What is an LLM?
- language models
- text to text generation
- that are large
- Massive number of model parameters (weights)
- Trained on huge amounts of data
How do LLMs learn?
- Via a model architecture (giant graph of interconnected nodes)
- transformer, mamba
- Model weights “trained” with massive dataset
- internet, books, code
What can LLMs do?
- Text Gen
- Translation
- Summarization
- Question Answering
- Conversational AI
What can’t LLMs do?
- Hallucination: can generate seeming correct but incorrect information
- Bias: can reflect biases present in their training data
- Real-time info: no access to data present in their training data
- Privacy: your personal info can be part of the training data
- Security: LLMs can be manipulated to give/not give certain answers
What is Infrastructure (systems)?
- the backbone that powers applications
- Traditional infra (systems)
- OS, database, networking, hardware, compiler, security, virtualization, DevOps, etc
- for data centers, cloud computing
What is LLM infra?
- LLM training
- Pre-training (foundational model training)
- Post-training (fine-tuning, RLHF)
- LLM serving
- Single-GPU/CPU LLM inference
- Distributed model serving
- LLMOps
- Training data collection, preparation, and synthesize
- Experimental tracking, model registry
- monitoring and logging of LLM serving
What is an AI Agent?
- From outside:
- autonomous entity that can operate on its own
- From inside:
- program involving model calls and tool calls
- diff from LLM: can perceive env, make decisions, take actions
