Looking for Instruction Level Parallelism (ILP)
- Identify and exploit ILP - instructions that can potentially be executed at the same time
- Branches are 15-20% of instructions
- Implications?
- 20% of control hazards
- …
- Implications?
- Can only keep pipeline full if we can consistently keep fetching well past unresolved branches
- Can only exploit high level of parallelism if we consistently have multiple basic blocks in the processor at once
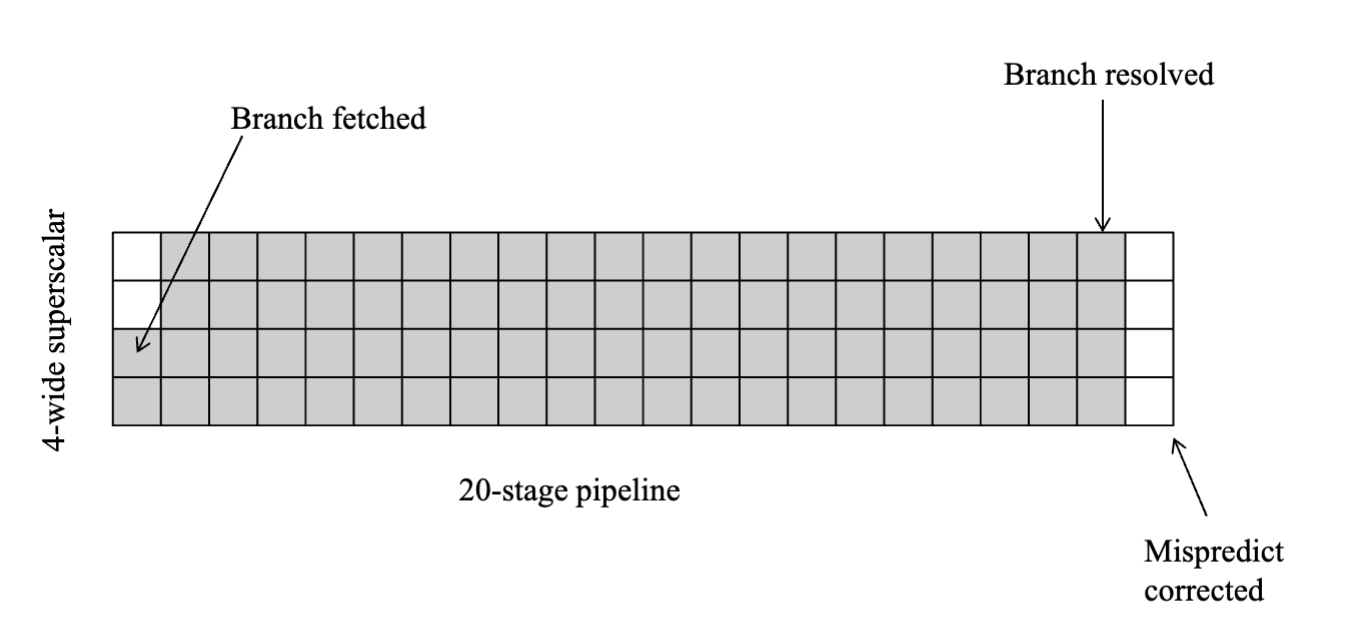
Importance of Branch Prediction
Timeline:
- MIPs scalar, branch hazard of 1 cycle, 1 instruction issued per cycle
- delayed branch
- next gen - 2-3 cycle hazard, 1-2 instructions insued per cycle
- cost of branch misprediction goes up
- even worse - lots of instructions missed
CPI?
- Assume (for simplicity) a scalar pipeline, with a branch hazard (distance from branch resolve/ex to fetch) of 10 cycles.
- What is the best case CPI if the branch mispredict rate is 15%, assuming 20% of instructions are branches?
- Note 1 – it’s worse on a superscalar pipeline, and potentially even worse on out-of-order
- Note 2 – modern pipelines can have 500+ instructions after a branch in the pipeline!
