YAGS Branch Prediction Scheme A. N. Eden and T. Mudge
What’s the big problem they are trying to solve?
- conflicts with predictions with limited hash addrs What does aliasing do to the predictor?
- muddle the predictor because multiple branches can be aliased to a predictor that is vastly different
- Neutral → when they both match
- Destructive → when they don’t
Aliasing
- Neutral
- Destructive
- What are two obvious ways, then to reduce the impact of aliasing
- mapping two branches that match to same predictor
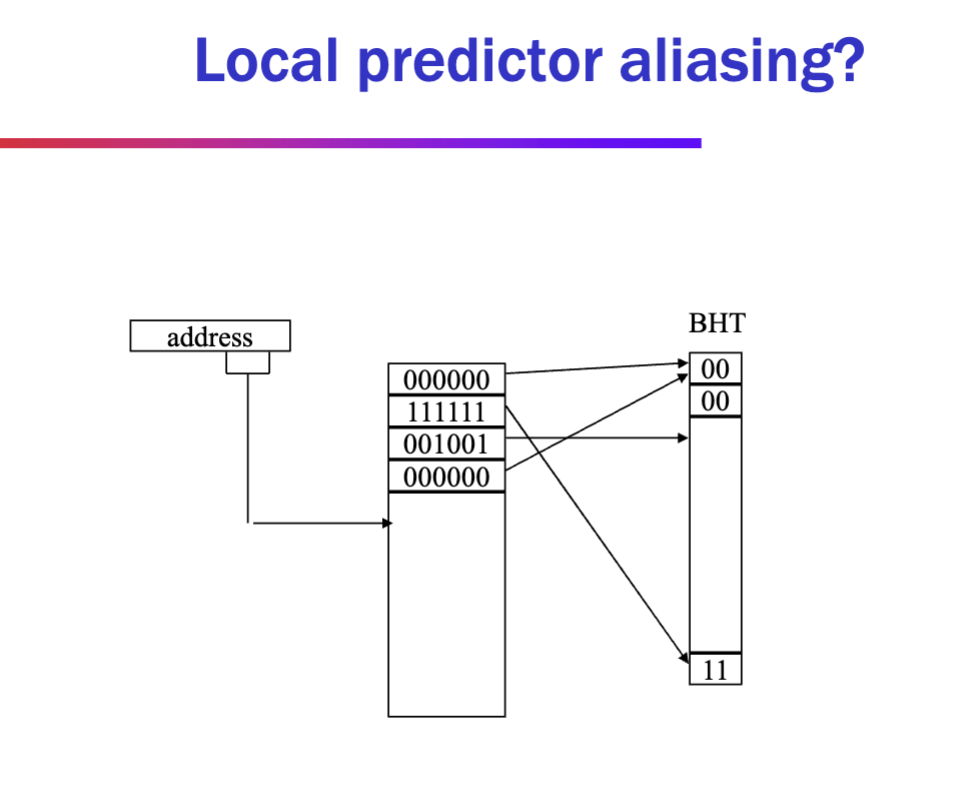
- aliasing from lower bits of addr to history - TODO?
