Background
Everything in a processor happens in units called “cycles”
Now we’re going to define a bunch of machines based on what actually goes on during a cycle
Non-pipelined machines, throughput and latency
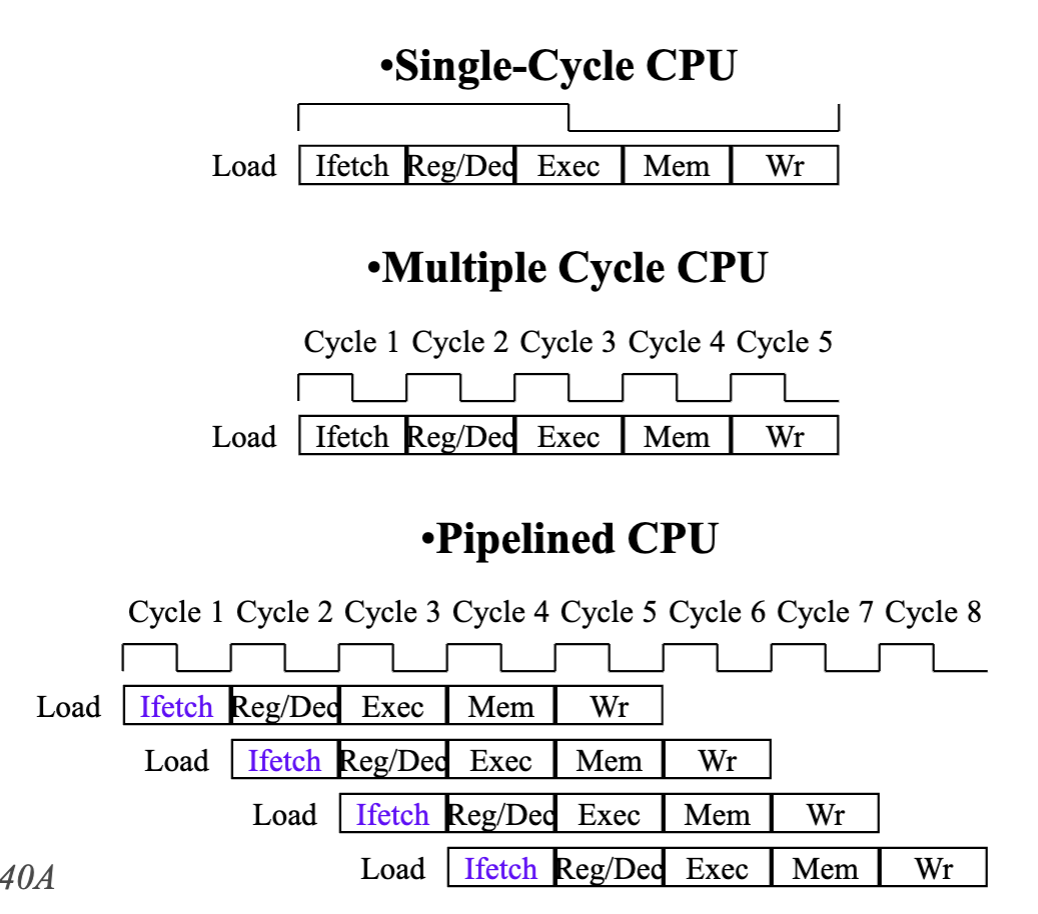
- Single-Cycle CPU - every instruction takes a cycle
- Multiple Cycle CPU - less time for shorter instructions
- Pipelined CPU - one instruction over multiple clock cycle, throughput increases since each stage starts when the resource is free and dependency considered, available to use
- requires separate jobs/stages
- requires separate resources
- achieves parallelism without replication
- improves throughput
- often increases single-task (e.g. instruction) latency