Branch Prediction
- Easiest (static prediction)
- always not taken, always taken
- forward not taken, backward always taken
- compiler predicted (branch likely, branch not likely)
- What’s the problem with static prediction?
- if you don’t have a branch that is really biased it’s not going to do well
- it’s performance is capped by the max of taken or not taken count
- Dynamic branch prediction
- next easiest (1-bit dynamic)
- remember last taken/not taken per branch (1 bit)
- per branch approximated
- per 1 cache line
- use part of address
- what happens on a loop?
 Note: mispredict at N and the T after it. 60% predicts correctly, 1st is trivial case
Note: mispredict at N and the T after it. 60% predicts correctly, 1st is trivial case
- 2-bit branch prediction
- Often referred to as a “saturating counter”
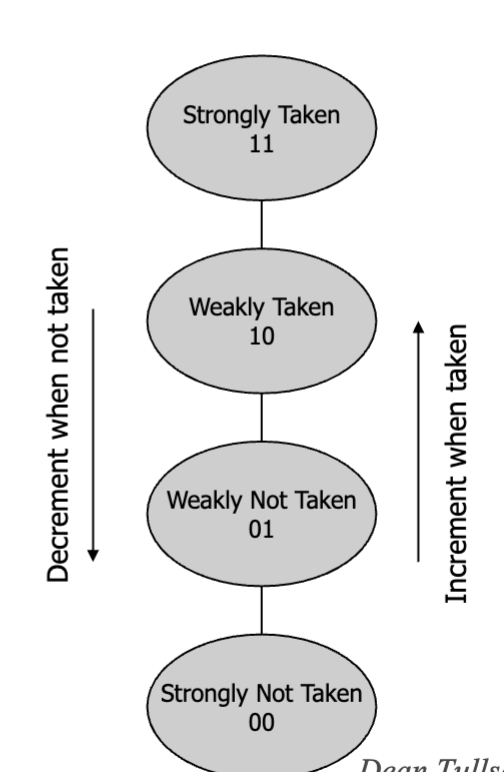
- Provides some hysteresis, doesn’t over-react to one miss

- Now 80% correct, miss on N
- Note: Branch predictor doesn’t reset
- next easiest (1-bit dynamic)
Bimodal Predictor
- limited size
- 2 bits by N (eg. 4k)
- uses low bits of branch address to choose entry, the volatile bits of nearby addresses
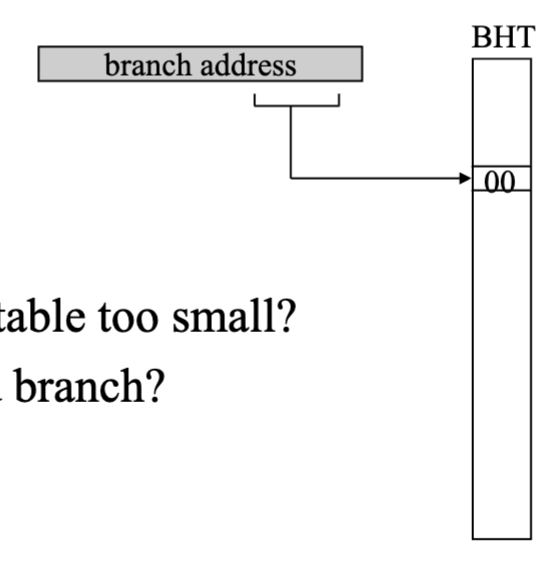
- What happens when the table too small?
- branch aliasing (conflicting keys with different branches but not enough space)
- What about even/odd branch?

