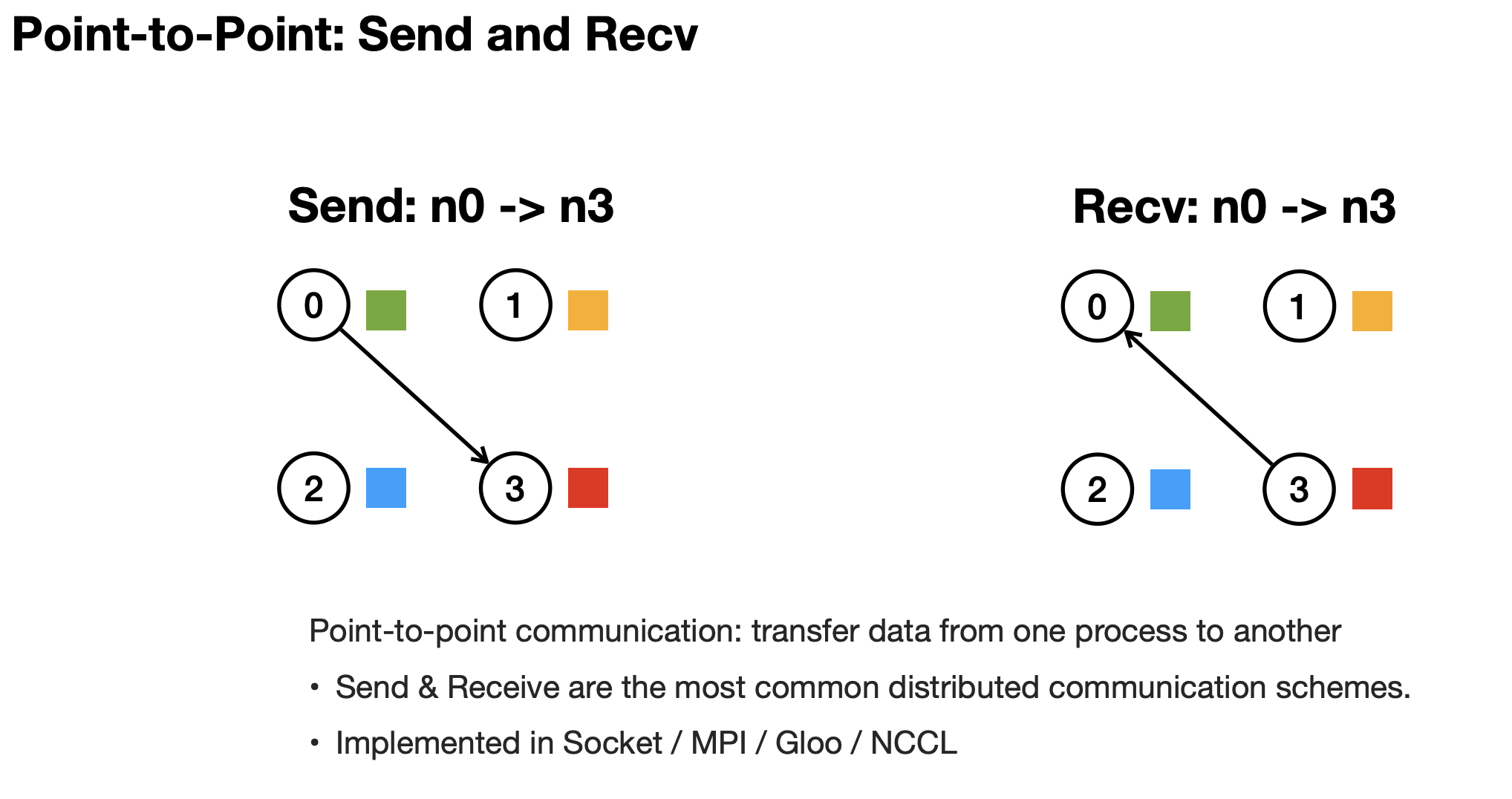
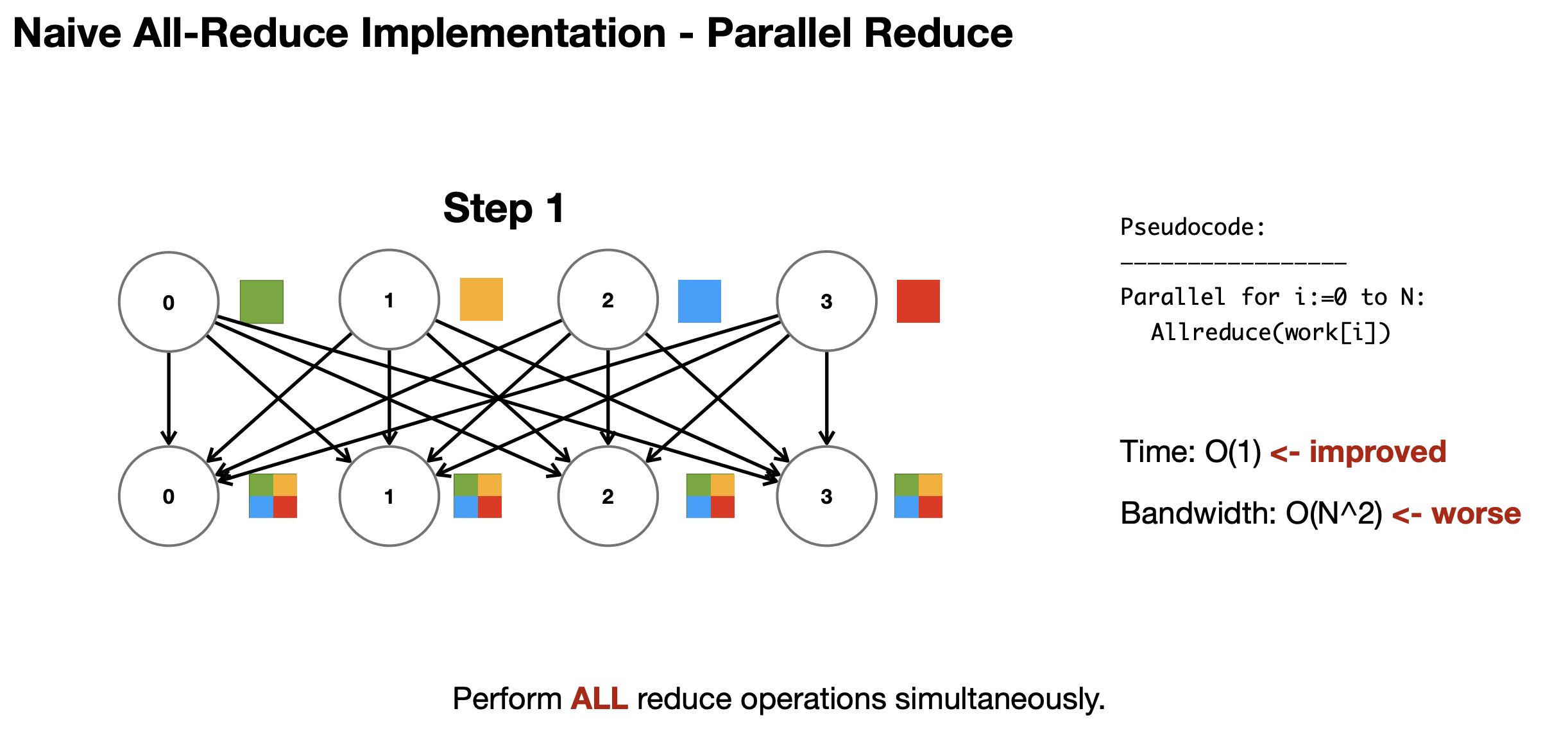