- pipeline efficiency (keeping the pipeline full) is critical to performance
5 steps of the MIPS Datapath (with multicycle pipeline)
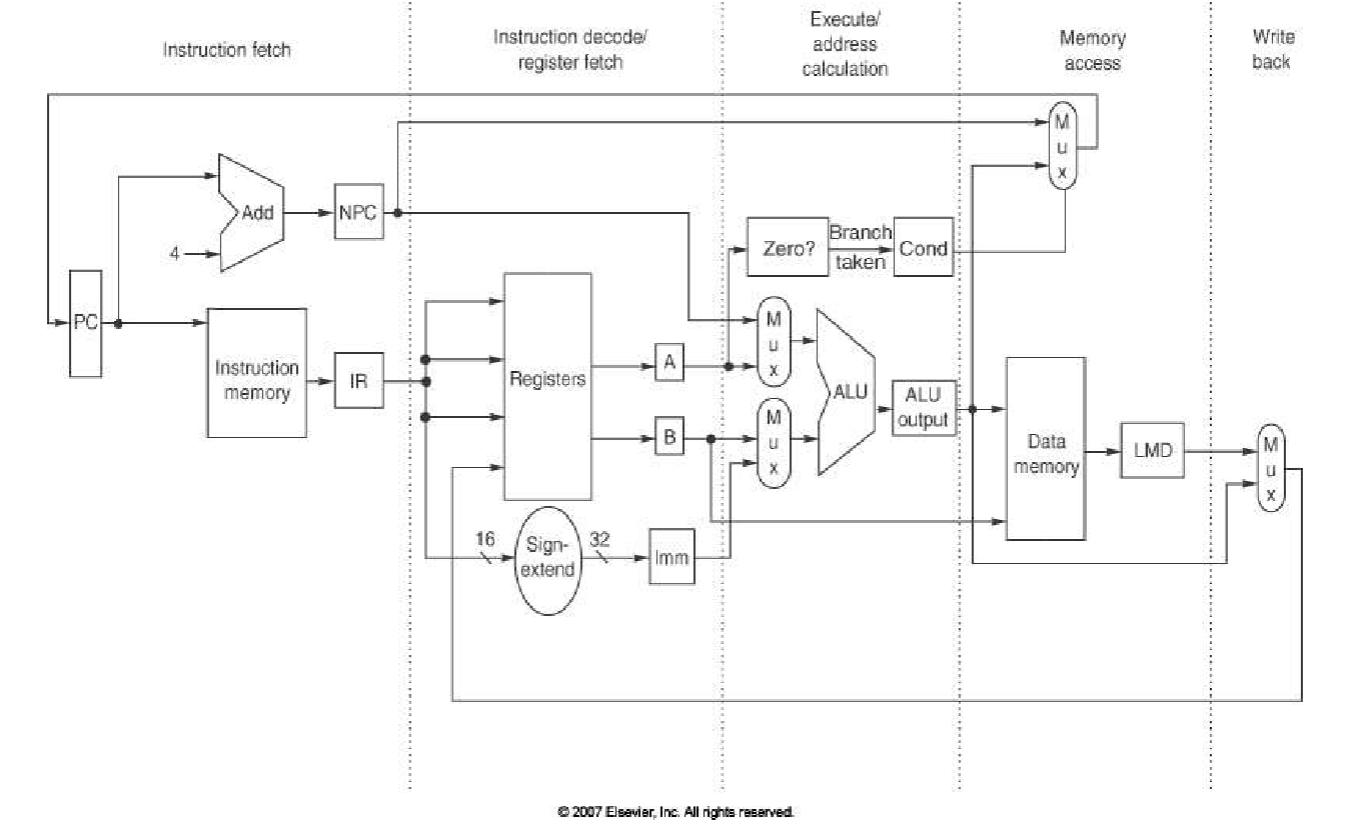
5 steps of MIPS Instruction
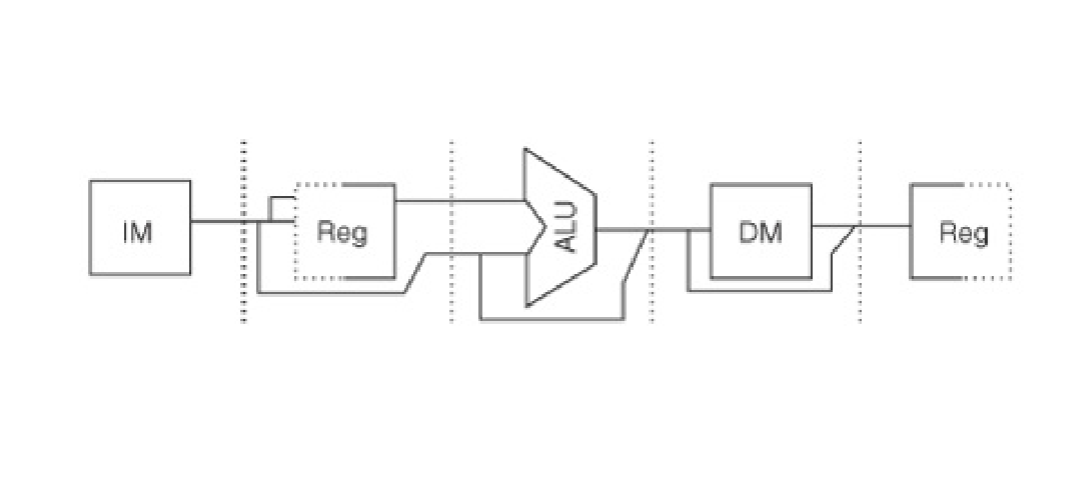 Note: IF → ID → EX → M → WB
Note: 2 regs stages isn’t going to conflict because one is reading (ID) and the other is writing (WB)
Note: two memories (IM, DM) doesn’t conflict (different caches, discussed later in class)
Note: IF → ID → EX → M → WB
Note: 2 regs stages isn’t going to conflict because one is reading (ID) and the other is writing (WB)
Note: two memories (IM, DM) doesn’t conflict (different caches, discussed later in class)
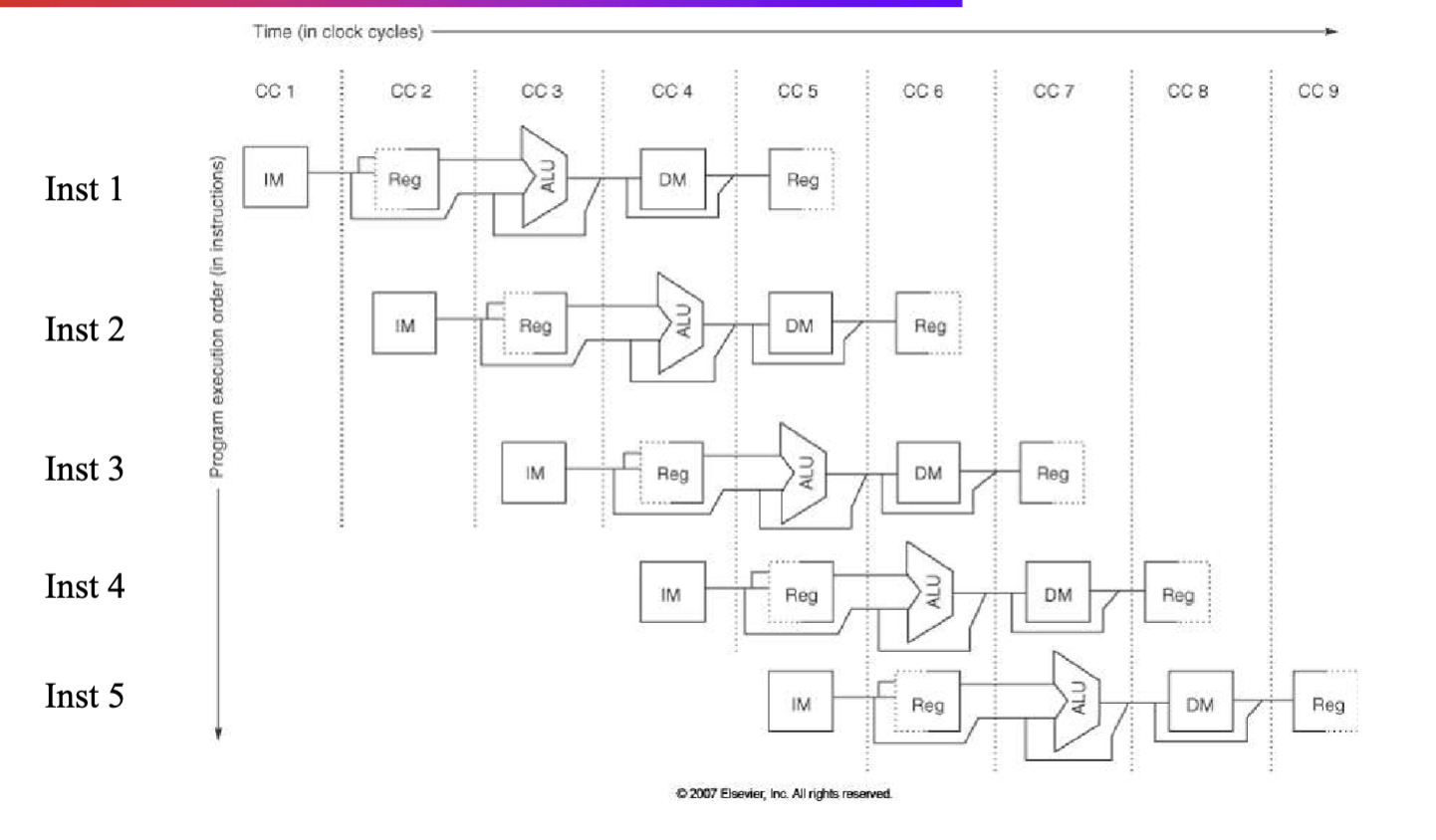
