What is ILP
The characteristic of a program that certain instructions are independent and can potentially be executed in parallel
- Any mechanism that creates, identifies, or exploits the independence of instructions, allowing them to be executed in parallel
Where do we find ILP?
- in basic blocks?
- 15-20% of (dynamic) instructions are branches in typical code
- virtually none
- Across basic blocks?
- Lots, further we go from two instruction, the more likely to find parallel instructions,
- across branches, across control flow
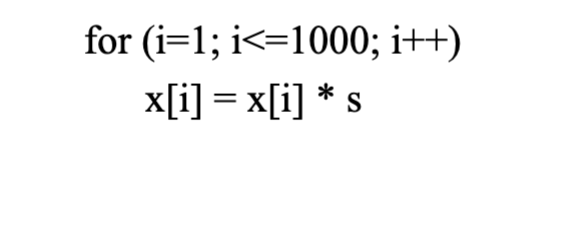
How do we expose ILP?
- by moving instruction arounds
- How?
- software:
- instruction scheduling (changes ILP within a basic block)
- loop unrolling (allows ILP across iterations by putting instructions from multiple iterations in the same basic block)
- expand loop (eg by 2 iterations) and combine instructions that can be combined
- eg. two addi that other instructions don’t depend on
- expand loop (eg by 2 iterations) and combine instructions that can be combined
- Unroll
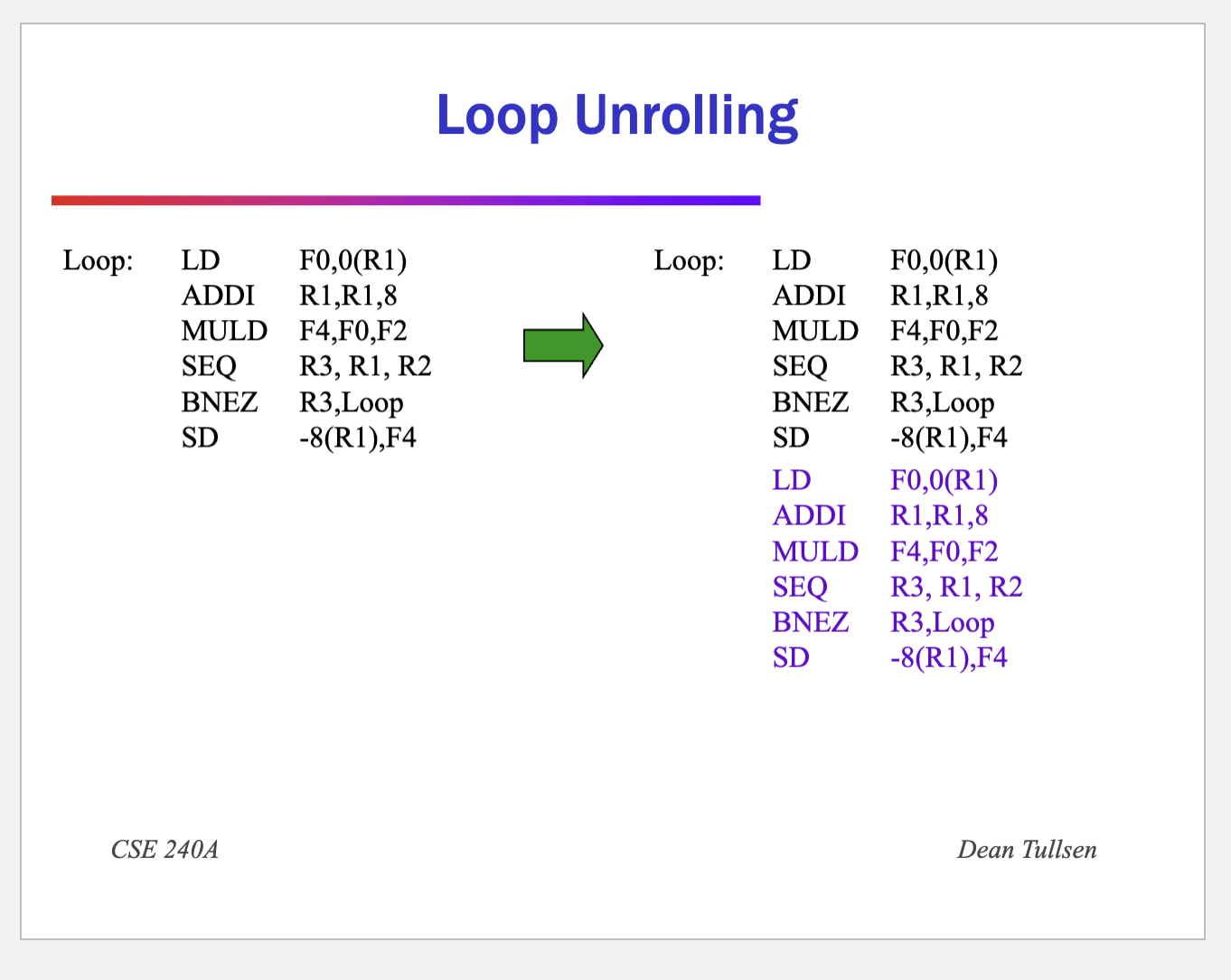
- software:
- Remove extra instructions
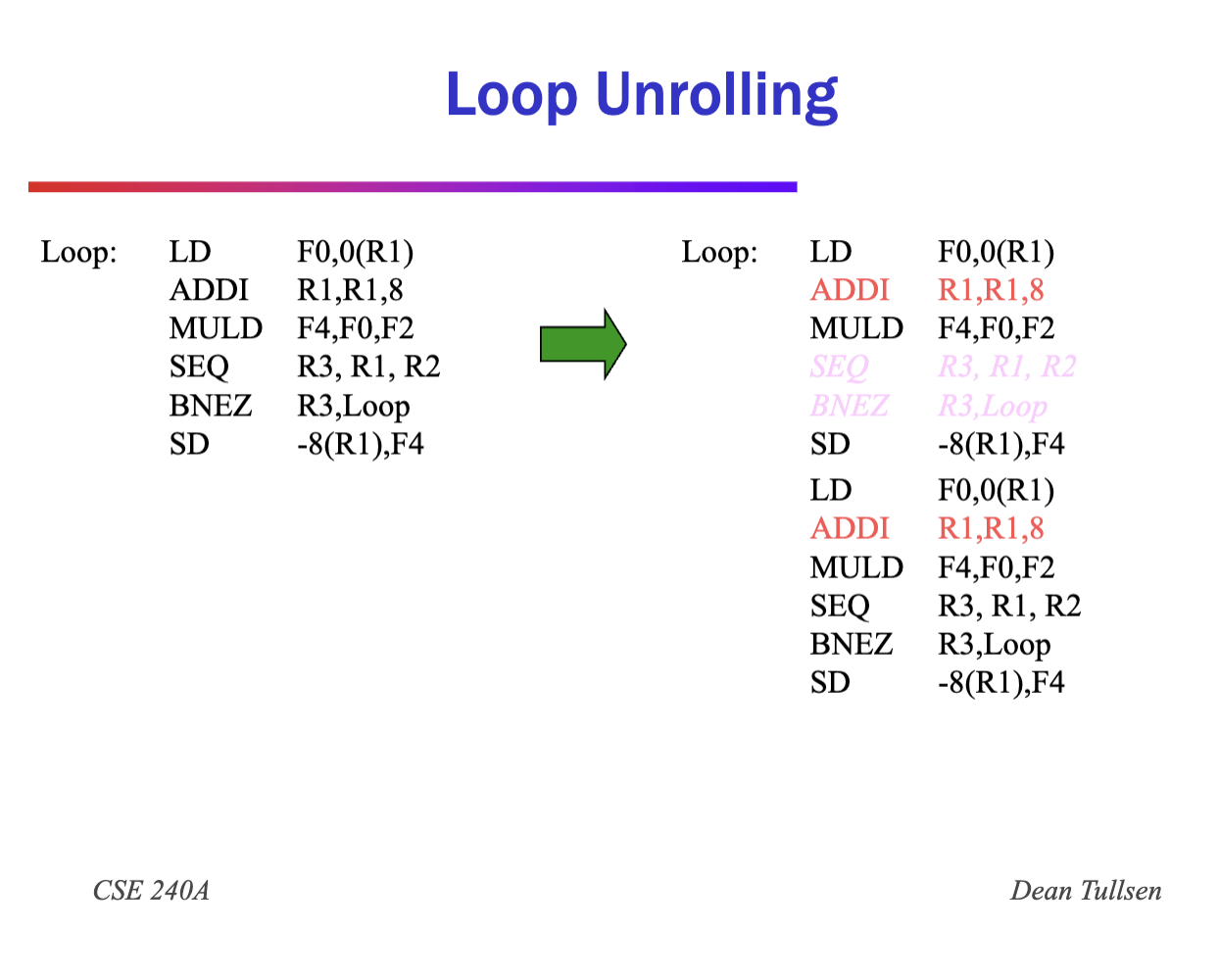
- Combine
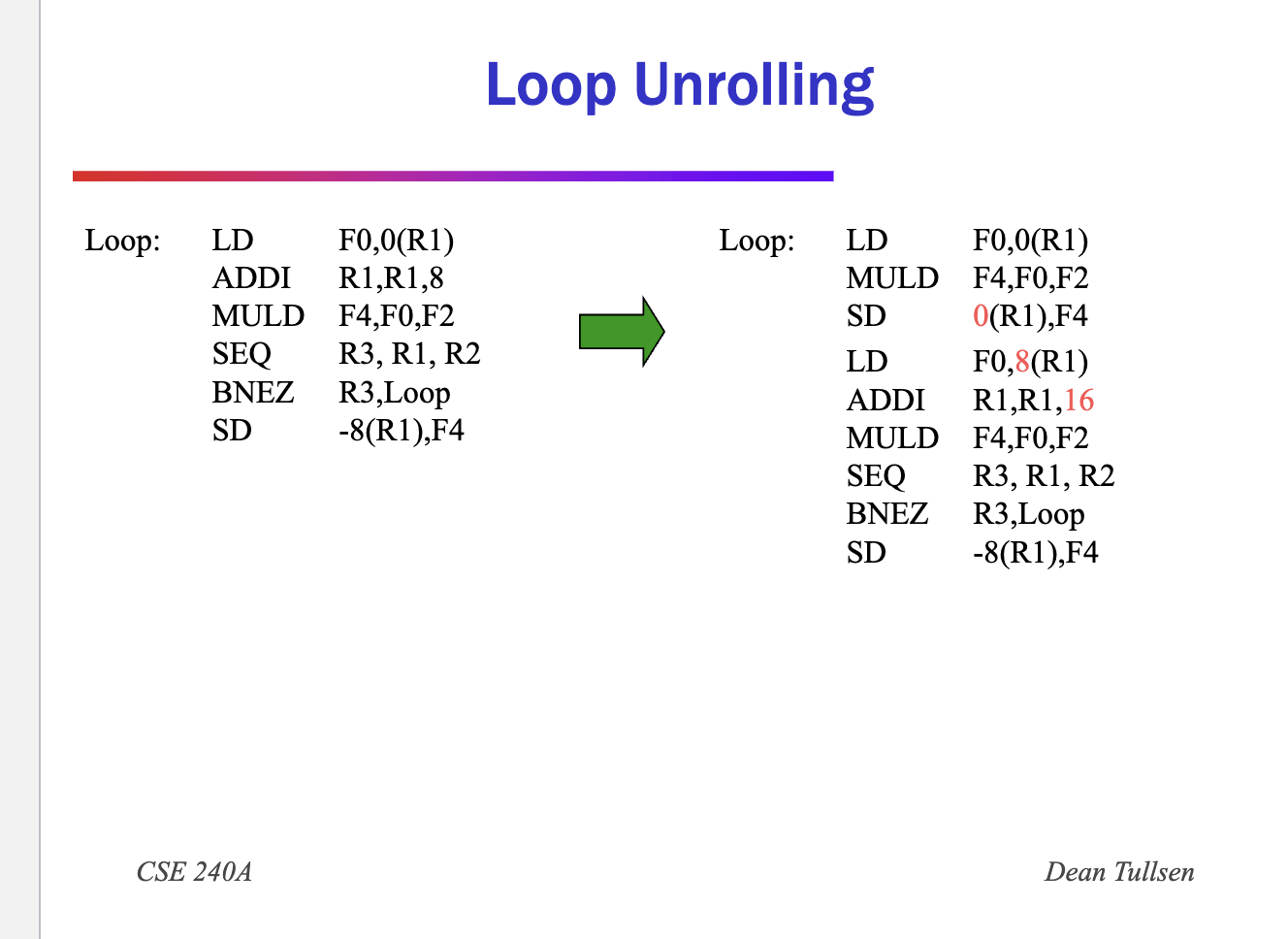
- Register rename to prevent stalls

- reorder for pipelining
 - Others (trace scheduling, software pipelining)
- Others (trace scheduling, software pipelining)
- hardware:
Compiler Perspectives on Code movement
- Remember: dependencies are a property of code, whether or not it is a HW hazard depends on the given pipeline
- Compiler must respect(True) Data dependencies (RAW)
- easy to determine for registers (fixed names)
- hard for memory:
- Does 100(R4) = 20(R6)
- From different loop iteration, does 20(R6) = 20(R6)?