- 0% if start at weakly Not Taken, bouncing back and forth with neighboring states
Patterns
Can we do better than just history in dynamic branch prediction
- We can look at patterns (local predictor) for a particular branch
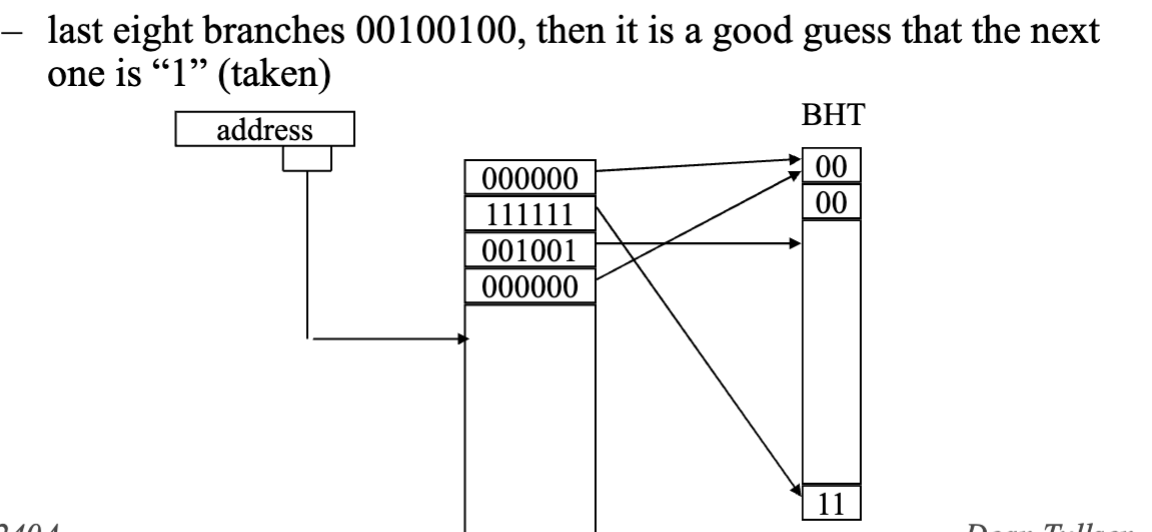
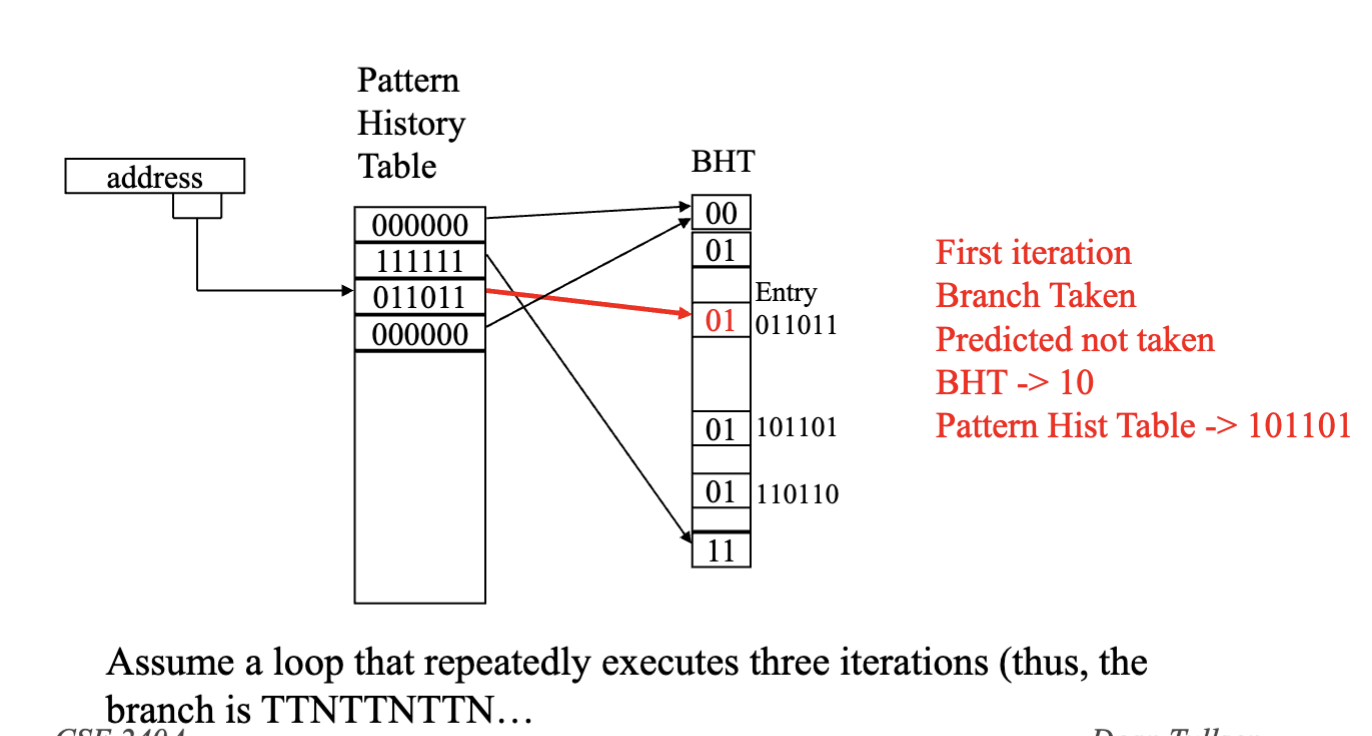
- Pattern History table 1 = branch taken, 0 = branch NOT taken
- earliest = left, latest = right, think of it like a queue
- right most bit value determines whether to take or not take
- depending on the correctness change BHT in response. TODO review
Correlating Branch Predictors
Can we do even better?!