Visualizing Pipelining
Pipelined MIPS Datapath
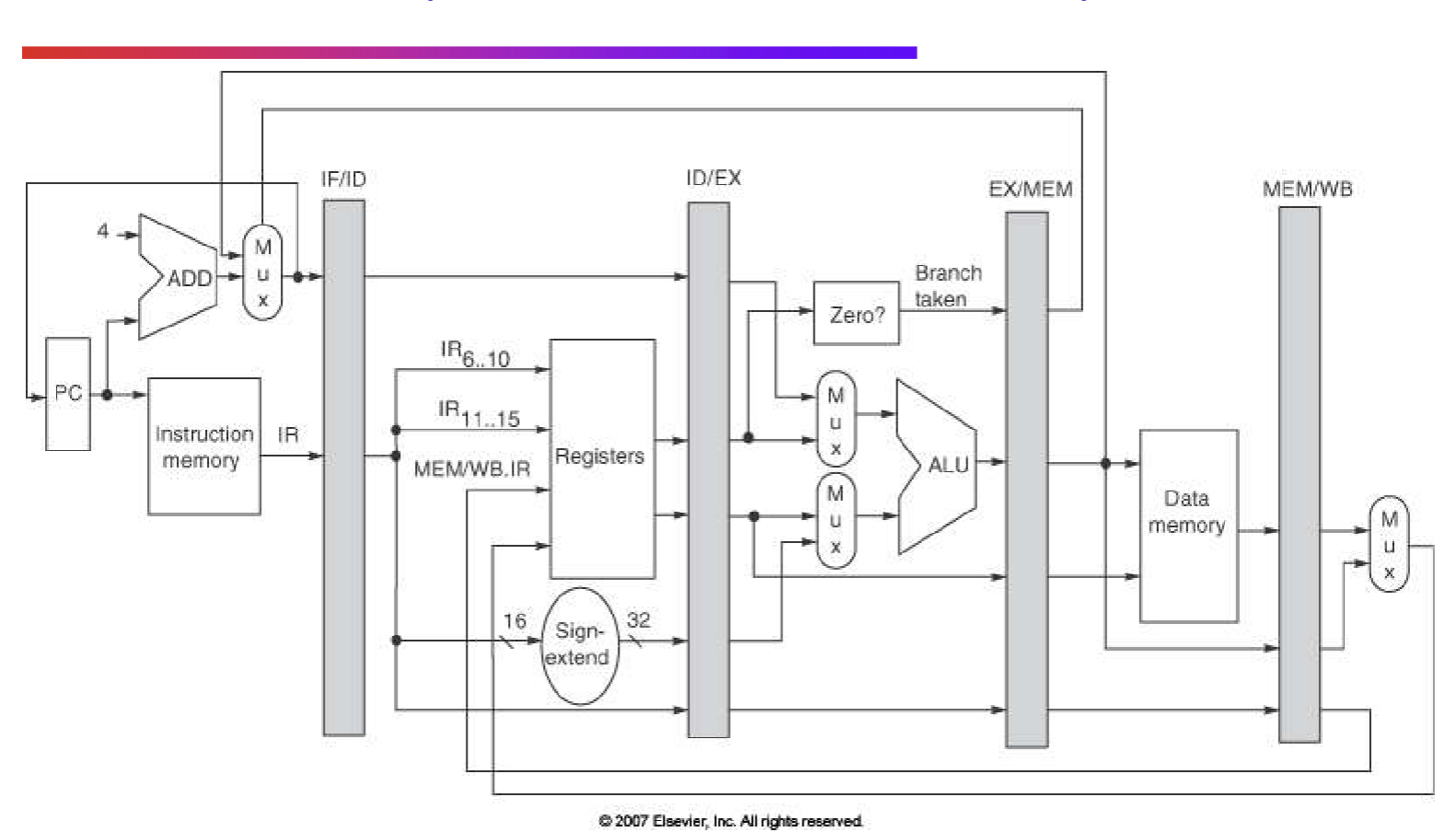 Note: big pipeline registers store information between stages. Since say a new instruction loads after current instruction, registers have to be cleared to load in next instruction → losing info
Note: big pipeline registers store information between stages. Since say a new instruction loads after current instruction, registers have to be cleared to load in next instruction → losing info
Pipeline Example
- addi R5, R1, #35
- add R6, R2, R1
- lw R8, 10000(R3) …
Pipeline Performance
- Optimal/ naive trade offs between diff processor types
| IC | CPI | CT | |
|---|---|---|---|
| single-cycles | = | 1.0 | longest instr. |
| multiple-cycle | = | higher (need more cycles per instr.) | lower (cycle span stages) |
| pipelined | = | ~1 (low stalls and large enough instructions approaches 1) | lower (cycle spans stages) |
- complexity has a cost
- e.g. latch overhead
- uneven stage latencies
- can’t always keep the pipeline full
- hazards - dependency between instructions
- branches
- hazards - dependency between instructions
Pipeline Hazards
- Limits to pipelining: Hazards prevent next instruction from executing during its designated clock cycle
- Structural Hazards: HW cannot support this combination of instructions
- Data Hazards: Instruction depends on result of prior instruction still in the pipeline
- Control hazards: Pipelining of branches and other instructions that change the PC
- Common solution is to stall the pipeline until the hazard is resolved, inserting one or more “bubbles” in the pipeline
Data Hazards
Data dependencies may result in data hazards!
- dependencies are a function of the code and independent of the HW
- Hazards are the result of the hardware
- E.g. a dependencies might not be a hazard if in the pipeline there isn’t a stage conflict!
Data Dependence
- Data hazards are caused by data dependences
- Data dependences, and thus data hazards, come in 3 flavors (not all of which apply to this pipeline)
- RAW (read-after-write) [true dep.]
- WAW (write-after-write) [output dep., false dep.]
- WAR (write-after-read) [anti dep., false dep.]
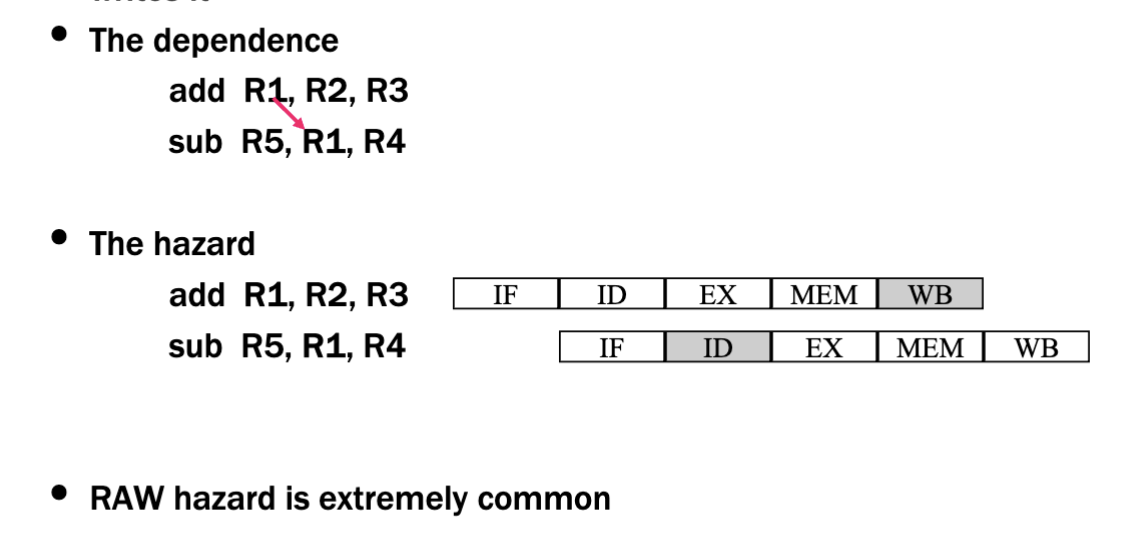
RAW Hazard
- Later instruction tries to read an operand before earlier instruction writes it
- True dependencies
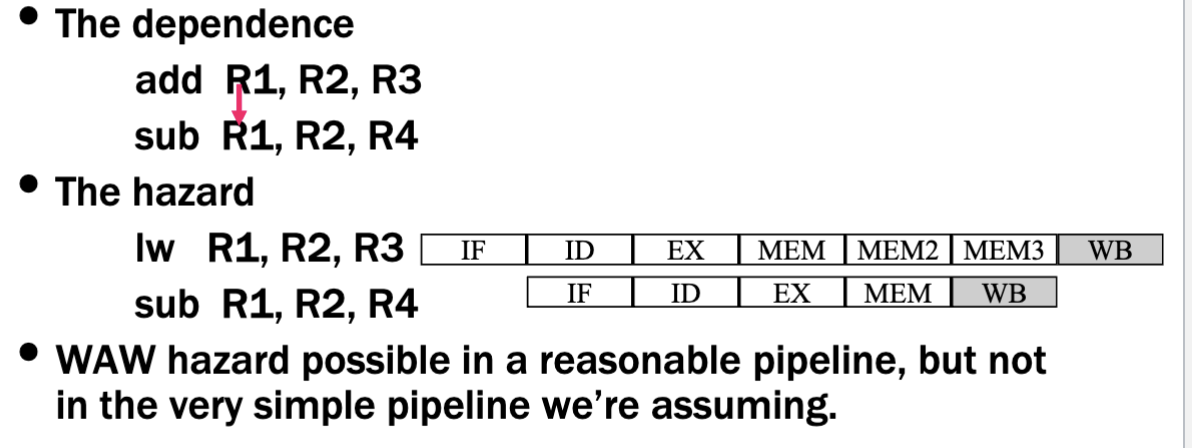
WAW Hazard
- Later instruction tries to write an operand before earlier instruction writes it
- False dependencies - not code issue, compiler issue (don’t put instructions that depend on each other next to each other) more artificial issue
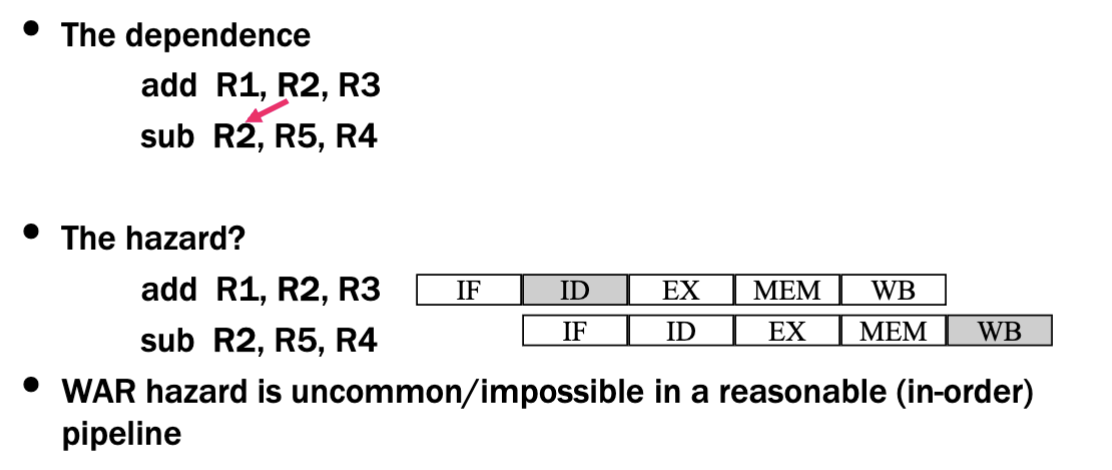
WAR Hazard
- later instruction tries to write an operand before earlier instruction reads it
- also false dependencies
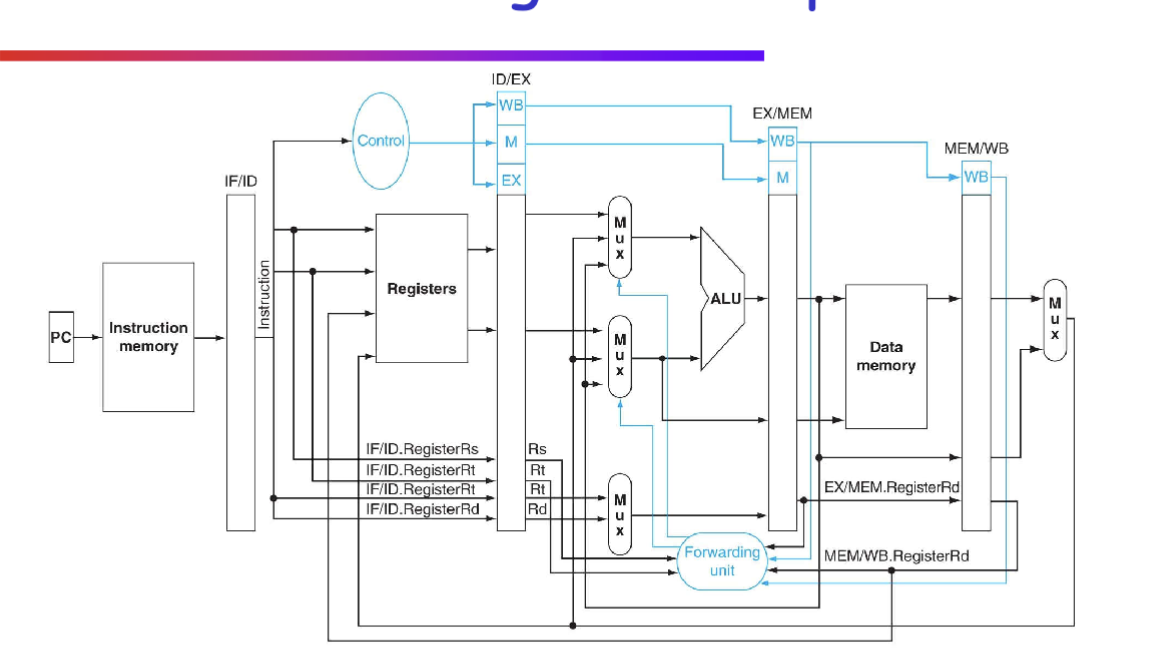
Dealing with Data Hazards through Forwarding