- False dependences (WAR and WAW) can sometimes be overcome
- Compilers must preserve control dependence
- an instruction that is control dependent on a branch cannot be moved before the branch so that its execution is no longer controlled by the branch
- an instruction that is not control dependent on a branch cannot be moved to after the branch so that its execution is controlled by the branch
- Control dependencies relaxed to get parallelism; as long as we get same effect if preserve order of exceptions and data flow
Code Motion
Can be done in SW or HW:
- Why SW?
- flexibility across various HW setups, defined primitives
- Why HW?
- more flexibility in branch prediction decisions Want following capabilities:
- ability to move instructions across branches
- ability to overcome (or ignore) false dependencies
- both easier in hardware
HW Schemes: Instruction Parallelism
Why in HW at run time?
- works when can’t know dependence until run time
- variable latency
- control dependent data dependence
- can schedule differently every time through the code
- compiler simpler
- code for one machine runs well on another
- Key idea: Allow instructions behind stall to proceed

First HW ILP Technique: Out-of-order Issue/Dynamic Scheduling
Problem:
- need to get stalled instructions out of ID stage, so that subsequent instructions can begin execution
- Must separate detection of structural hazards from detection of data hazards
- Must split ID operation into two:
- Dispatch (decode, check for structural hazards)
- Read operands (read operands when NO DATA HAZARDS)
- Otherwise, one stalled (for data) instruction would cause all other to back up behind the ID stage
- Must be able to dispatch even when a data hazard exists
- instructions dispatch in-order, but proceed to EX (issue) out-of-order
- terminology highly inconsistent. Common is dispatch→issue
- dispatch - inorder to out of order
- issue - send it to execute (which is out-of-order)
- Does out-of-order execution in the hardware make compilation harder or easier?
- Does out-of-order execution in the hardware make exception handling harder or easier?
- straightforward, need more HW to support exceptions but same HW can be used to reverse back the ordering of instructions for exception handling
- TODO: id exceptions and HW components
Key Points
- You can find, create, and exploit Instruction Level Parallelism in SW or HW
- Loop level parallelism is usually easiest to see
- Dependencies exist in a program, and become hazards if HW cannot resolve
- SW dependencies/compiler sophistication determine if compiler can/should unroll loops
- SW code motion is limited by lack of runtime knowledge of dependencies (esp. memory), latencies (esp. memory), and control flow.
Dynamic Scheduling

- If ID stage remains in-order, then need a way for instructions to leave ID whether or not operands ready
- This requires storage for instructions waiting for operands
- We also need a way to signal when missing operands are ready
- And we need a way to put things back in order at the end of pipeline (exceptions, branch recovery, etc)
Somehow create some storage between ID and EX stages
History
First machine CDC 6600 scoreboard
- Instruction storage added to each functional execution unit
- Instructions issue to FU when no structural hazards, begin execution when dependences satisfied. Thus, instructions issued to different FUs can execute out of order.
- “scoreboard” tracks RAW, WAR, WAW hazards, tells each instruction when to proceed.
- No forwarding
- No register renaming Tomasulo (IBM 360/91) or reservation stations instruction Queue (MIPS R10000, Alpha 21261)
Tomasulo Algorithm
- Goal: High performance without special compilers
- Differences between IBM 360 and CDC 6600 ISA
- IBM has only 2 register specifiers/instr vs 3 in CDC 6600
- IBM has 4 FP registers vs 8 in CDC 6600
- implications?
- false dependencies all over the place
- Features:
- Put instructions in reservation stations - control and inst/operand buffers
- Register names in instructions replaced by pointers to reservation station buffer
- Tomasulo ⇒ reservations stations as operand storage
- Reservation stations replace registers names
- HW renaming of registers to avoid WAR, WAW hazards
- Tomasulo ⇒ each register read as soon as available. When possible, they are read at dispatch. If not, grabbed off the… TODO
- Common Data Bus broadcasts results to all FUs
- RS’s (FU’s), register file, etc responsible for collecting own data off CDB
- Load and Store queues treated as FUs as well