Correlating Branch Predictors also look at other branches for clues
- Often use two indices
- Global history register (GHR) → history of last m branches (e.g. 0100011)
- branch address
- virtually every important modern predictor has a GHR (or other globabl path history) in it somewhere
- Global history register (GHR) → history of last m branches (e.g. 0100011)
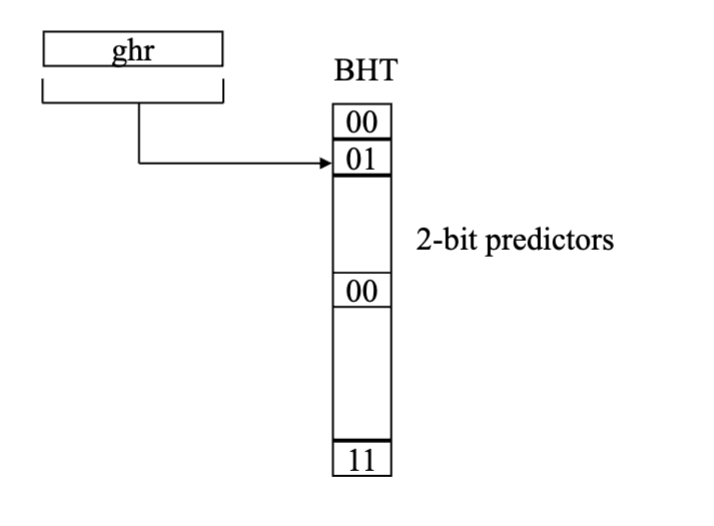
Global history register is a shift register that records the last n conditional branches (of any address) encountered by the processor
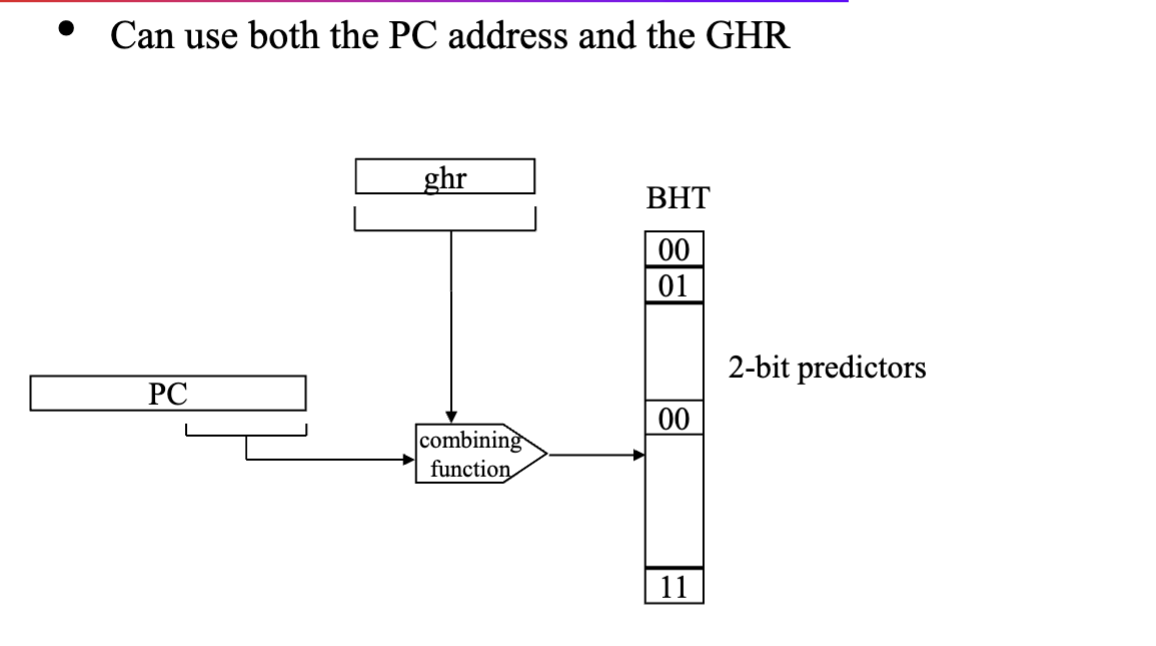 If the combining function is xor, this is called the gshare predictor