- diff from AI workflows: autonomous and can morph
- The Rise and Potential of Large Language Model Based Agents: A Survey
Categories of AI Agents
- Single-agent applications
- Multi-agent systems
- LLM agents interacting with each other in a collaborative or competitive manner
- Human-Agent cooperation
- LLM agents can interact with humans, providing them with assistance and performing tasks more efficiently and safely
Agent-to-Agent (A2A) Protocol
- A protocol enabling standardized communication across agents
- Support agents using different frameworks to communicate
- A client (local) agent can discover agents by fetching “Agent Card” of available remote agents
- And then delegate a task to the chosen remote agent
- Supports streaming and asynchronous push notifications for long tasks
What are LLM Agents
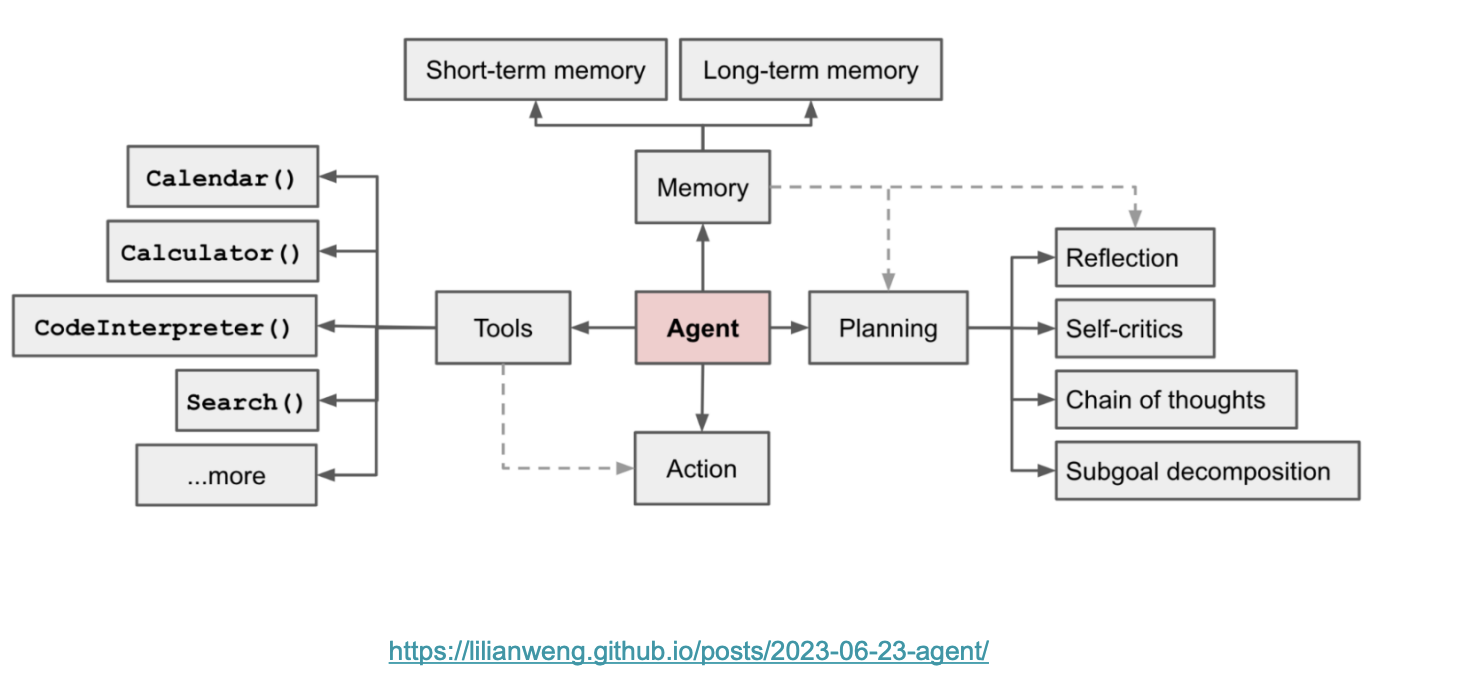
Planning
- Subgoal and decomposition: the agent breaks down large tasks into smaller, manageable subgoals, enabling efficient handling of complex tasks
- Reflection and refinement: the agent can do self-criticism and self reflection over past actions, learn from mistakes and refine them for future steps, thereby improving the quality of final results
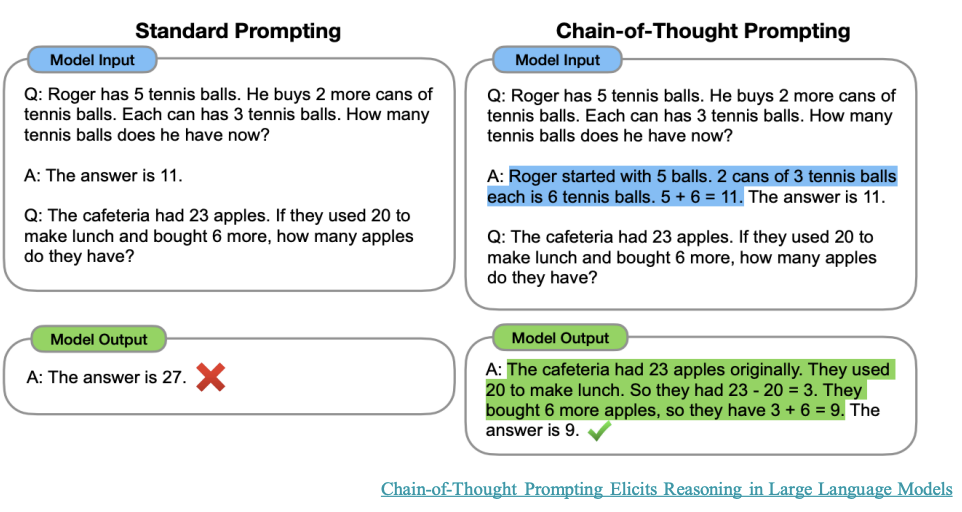
Task Decomposition: Chain of Thought (CoT)
CoT has become a standard prompting technique for enhancing model performance on complex tasks
The model is instruction to “think step by step”, utilizing more computation time to decompose hard tasks into smaller and simpler steps.