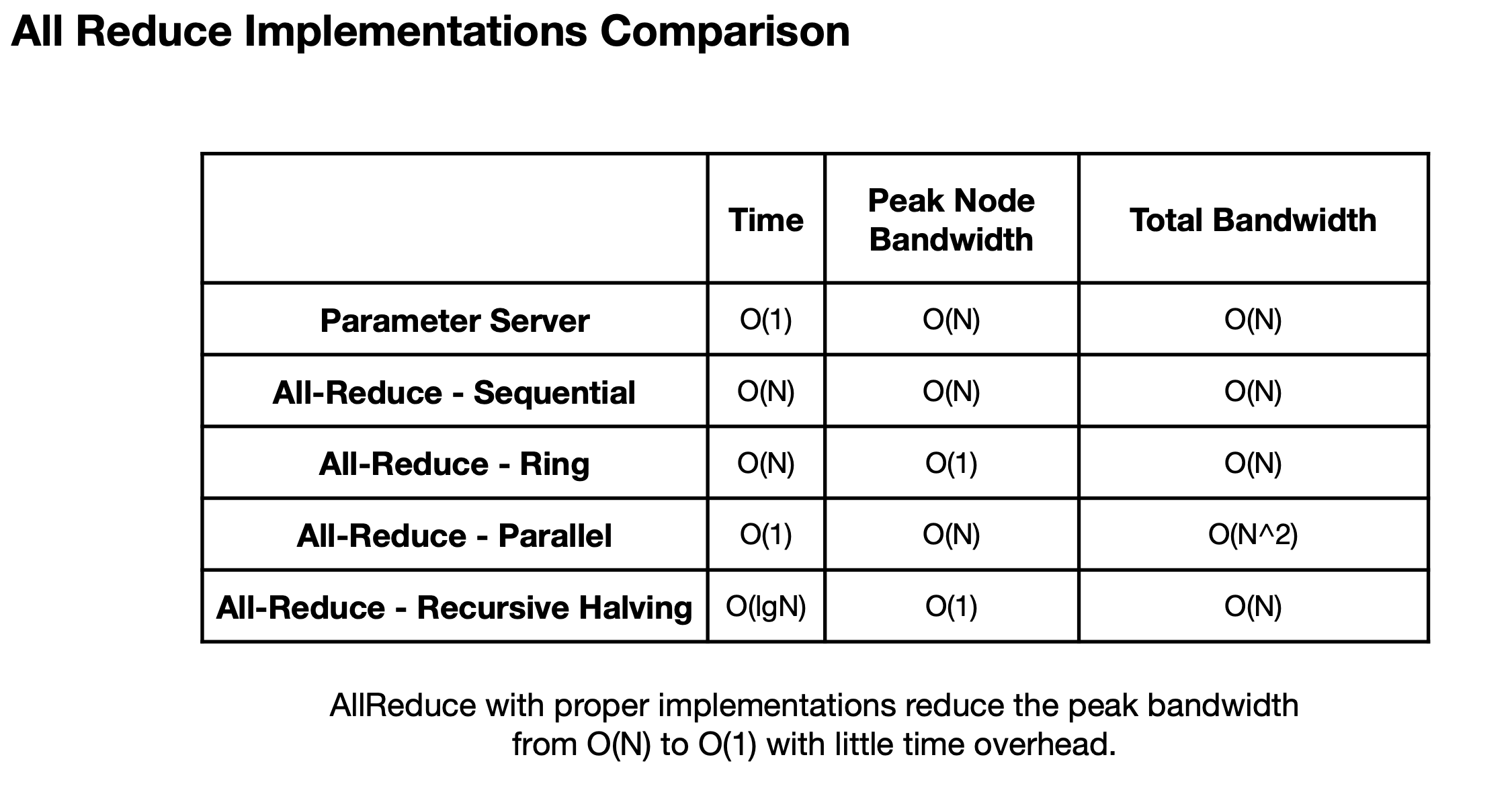 Note: last two are typically used in industry atm
Note: last two are typically used in industry atm