If the combining function is xor, this is called the gshare predictor
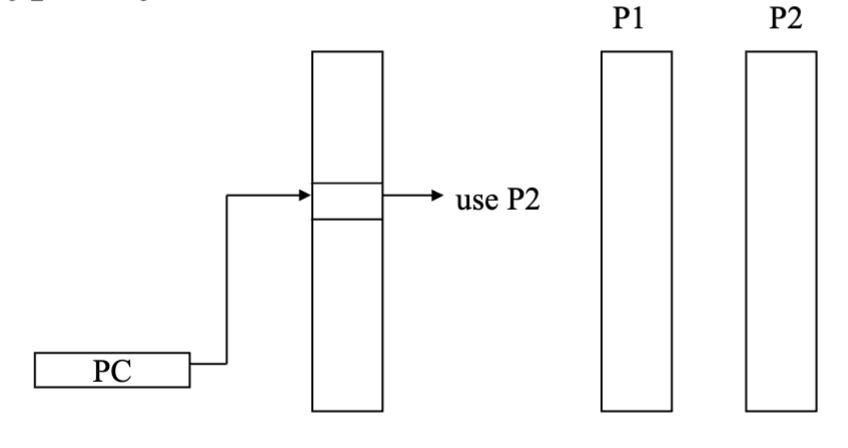
Combining branch predictors / tournament predictors
Use multiple schemes and a voter to decide which one typically does better for that branch
How does prediction work?
- In what stage do we need to do the prediction to avoid any control hazards on a correct prediction?
- Prediction in the instruction fetch stage for next cycle
- But we don’t know if the instruction is a branch or not yet
- Don’t know the target address either to move to if branch
- Prediction in the instruction fetch stage for next cycle
- A taken/not taken prediction only helps us if..?