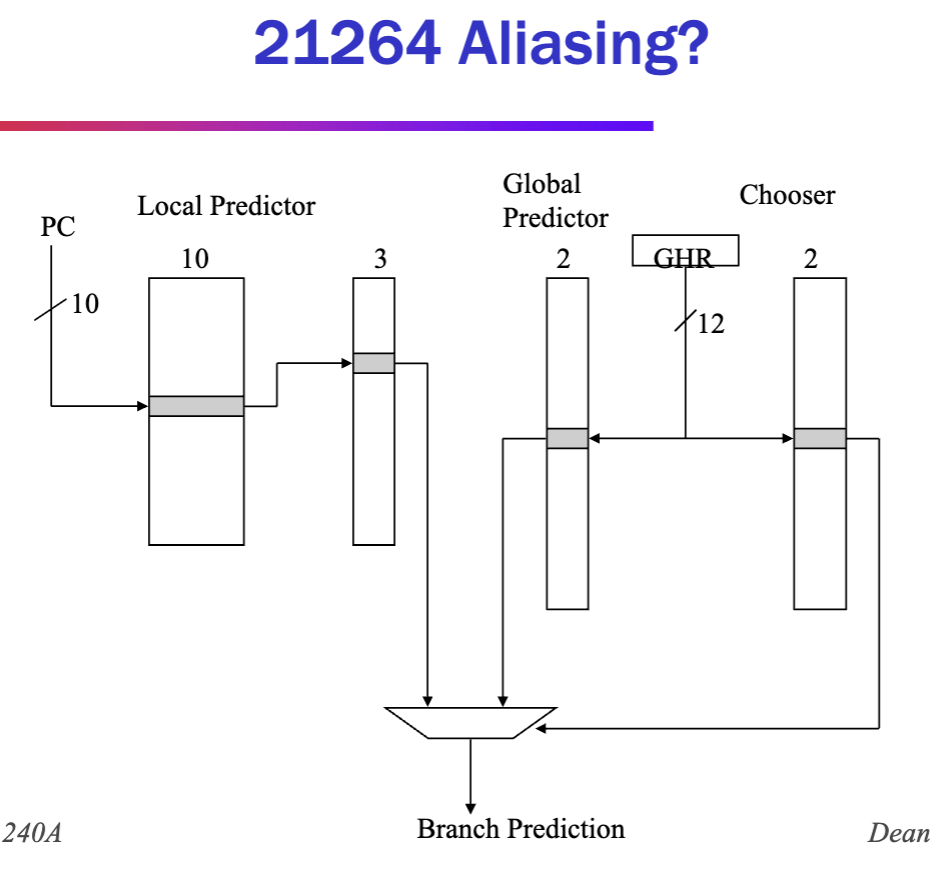
- Intentional aliasing from history to BHT
Anti-Aliasing Predictors
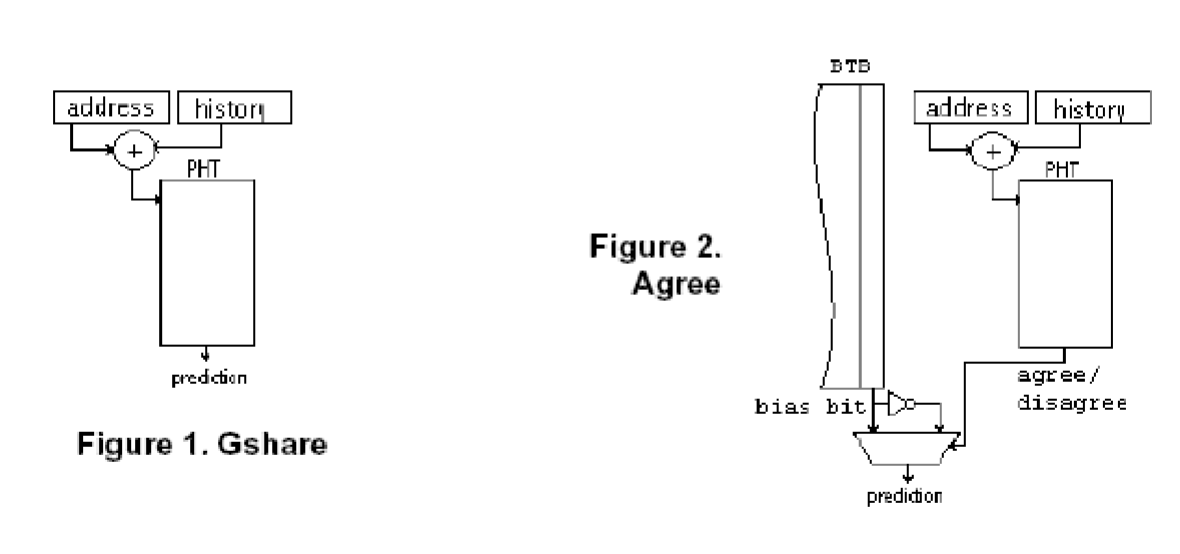
- Gshare is bad for aliasing. When addr XOR history for key, completely random → values become noisy
- Agree predictor
- assigns a biasing bit to each branch in Branch Target Buffer (BTB). PHT info is changed to “agree” or “disagree” with prediction of the biasing bit. Both need to be in the agree state to take. or both in disagree to not take
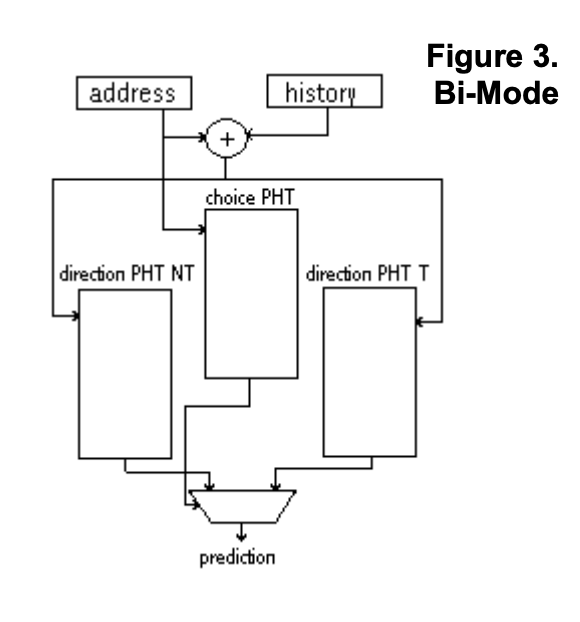
Bi-Mode Predictor
Produce a predictor taken or not taken… TODO
Skew
Distributes aliasing to reduce it’s effects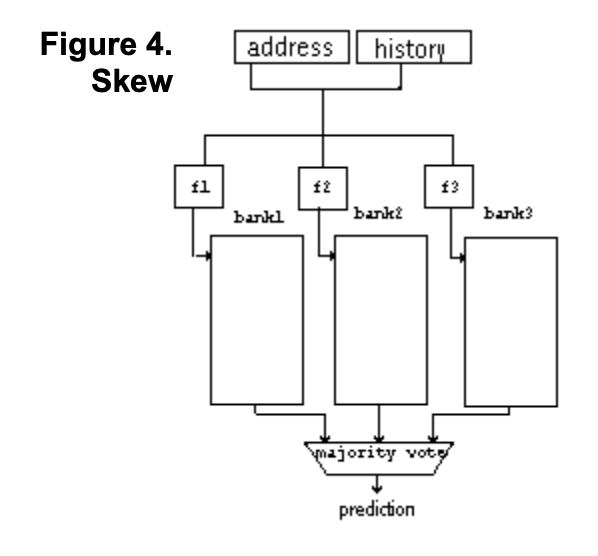
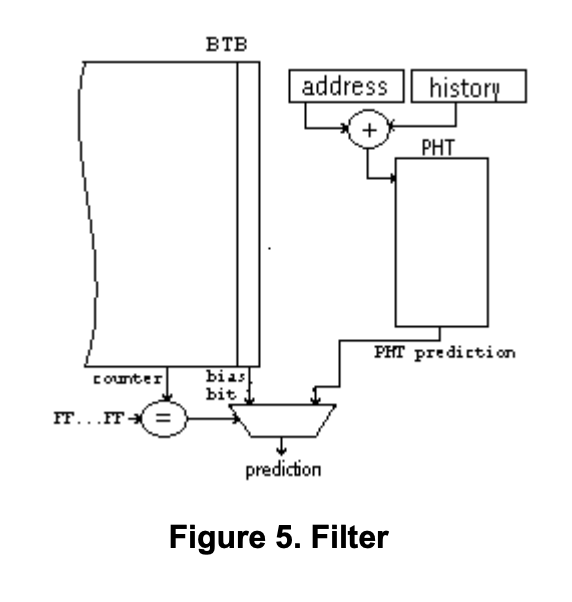
Filter
Don’t even use BTB for easy branches only use it for hard branches
YAGs
Enumerate Exceptions? TODO Bimodal with fewer hits
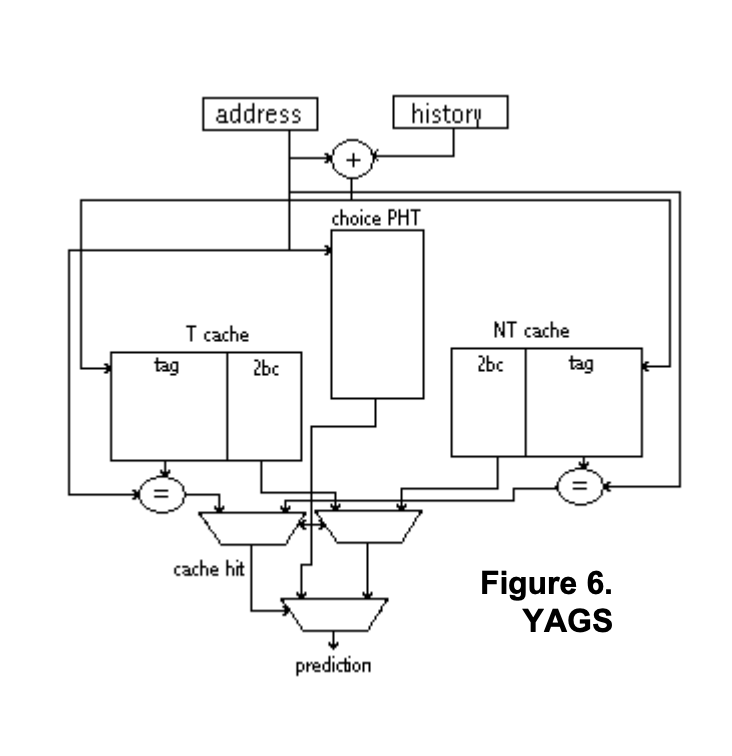
