Outline
- Transformer primer
- Introduction oriented for LLM infra (perf problems), not the theory
- LLM performance
Self Attention
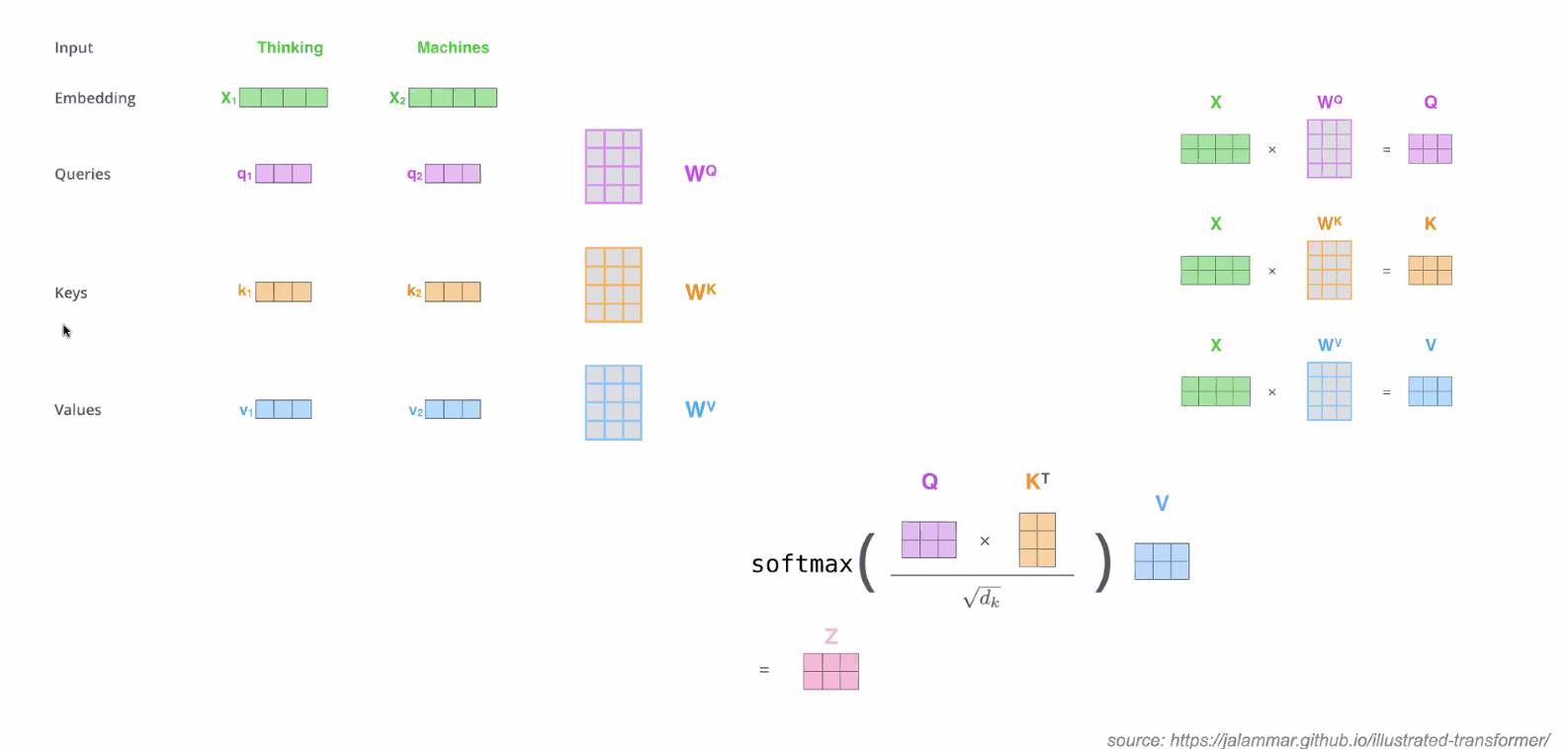 Note: input is 2 words, “Thinking Machines”
Note: input is 2 words, “Thinking Machines”
- Embedding = transforming input to set of bits
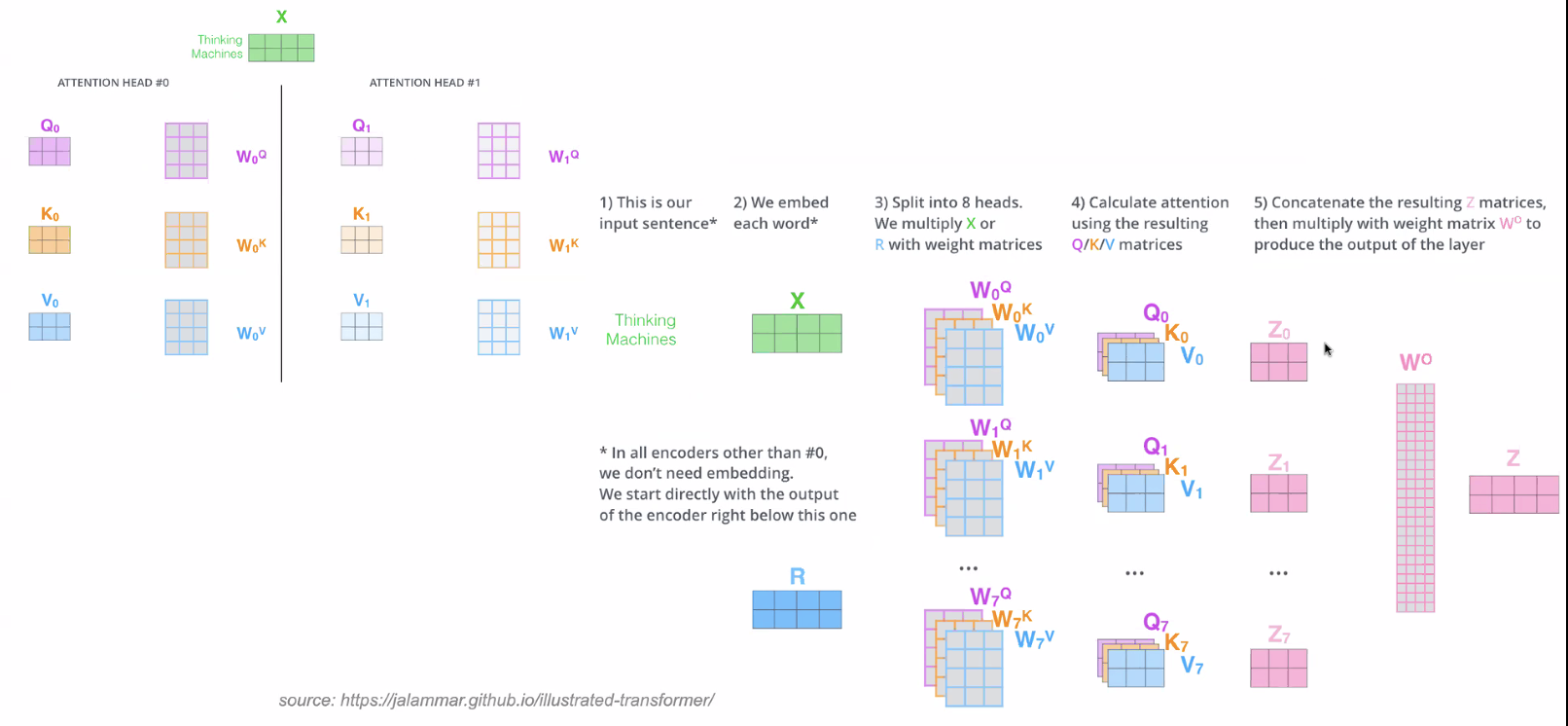
Multi-headed Attention
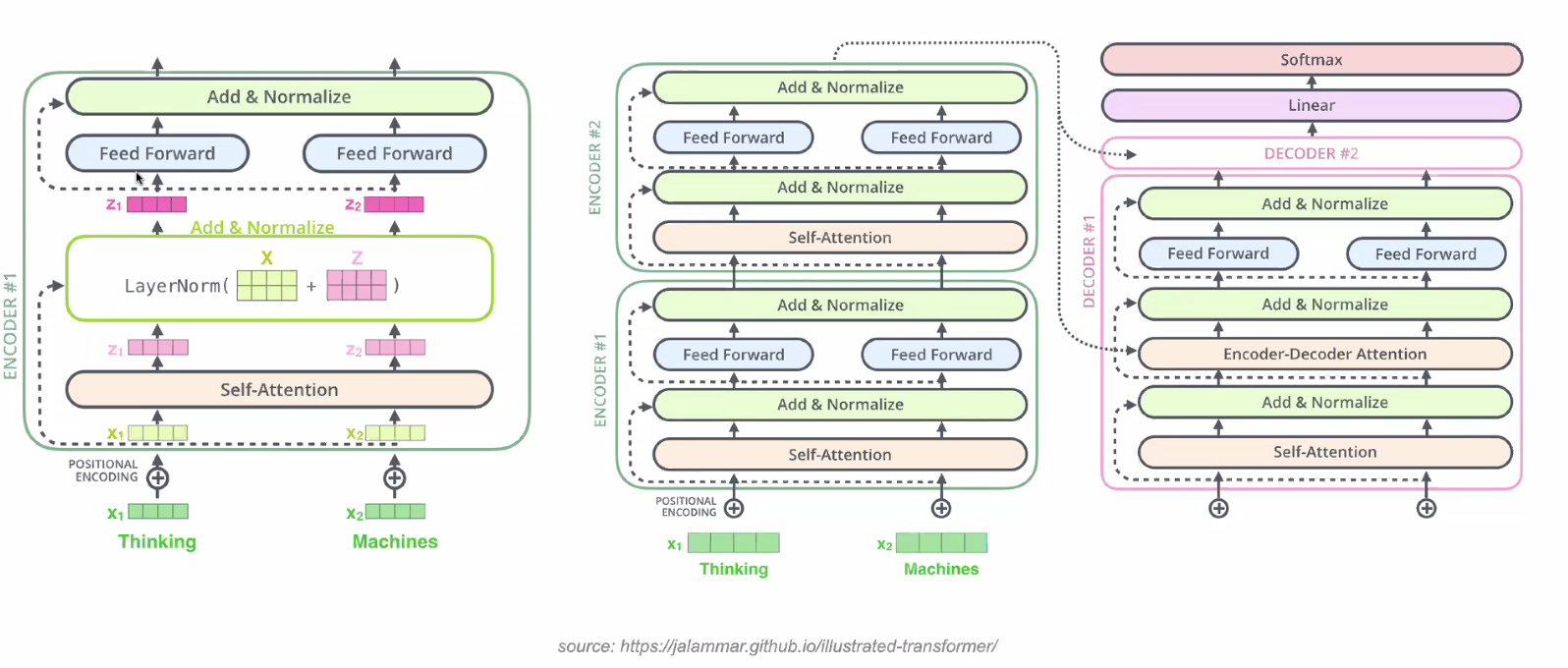
Transformer Model
Inference Process of LLMs
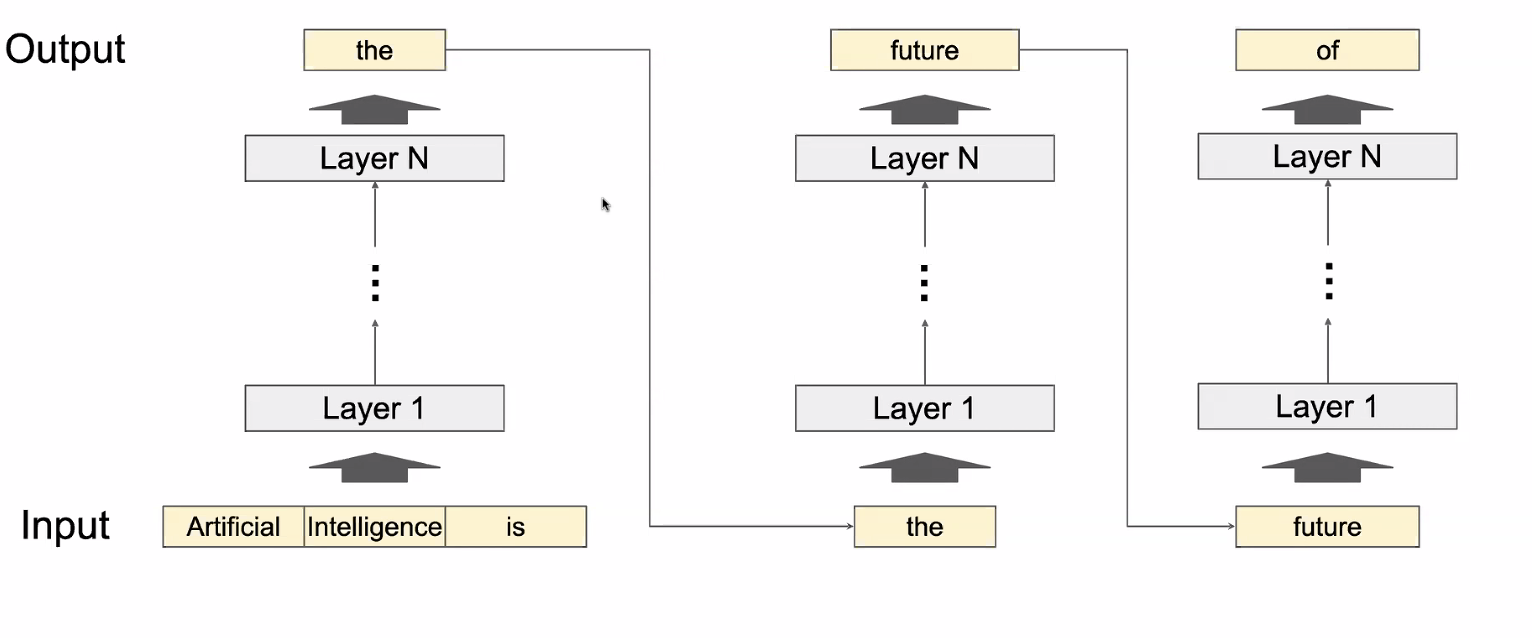 Outputs in an autoregressive way, repeats until it reaches a maximum length or end token
Outputs in an autoregressive way, repeats until it reaches a maximum length or end token
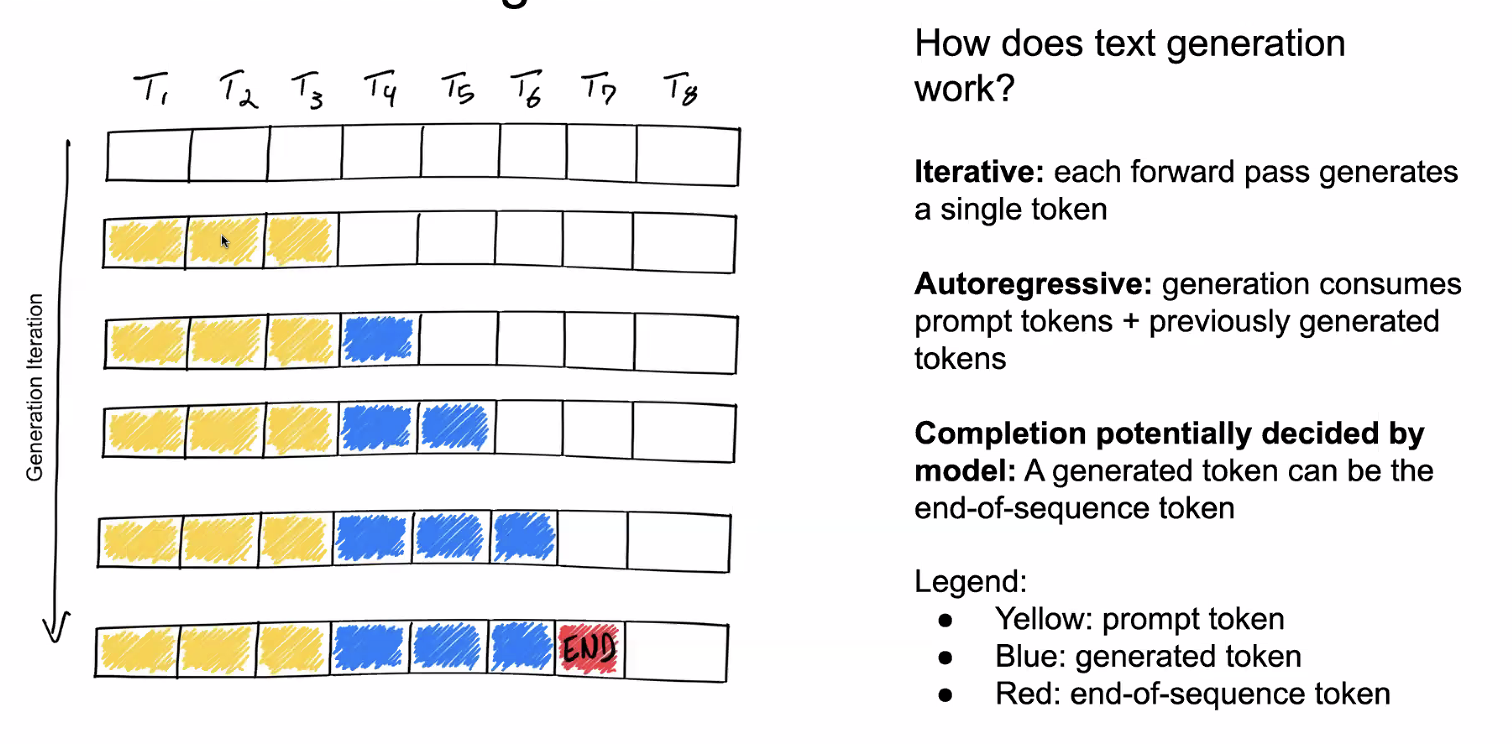 Note: iterative = forward pass
Note: iterative = forward pass
Prefix and Decoding Stages
- Prefill: processing model input (all in one forward pass)
- Decode: generating output token, one at a time
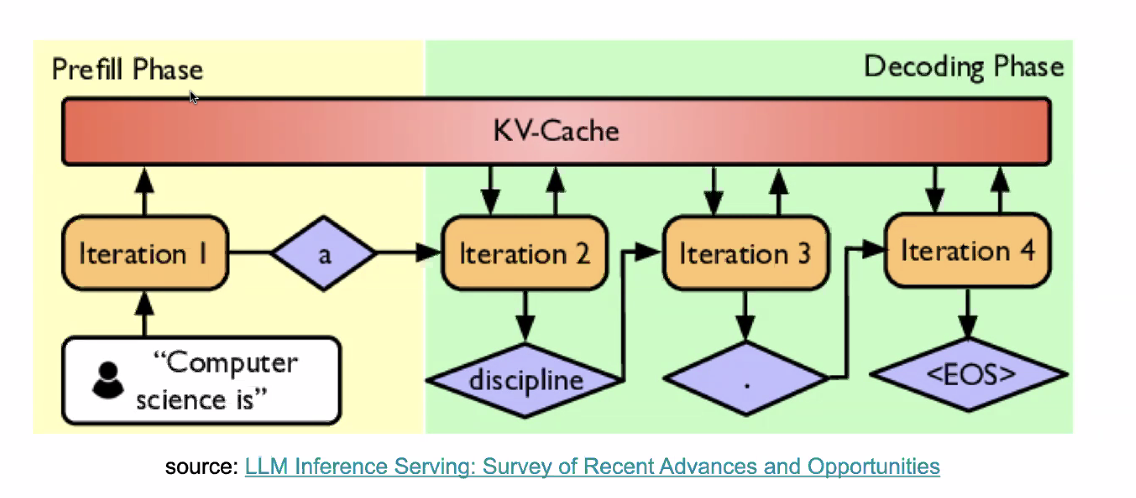
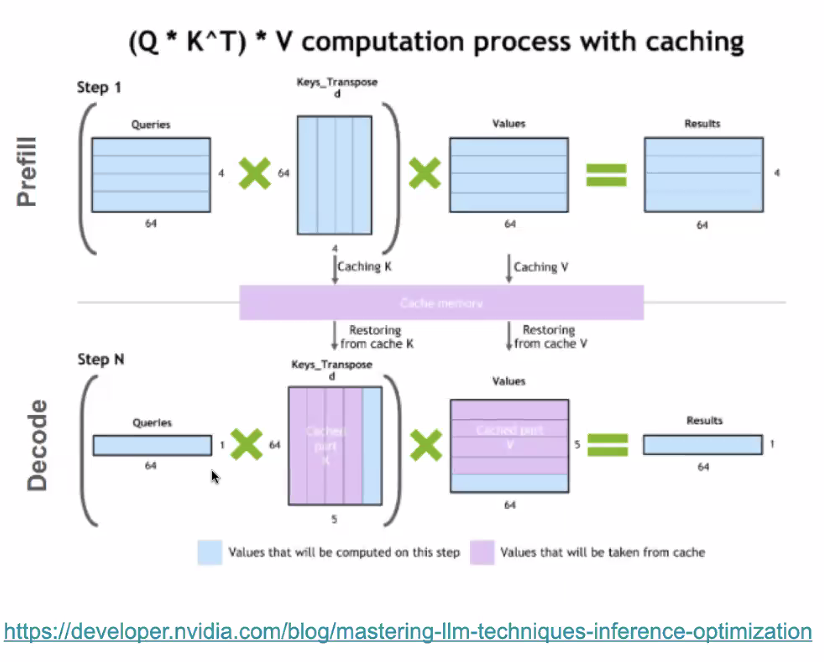
KV Cache
Stores Key (K) and Value (V) tensors computed at each transformer layer during inference to avoid recompilation
- Cache previous columns in Keys_Transposed and rows in Values
- ideally in GPU memory
- Prefill: store computed KVs of input sequence in KV cache
- Each iteration in decode phase: each new token only needs to attend to cached KV states + the latest token Question: what makes KV cache big?
- model size, bits used
- size of context
What is LLM INfra
- LLM training
- Pre training
- post training
- LLM serving
- Single GPU/CPU llm inference
- Distributed model serving
- LLMOps
- Training data collection, preperation, and synthesize
- Experiment tracking, model registry
- monitoring and logging of LLM serving
Systems Challenges That Increase Cost
- Size of LLM parameters
- consider llam2 70B ~ 130GB to store float16 parameters
- 2x A100-80GB to store, 4x+ A100-80GB to maximize throughput
- consider llam2 70B ~ 130GB to store float16 parameters
- Memory IO huge factor in latency
- for a single token, have to load 130GB to compute cores
- CPU memory IO
= 1050 GB/s - GPU memory IO ~= 2000 GB/s (A100 80GB)
- High throughputs requires many FLOPS (float-point operations per second)
- CPU - single sequence
- GPU - many sequences
Metrics in LLM serving
Performance is in the axis of “temporal” not accuracy in the context of infrastructure
- Time To First Token (TTFT): Queueing time + refill time + one token decoding: How quickly users start seeing a response, i.e., response time
- Time Per Output Token (TPOT): Time to generate each additional output token. Average TPOT x output token length is the time users see all the response after seeing the first token
- Latency: The overall request time it takes for the model to generate the full response for a user. latency = (TTFT) + (TPOT) * (the number of tokens to be generated)
- Throughput: The number of output tokens per second an inference server can generate across all users and requests
Tradeoff Questions
- In what scenarios/use cases is TTFT or TPOT more important
- TTFT - chat bots/real-time communication, user waiting for an answer
- TPOT - deep learning, research, user runs in background