- correct
Branch Target Buffers
- predict the location of branches in the instruction stream
- predict the destination of branches
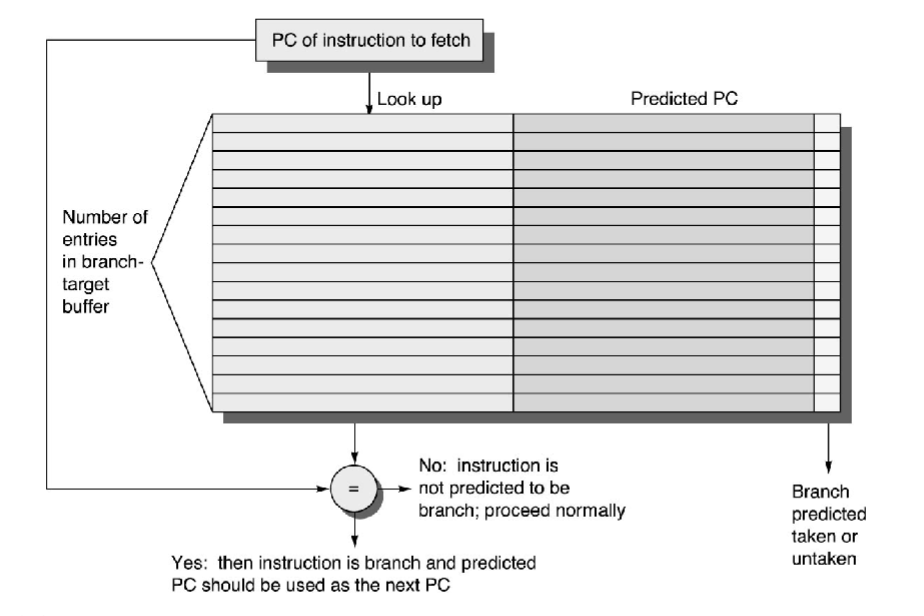
- How?
- use PC (all bits) for lookup
- match implies this is a branch
- if match and predict bits → taken, set PC to predicted PC
- if branch predict wrong, must recover (same as branch hazards we’ve already seen)
- but what about dynamically scheduled (out of order) processor??
- if decode indicates branch when no BTB match, two choices:
- look up prediction now and act on it
- just predict not taken
- when branch resolved, update BTB (at least prediction bits, maybe more) Performance
- use PC (all bits) for lookup
- Two things can go wrong
- didn’t predict the presence of branch (misfetch)
- mispredicted a branch (mispredict)
- Can use both BTB and branch predictor
- have no prediction bits in BTB (why is this a good idea?)
- presence of PC in BTB indicates a lookup in branch predictor to predict whether the branch will go to destination address in BTB
- Modern processors always use both
What about indirect jumps/returns?
- Branch predictor does really well with conditional jumps
- BTB does really well with unconditional jumps (jump, jal, etc)
- Indirect jumps often jump to different destinations, even from the same instruction.
- Indirect jumps often used for returns
- Sometimes for case or switch
- Heavily used in object-oriented languages
- Return easily handled by a stack
- jal → push PC+4
- return → predict jump to address on top of stack, pop stack
- Most processors include a hardware return address stack (RAS), used only for prediction
- procedure calls are typically predicable unless used in weird ways
Summary BTB
- Branch Target Buffer allows us to pedict the existence of branches in the fetch stage (so we know to predict condition) and also predict the target
- The BTB cannot predict the destination of branches that have multiple targets. For that we need another predictor the indirect branch predictor
Tage Predictor
Different branches require different amount of history
- For branches that are not hard to predict, more history = more noise
- For really hard branches can benefit from really long history
- problem could lead to huge tables
- so only use long history for those who need it and less history for those who don’t
Path History Register
- Captures global history (like GHR)
- unlike GHR, updated only on taken branches
- For each taken branch, shift PHR, then xor in some bits of branch PC and some bits of branch target.
- For largest Intel predictors, they shift 2, use up to 16 bits of branch PC, up to 6 bits of target, and record up to 388 bits (194 branches) of history!
- Both Intel and AMD use PHR. It looks like AMD also uses a small GHR as well, that gets hashed in.
Branch Prediction Key Points
- Significant improvement in predictor accuracy overshadowed by increases in pipeline depth and superscalar width
- 2-bit predictors capture tendencies well
- correlating predictors improve accuracy, particularly when combined with 2-bit predictors
- accurate branch prediction does no good if we don’t know there was a branch to predict
- BTB identifies branches in (or before) IF stage
- BTB combined with branch prediction table identifies branches to predict and predicts them well
- Modern codes can create significant aliasing in branch predictor tables