Transforms big tasks into multiple manageable tasks and shows model’s thinking process
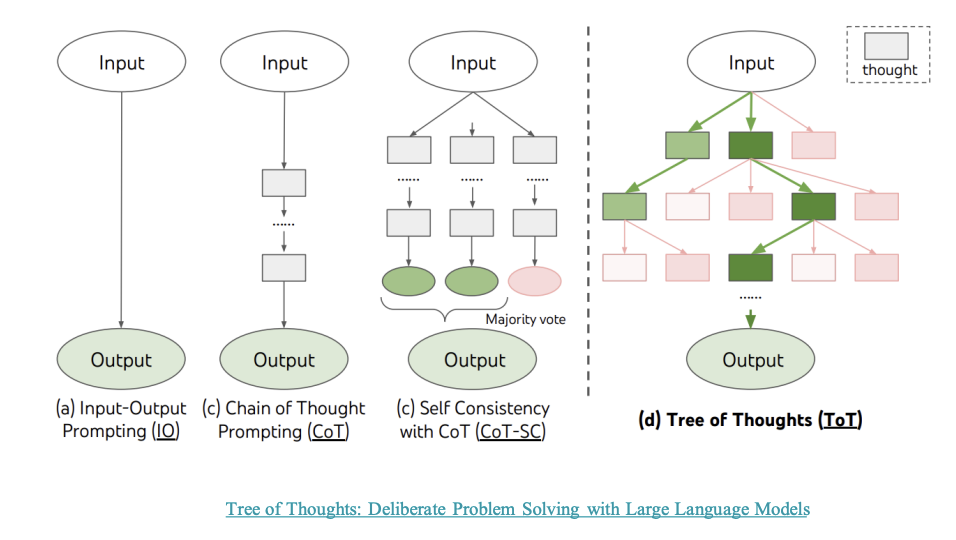
Task Decomposition: Tree of Thoughts
Tree of Thoughts extends CoT by exploring multiple reasoning possibilities at each step, creating a tree structure.
Design choices involved:
- DFS or BFS search
- how each state is evaluated by a classifier (via prompt or majority vote)
Self-Reflection: ReAct
Adding reasoning and acting within the LLM by extending the action space to be a combination of task-specific discrete actions and the language space
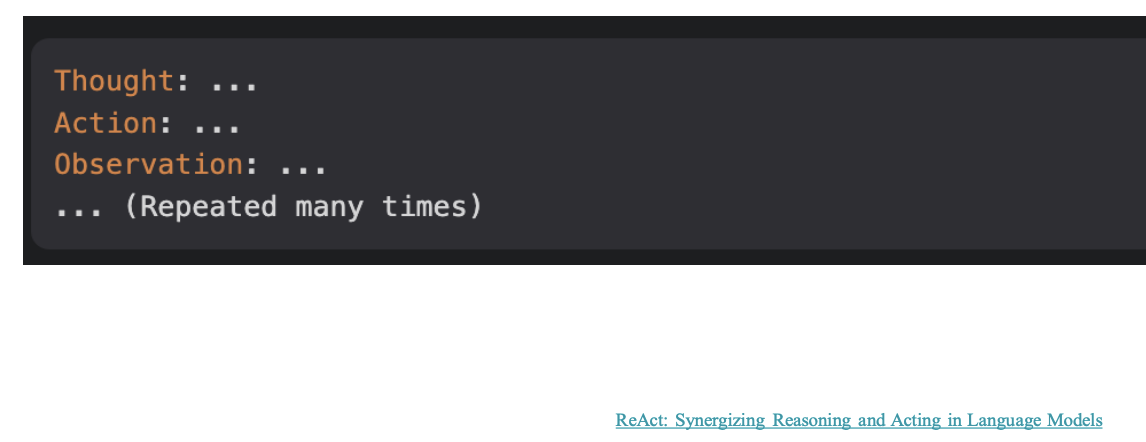 Example format of the explicit steps for an LLM to think
Example format of the explicit steps for an LLM to think
 Example of ReAct differences
Example of ReAct differences
Memory
- Sensory Memory: learning embedding representation for raw inputs, including text, image or other modalities (Vision encoder/ Speech encoder)
- Short-term memory: all the in-context learning is utilizing short-term memory of the model to learn. Short and finite, restricted by window length of transformer (prompt engineering)
- Long-term memory: this provides the agent with the capability to retain and recall (infinite) information over extended periods, often by leveraging an external vector store and fast retrieval. External vector store for agent to query (RAGs)
Agent Memory Types
- Semantic: facts and general knowledge
- Episodic: past requests/actions
- Procedural: skills defined in programs or fine-tuned
- Short-term: context within a request execution
RAG
Why RAG?
- LLM’s knowledge is static at time of training
- No proprietary info
- Non-attributable: difficult to trace the source of an LLM generation
- Hallucination: easier to hallucinate when asked about knowledge outside of training set
- LLMs are large and expensive to train and run, put proprietary info out of model Components:
- Data source
- preprocessed by chunking and embedding into vector DB
- Retrieve
- convert query into embedding
- Augment and generate
- combine retrieved chunks with existing context
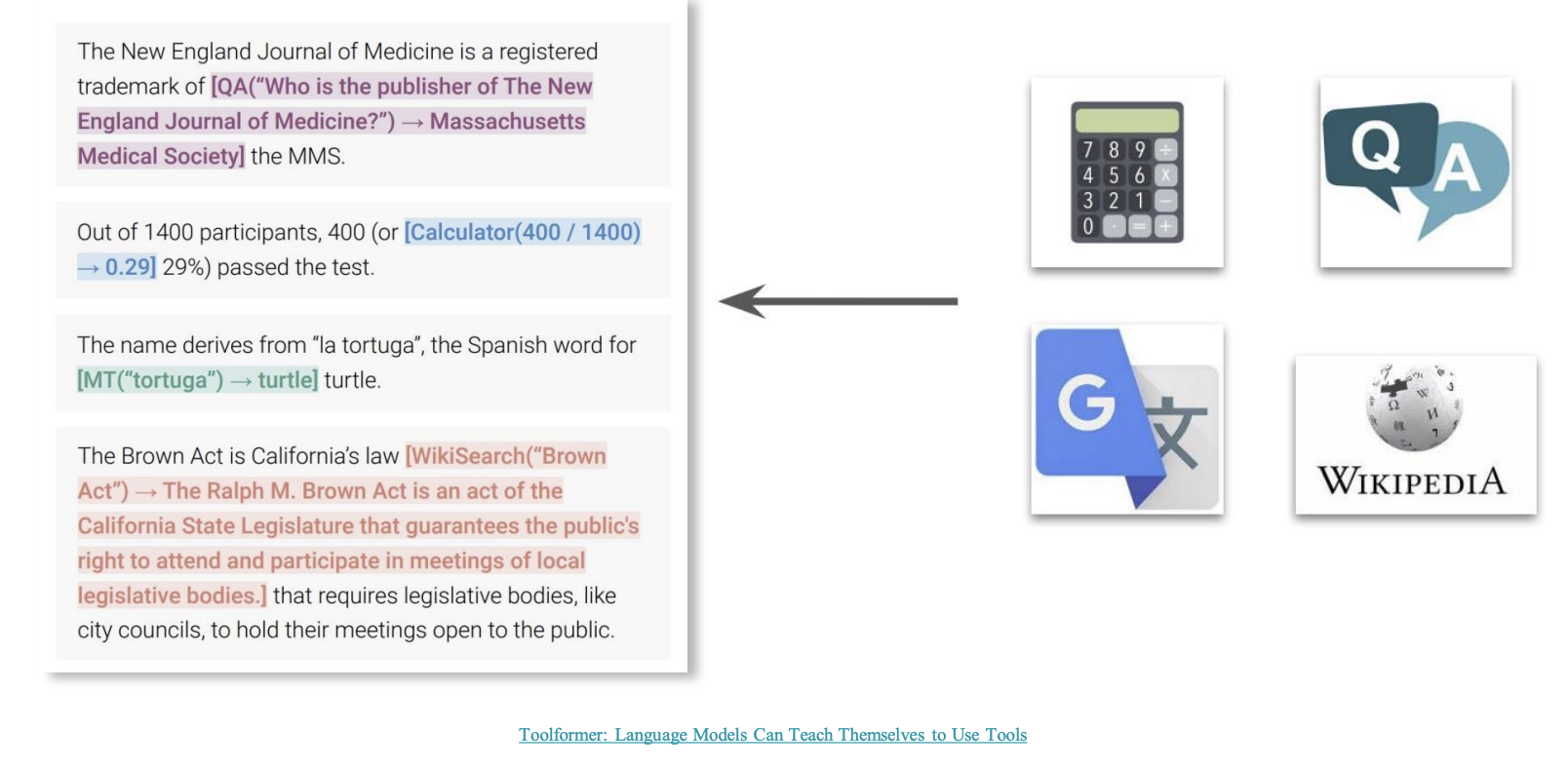
Tool Use
Agent learns to call external APIs for extra information missing from model weights
- eg:
- web search + crawling
- browser
- social media, email hooks
- code + CLI execution
What make LLM agents stand out?
- Language Mastery: comprehend and produce language
- Decision-making: LLMs are equipped to reason and decide
- Flexibility: adaptability ensures they can be molded for diverse applications
- Collaborative Interactions: collaborate with humans or other agents → multifaceted interactions Examples
- HuggingGPT - LLM + APIs
- LLM mapped to hugging face models as tools
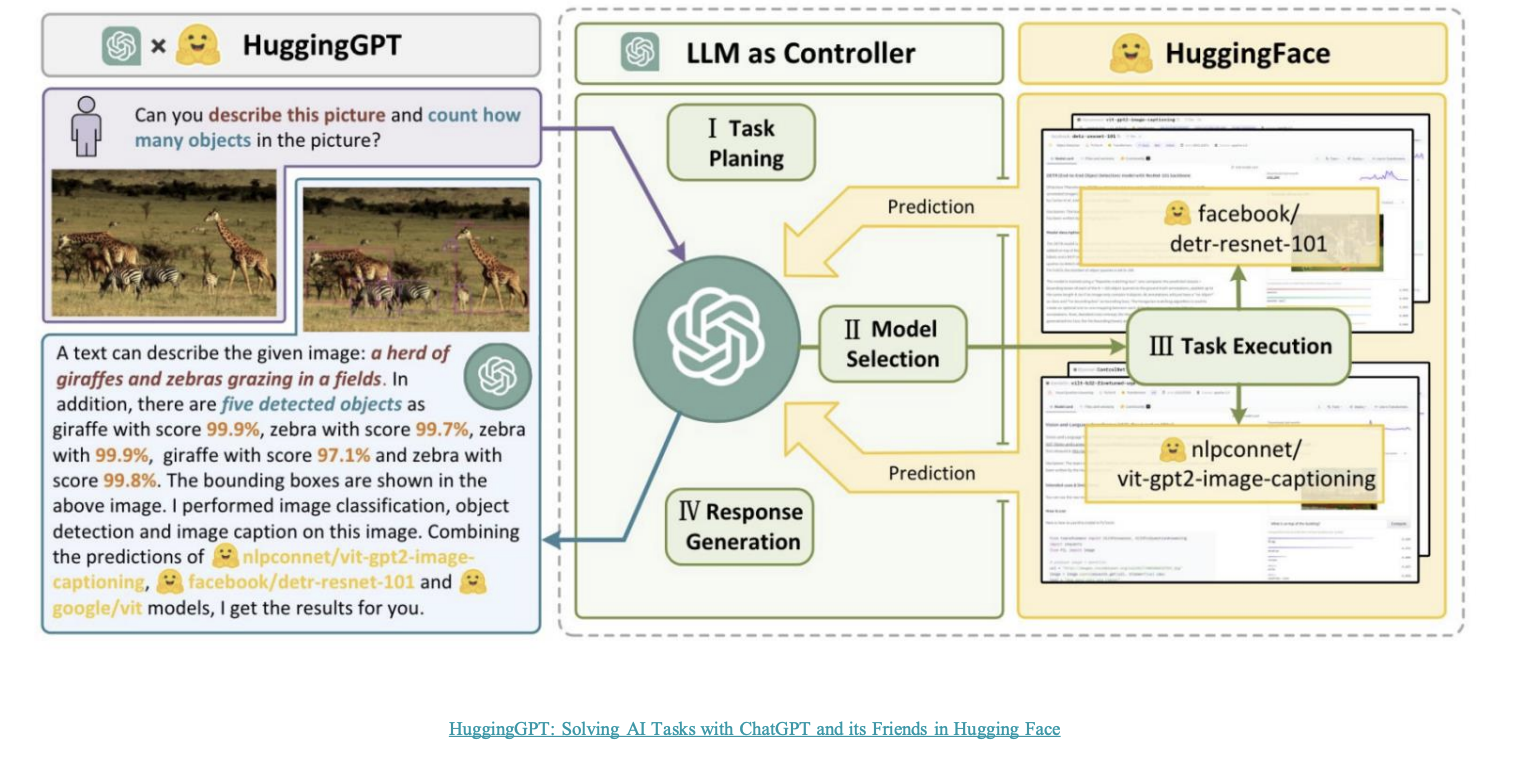
- LLM mapped to hugging face models as tools
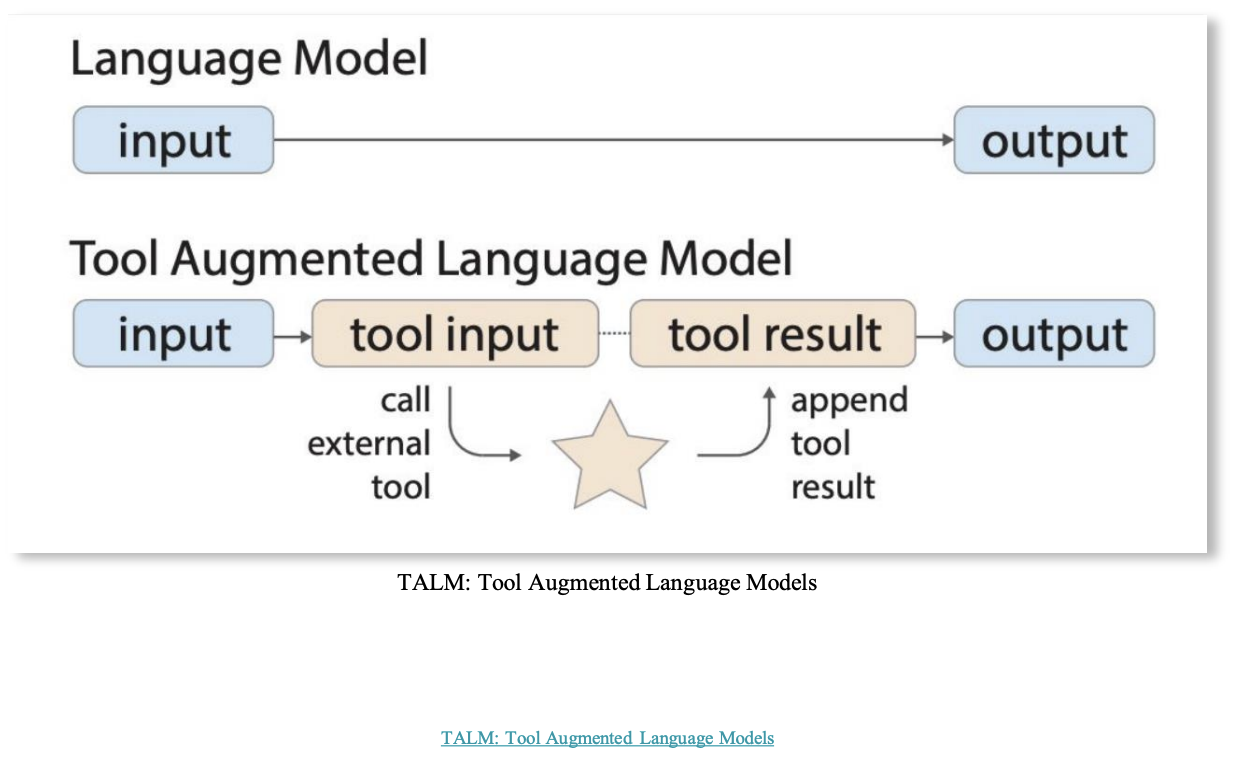
- TALM (tool augmented language model)
- Toolformer