- YAGS add tags to PHT (pattern history table)
- tags are 6-8 bits that contain the least significant bits of the branch address and virtually eliminate aliasing between two consecutive branch
Isn’t branch prediction really a machine learning problem
Probably Only one class of ML-based predicts has really made an impact
Perceptron Branch Predictor (I)
- Idea: use a perceptron to leanr the correlation between branch history register bits and branch outcomes
- A perceptron learns a target Boolean function of N inputs
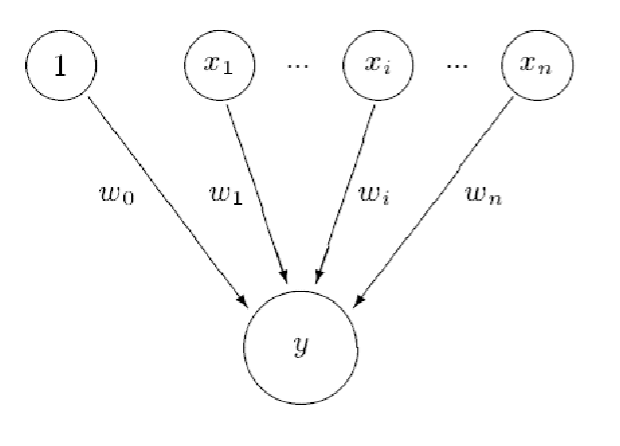
- Each branch associated with a perceptron
- Perceptron contains a set of weights wi
- Each weight corresponds to a bit in the GHR
- How much the bit is correlated with the direction of the branch
- Positive correlation: large + weight
- Negative correlation: large - weight
Prediction: - Express GHR bits as 1 (T) and -1 (NT)
- Take dot product of GHR and weights
- If output > 0, predict taken
- Perceptron contains a set of weights wi
- Advantages:
- more sophisticated learning mechanism → better accuracy
- Disadvantages
- hard to implement
- can learn only linearly-separable functions
What is ILP
The characteristic of a program that certain instructions are independent and can potentially be executed in parallel
- Any mechanism that creates, identifies, or exploits the independence of instructions, allowing them to be executed in parallel
Where do we find ILP?
- in basic blocks?
- 15-20% of (dynamic) instructions are branches in typical code
- virtually none
- Across basic blocks?
- Lots, further we go from two instruction, the more likely to find parallel instructions,
- across branches, across control flow
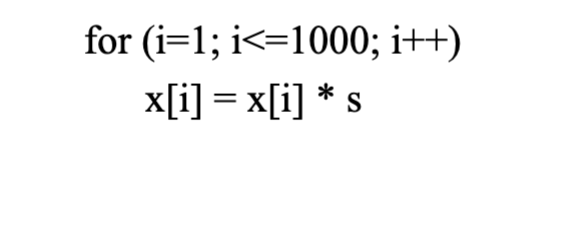
How do we expose ILP?
- by moving instruction arounds
- How?
- software:
- hardware: